如何编写低耦合可维护的 Python 代码
经常听到一个论调:设计模式本质为弥补编程语言自身的缺陷,例如单例模式的存在,是因为 Java 本身不提供单例对象创建,而 Python 中原生的 import 就是 singleton 的天然实现。
但个人观点这句话仅看到了表象,设计模式初衷还是帮助我们编写更加优雅的代码,背后的目的与语言本身无关。
这篇文章以大型项目痛苦之源 Python 语言为例,通过近期工作中的两个实践案例,尝试分享如何通过常见设计模式,编写可扩展可维护代码的一点点经验。
背景
近期公司内部发起告警阈值托管项目,故名思义通过历史时序数据,自动学习并清洗合理的告警规则+阈值。解放运维人员双手的同时,通过程序自动化的方式保证更高的准确率/召回率。
为了规避智能算法黑盒的弊端:用户难以理解告警触发逻辑,进而一步无法调节业务预期 :(
所以项目初期针对不同类型的时序指标,基于人的专家经验,提炼了一系列告警规则模版,例如成功量下跌、成功量跌零、失败数上涨、历史新增异常等等)。
理想效果:用户输入一周预计告警个数后,清洗模块自动输出可理解的静态告警规则..
1. 阈值清洗流水线抽象 & 扩展
清洗模块代码落地的过程中,发现不同“模版”清洗的流程大同小异,无非 1)拉取历史数据,2)数据预处理,3)特征提取, 4)上下限阈值计算等。
自然而然地将整理清洗流程,抽象固定为 pipeline 基类,不同“告警模版”理论只需实现对应的「特征提取」逻辑即可,但如何进一步兼顾清洗流程的扩展性呢?
例如:
- 历史数据完整性检测:数据预处理前,检查拉取的历史数据,例如判断是否至少满足一天,否则中断流程
