Postmortem of My Journey at Autodesk
Sometimes when you lose, you win.
As an SRE (Site Reliability Engineer), switching jobs is extremely risky - comparing it to a production change without any canary strategy or rollback option!😱 However, YOLO (you only live once), just embrace and enjoy the risks.
After joining Autodesk for 1y5m, the whole team was unfortunately impacted by layoff. Currently, I have already left the company and became a full-time parent.
Nonetheless, Autodesk is an incredible company with excellent benefits and professional colleagues. This post is a little retrospective in the form of a postmortem.

Timeline
I started my career as a Python developer in a startup in Shanghai, the engineering experience became a solid cornerstone for my SRE transition.
Then, I joined Ant Group, a leading Chinese fintech company, which was the largest unicorn in the world. Thanks to reliable co-worker and managers, I got promoted twice in 4 years and well compensated.
- 2017.03 ~ 2018.04: Python Software Engineer (Hypers)
- 2018.04 ~ 2023.10: Site Reliability Engineer (Ant Group)
- 2023.10 ~ 2025.04: Site Reliability Engineer (Autodesk)
Why did I join Autodesk?
Don’t Be The Best, Be The Only.
To seek better work-life balance (WLB) and build a more resilient career, I joined Autodesk in Shanghai and set three professional development goals:
- Site Reliability: Explore popular tech stacks, e.g. public cloud platforms
- Engineering: Launched an opensource project in part-time to enhance my engineering skills and avoid single point failure of my main career
- Communication Skills: Enhance English-speaking proficiency
P.S. Fun fact - at Autodesk, in addition to ORK, everyone is also encouraged to set up an Individual Development Plan (IDP), and the goals aren’t necessarily closely related to their daily job.
So, how was it?
It turned out that I successfully achieved most of my goals:
- ☑️ Site Reliability: Achieved AWS SysOps Administrator certification, which do help me perform better in my daily work.
- ☑️ Engineering: Launched an opensource project with users from 90+ countries.
- ☑️ Communication Skills: Enhanced ability to effectively collaborate in English-speaking environments
Lessons learned
The definition of SRE varies significantly across companies, including platform engineer, technical support, server reboot engineer, emotional support SRE…
I’ve experienced two distinct SRE models: At Ant Group, I was part of a centralized SRE team (~80 people) responsible for the SLOs of global payment services (~3000 people). In contrast, at Autodesk, I work as a dedicated SRE embedded within a specific product team (~15 people).
The two experiences have helped me gain a deep and broad understanding of achieving Service Level Object (SLO).
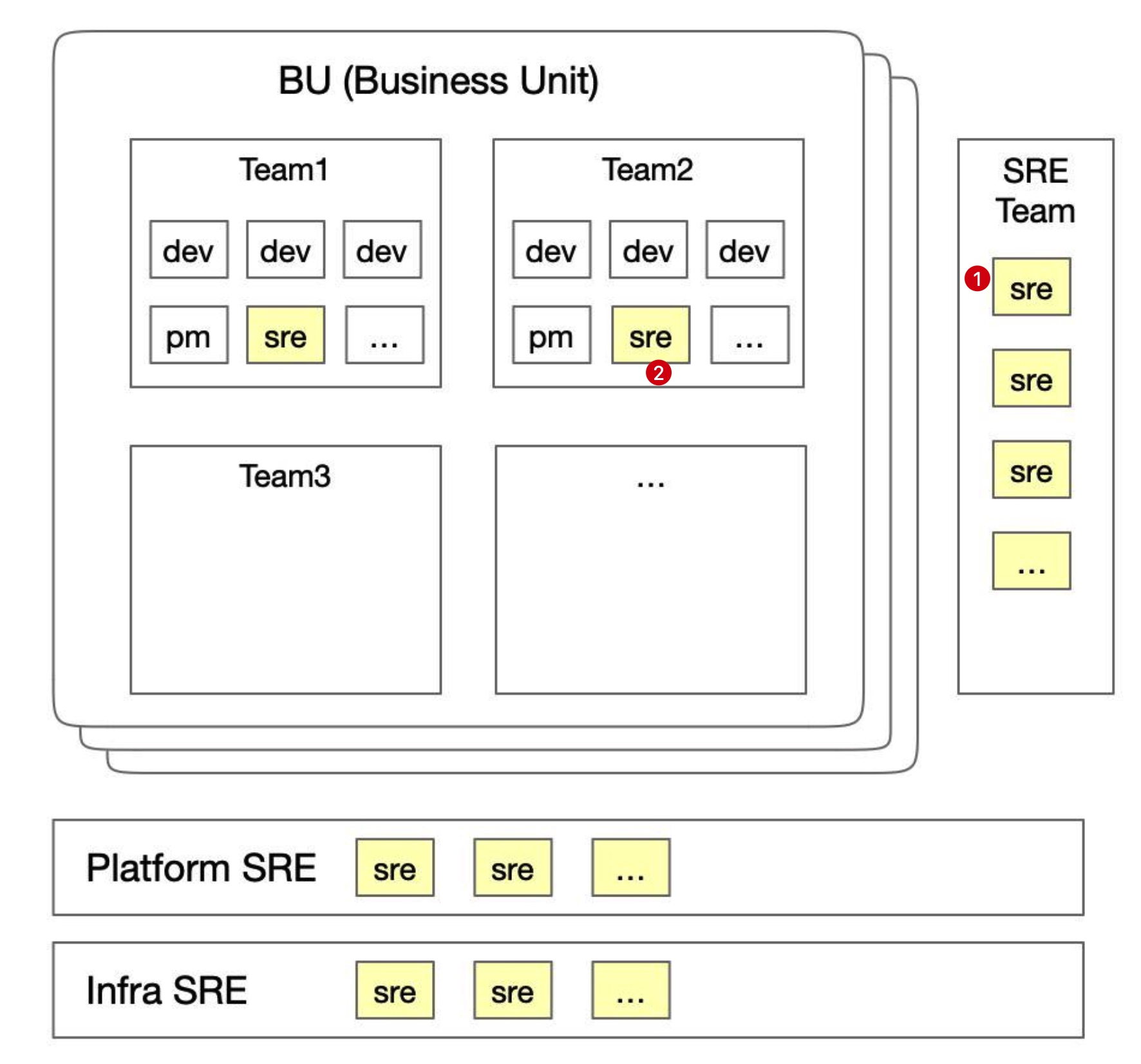
In Autodesk, as a dedicated SRE being directly responsible for the SLO target with limited resources, I’m facing more challenges. So I had to think globally and prioritize my time smartly.
In addition to daily tasks and toils, I invested 70% of my time on incident prevention, and 30% on incident detection and recovery.