- 阈值结果人为干预:阈值完成清洗后,人工微调告警规则,例如调整夜间触发告警的持续时间
- 阈值持久化保存:阈值完成清洗后,进一步执行阈值的持久化(测试用例、实时服务等场景不需要)
- …
这时曾拜读的 tomcat 源码 Lifecycle 突然跃入脑中!
有没有可能将上述的“个性化”处理逻辑,以事件的方式动态注入至 pipeline 中,最终在不同阶段的“埋点”触发:
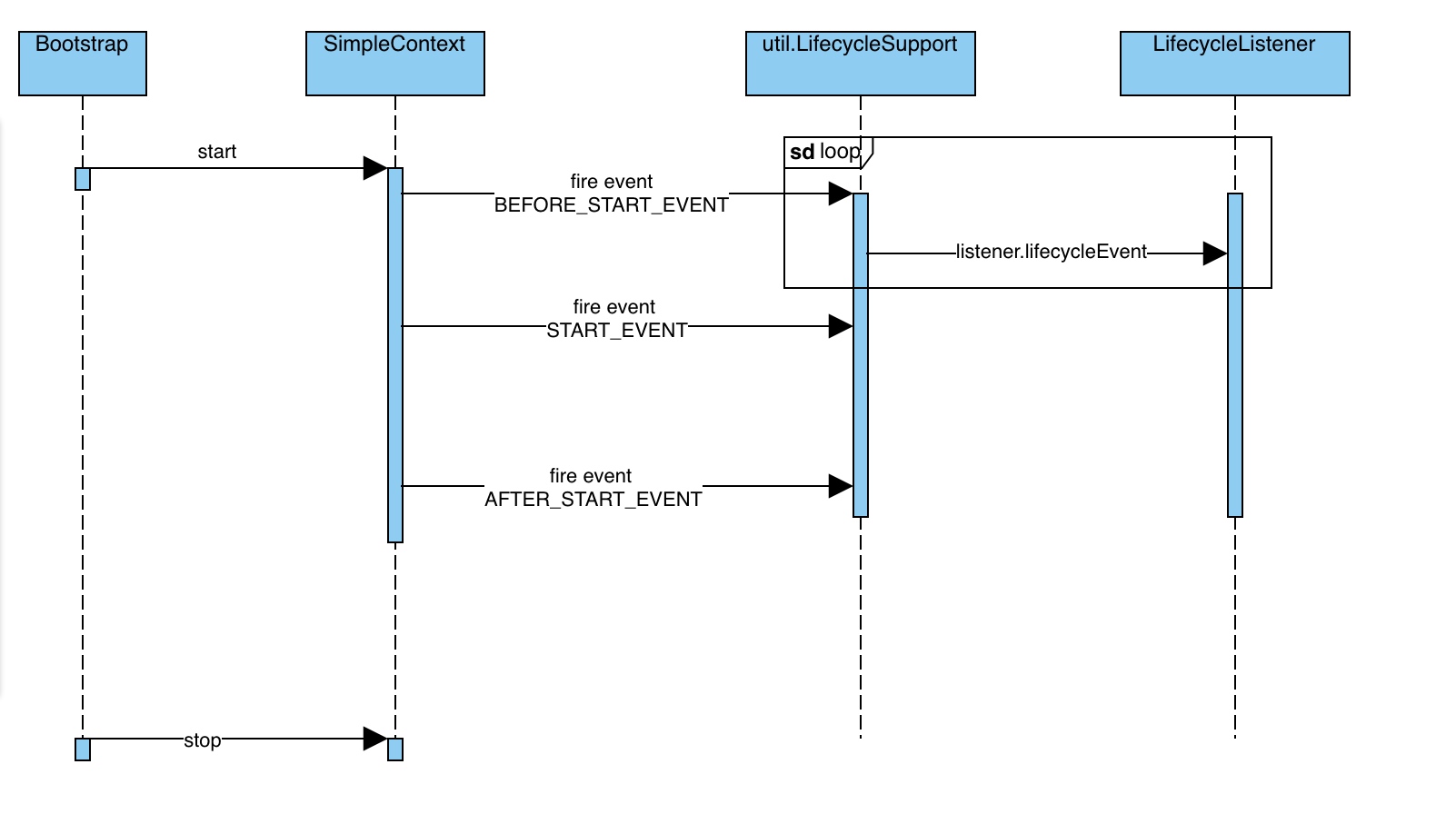
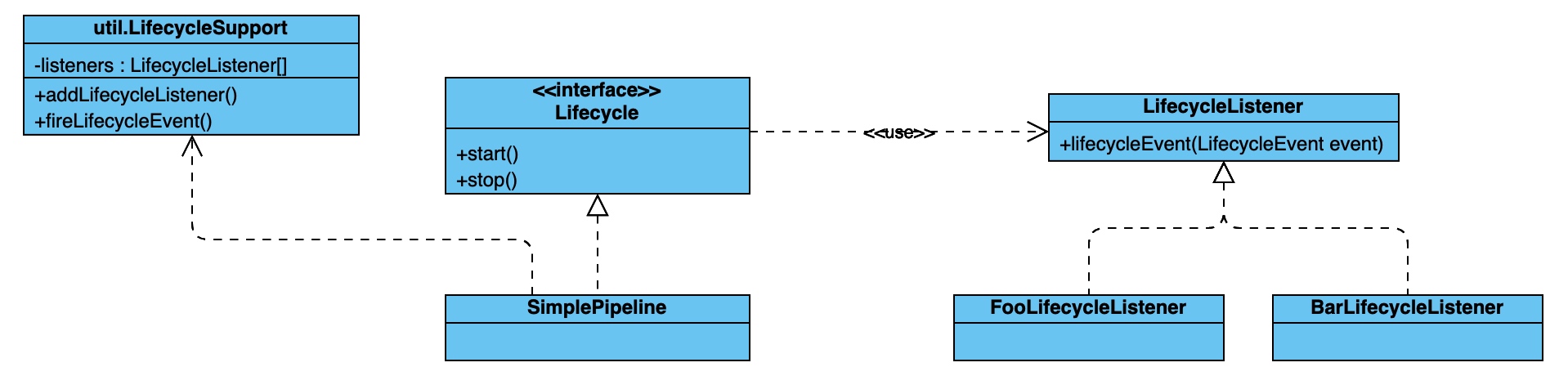
类图参考:
改造后的 pipeline 片段:
p.s. 完整代码参考:https://github.com/daya0576/python_design_patterns/blob/master/observers/pipeline.py#L7
from abc import ABC, abstractmethod
from observers.events import LifecycleListener
from observers.lifecycle import EventType, Lifecycle
from observers.utils import LifecycleSupport
class BasePipeline(Lifecycle, ABC):
def __init__(self):
self.lifecycle = LifecycleSupport(self)
@abstractmethod
def _do_load_data(self):
...
@abstractmethod
def _do_process(self):
...
def start(self):
self.lifecycle.fire_lifecycle_listener(EventType.START_EVENT)
def stop(self):
self.lifecycle.fire_lifecycle_listener(EventType.STOP_EVENT)
def add_listener(self, listener: LifecycleListener):
self.lifecycle.add_lifecycle_listener(listener)
def process(self):
print("Start..")
self.start()
self._do_load_data()
self._do_process()
self.stop()
print("Stop")
class SimplePipeline(BasePipeline):
def _do_load_data(self):
print("Do load data")
def _do_process(self):
print("Do process")
最终执行效果:
pipeline = SimplePipeline()
pipeline.add_listener(FooLifecycleListener())
pipeline.add_listener(BarLifecycleListener())
pipeline.process()
# ---------------------
# > Start..
# > Foo event fired...
# > Do load data
# > Do process
# > Bar event fired...
# > Stop
如上 Lifecycle demo,本质上为“观察者设计模式”的一种实现。清爽解耦的代码,只有在自由灵活新增代码逻辑的时候,才能懂得它的好。
2. 告警规则覆盖策略
上文清洗逻辑成功落地后,如何针对不同监控项,覆盖正确的「告警规则模版」成为了新的难题。
不难理解若监控包含耗时/失败数指标,直接覆盖耗时上涨/失败数上涨告警规则即可。
但假如判断有误,针对失败量监控覆盖「跌零规则模版」,最终告警显示 PROCESS_FAIL 错误码 10m 跌零,请立即处理,那真的要笑掉大牙了。
那除了人工标定,还有其他“策略”可以自动分析吗?
部分解法:
- 指标类型:例如明确的失败量、耗时等指标
- 故障等级:若关联 P1P2 故障等极的规则,必然是业务量级监控
- 告警规则:甚至可以分析现有监控告警规则,判断量级下降 or 上升代表异常。
- …
模拟如上不同场景的策略,是否可以编写直白的伪代码?