Incident prevention (70%)
1. Changes
Simply focus on changes:
1.1 Code changes (deployment/config/infra/…)
A key distinction between SRE and Platform Engineer is the requirement of deep domain knowledge. After spending several months documenting business workflows through sequence diagrams, I began to actively participate in code reviews to identify and mitigate potential production risks at an early stage.
Here are two examples:
- During an application code review, I found a defect that the cache TTL (Time to Live) will be incorrectly reset every time on value update, which may causing the rate limiting not working as expected.
- In a terraform code change (traffic cutover), I recommended implementing AWS Route53 weighted routing to enable gradual traffic shifting (starting with 1% of traffic), significantly reducing the risk of service disruption during the cutover.
1.2 Dependency changes (resiliency test)
Service dependency failures are one of the leading causes of incidents. For example, when the database is hanging, most of the traffic of the service should be handled by the cache. However, due to unnecessary hard dependency on the database, the service is completely down.
To address this, I developed an HTTP(S) proxy tool that enables the team to perform resiliency tests and fire drills (chaos), helping identify and eliminate unnecessary hard dependencies.
1.3 Other changes
- Upstream traffic surge: using bi-week service reviews to monitor upstream traffic trend and ensure our rate-limiting and scaling policies are working as expected.
- …
2. Incident & issues
I have the habit of tracking all incidents and issues. Interestingly, after collecting and analyzing 40+ cases in the past year, it magically helped me identify key patterns in service reliability problems and shaped my next year’s OKRs. This also significantly impressed my manager during the yearly performance review.
Incident detection & recovery (30%)
End-to-end monitoring
While our monitoring system (SLO alerts and health checks) can detect incidents within one minute, identifying root causes remains challenging even for experienced engineers, resulting in high Mean Time To Recovery (MTTR).
To address this challenge, I implemented end-to-end Synthetic Monitoring with AWS CloudWatch Canaries. The synthetic monitoring simulates real user transactions and validates key steps throughout the service workflow. For instance, it even verifies the design file visualization process by checking cache loading status in DynamoDB.
This solution automatically output the failing step when an alert triggers, significantly improving our root cause analysis efficiency.
Action items
Incidents are inevitable, but not always negative; they provide opportunities to review and enhance our services.
Even though I was affected by layoffs, on the other side, this change has offered me the precious opportunity to become a full-time parent and give them a chance to live for myself 😊
The next thing for me is taking care of my newborn at least 12 months, I will be writing more on the topic so stay tuned!