success_count_risk = DefaultSuccessCountRisk()
time_cost_risk = DefaultTimecostRisk()
strategies = [
# 覆盖 P1P2 业务,SPM 监控类型,成功量指标的风险:成功量下跌/跌零
P1P2(High(SPM(risk))),
# 覆盖 P3P4 业务,白天时间段,耗时指标的风险
P3P4(Daytime(time_cost_risk)),
]
参考装饰器设计模式,一个更加恰当咖啡制作的例子,通过不同类的灵活“装饰”,最终获取这杯咖啡的描述与价格:
// 来一杯 Espresso
beverage = Espresso()
print(beverage)
// Espresso$1.99
// 来一杯调料为豆浆,摩卡,奶泡的 HouseBlend 咖啡
beverage = HouseBlend()
beverage = Soy(Mocha(Whip(beverage)))
print(beverage)
// HouseBlend, Whip, Mocha, Soy$1.39
类图参考:
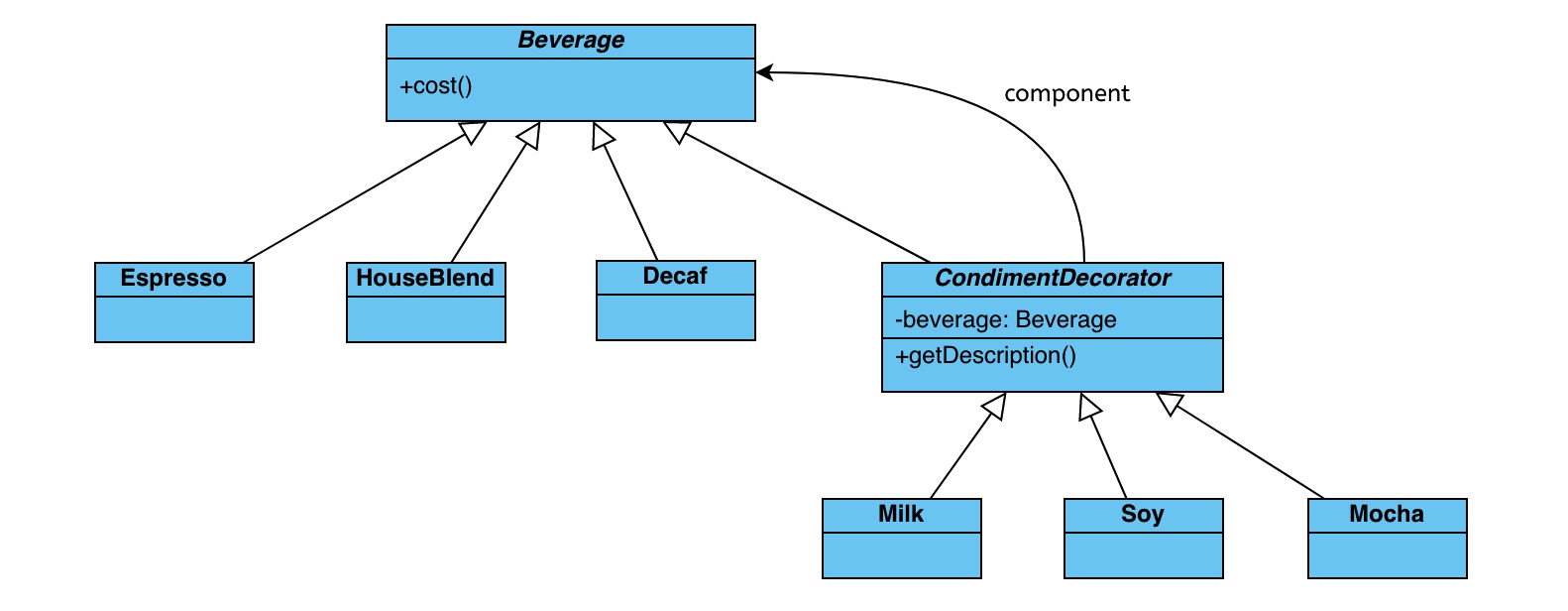
代码参考:https://github.com/daya0576/python_design_patterns/blob/master/wrapper/decorator.py
总结
上文两个实战案例,对应观察者模式(Observer)、装饰器模式(Wrapper)两种设计模式,本质上都是“开闭原则”的一种最佳实践:对于扩展,类应该是「开放」的;对于修改,类应该是「封闭」的。
简而言之,编写代码时需要区分程序中的 易变 和 稳定 部分。对于未来可预见的新增需求,尽可能不修改原有代码,而是通过简单组合的方式快速扩展。
参考:
- Python 不需要设计模式?:https://changchen.me/blog/20201114/why-u-dont-need-design-pattern-in-python/
- 《深入剖析 Tomcat》:https://book.douban.com/subject/10426640/
- 《Head First 设计模式》学习笔记:https://changchen.me/blog/20200613/design-pattern/