重读 Google SLO 小记 | 智能告警之殇
the basic foundations of SRE include SLOs, monitoring, alerting, toil reduction, and simplicity.
最近学了个新的单词:cornerstone,而制定 SLOs,配置监控,以及告警应急可以说是 SRE 的基石。过去几年个人工作也与可用性监控相爱相杀。最近工作遇到一些瓶颈,周末重温 Google SLO 文化《Google’s Site Reliability Workbook》,期望激发一些新的灵感~

TOC
一、为什么我们需要定义 SLO?
SLOs are key to making data-driven decisions about reliability
众所周知,一味的追求 100% 可用率不是一个明智的决定。只有制定研发、测试、SRE一致认同的可用性目标后,才有可能实时量化风险,基于数据驱动告警应急&影响变更,最终管理好风险。
一个反例为公司内部的智能告警,为什么一直用户口碑不佳?一方面因为纯算法黑盒的不可解释性以及业务特征缺失,但更致命的原因在于缺少用户输入(各个服务重要程度)。如果针对所有服务套用相同检测逻辑,必然极难保证异常检测召回率的前提下,不断提升准确率。
二、如何定义 SLIs?
The easiest way to get started with setting SLIs is to abstract your system into a few common types of components
首先将线上系统抽象分类后,分别设置 SLIs:
- 用户/商户同步请求
- 成功率/延迟
- Quality:例如业务降级后,HTTP 接口正常响应 200,但业务返回“请稍后重试”,也应该被识别为异常(影响用户体验)。
- 内部定时/异步任务
- Freshness:数据实时性
- Correctness:数据正确性
- Coverage
- 存储系统
- Durability:数据记录可成功读取的比例。
- …
三、如何实现 SLIs?
1. HTTP 状态码
we base the response success on the HTTP status code. 5XX responses count against SLO, while all other requests are considered successful.
文中简单以 http 接口的 5xx 判断请求是否成功。
公司内部通常以业务错误码作为外部请求成功/失败判断标准,e.g. PROCESS_FAIL, UNKNOWN_EXCEPTION。
它们又被称为“灰色错误码”… 也就是说当返回给用户PROCESS_FAIL处理失败时,有可能是内部代码 npe 导致,也可能是用户余额不足,无法代表系统是否真实可用。同时受上游/下游外部影响,极大的影响告警准确率。
- 一种思路为修改错误码模型,带上可用性属性(am I f**ked up?),但此类“规范”如果没有与监控系统原生打通,随着时间推移很容易“腐化”。
- 另一种思路为根因错误码识别,同样监控入口错误码,但将根因错误码塞入请求上下文,透传至入口综合判断业务是否可用(剔除用户余额不足等噪音场景)。但根因错误码识别(强弱依赖)又是一个新的课题。
个人倾向第一种思路为上策:分布式系统中每个应用需决策并透出这笔请求是否会影响用户(SLO-impacting error),通过这一层风险抽象,最终统一复用一份告警规则
2. 黑盒测试
SLIs can use one or more of the following sources
- Application server logs
- Load balancer monitoring(文中主要指 HTTP 状态码,同时最接近用户感受)
- Black-box monitoring
- Client-side instrumentation
日常监控通常基于日志统计(白盒监控),数据来源是否过于单一?有没有可能发挥黑盒监控测试的重要性?
3. SLIs 的几种高级玩法
Once you have a healthy and mature SLO and error budget culture, you can continue to improve and refine how you measure and discuss the reliability of your services.
- 基于用户行为的满意度量化(Modeling User Journeys):以在线购物场景为例,用户关键路径为 1)搜索商品 -》 2)加入购物车 -》3)下单购买,所以有没有可能对应日志事件 join 聚合后,生成一个全新的 SLIs 改善客户体验。本质上与链路监控的传递比检测异曲同工,通过流量漏洞模型在不影响准确率的同时,提升召回率。但提供了新的思路:除了前置的流量染色,还能通过单号自动聚合(后计算)生成流量漏斗指标?
- 强依赖建模(Modeling Dependencies):不难理解下游 SLOs 制定一定要要比上游严格,例如业务应用服务 SLO 为 99.9% 下游依赖的单点 DB 需要设置为 99.99% 进行风险管理。同时建设缓存、异步处理、降级等保护手段。
4. 监控的监控
At Google, we test our monitoring and alerting using a domain-specific language that allows us to create synthetic time series. We then write assertions based upon the values in a derived time series, or the firing status and label presence of specific alerts.
关于监控的监控,思路比较类似:
- 建设全自动的回归流程,利用 mock 数据以及真实故障 case,每日回归验证保鲜。
四、如何基于SLO报警?
1. 告警事件度量指标
首先理解评判告警事件好坏的四个指标:
- Precision:准确率
- Recall:召回率(故障漏过未告警)
- Detection time:投递延迟
- Reset time:告警重置时长
2. 告警配置最佳实践
假设 SLO 为 99.9%,以下为几种预警方式的优劣分析(最佳实践推演):
1)目标错误率≥SLO阈值
只要最近十分钟 slo 消耗破线就进行预警:ratio_rate10m{job="myjob"} >= 0.001
- 好处:非常灵敏保证召回率
- 缺点:准确率低,最坏情况下一天最多收到 144 个告警,但整体 SLO 符合预期。
2)警报窗口增加
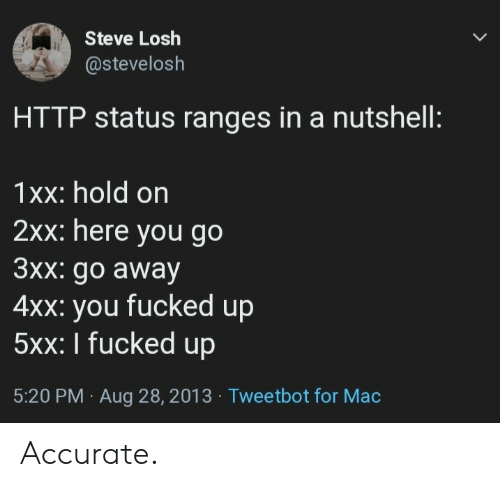
十分钟 -> 36小时,SLO 破线才告警:ratio_rate36h{job="myjob"} > 0.001
- 优点:极大提高了准确率
- 缺点:计算窗口过大.. 一是浪费计算存储资源,二是上文提到的第四个指标(Reset time)非常不理想。例如下图第10分钟时,服务 100% 不可用 5 分钟(蓝线),但报警会持续超过阈值 36 小时(绿线)
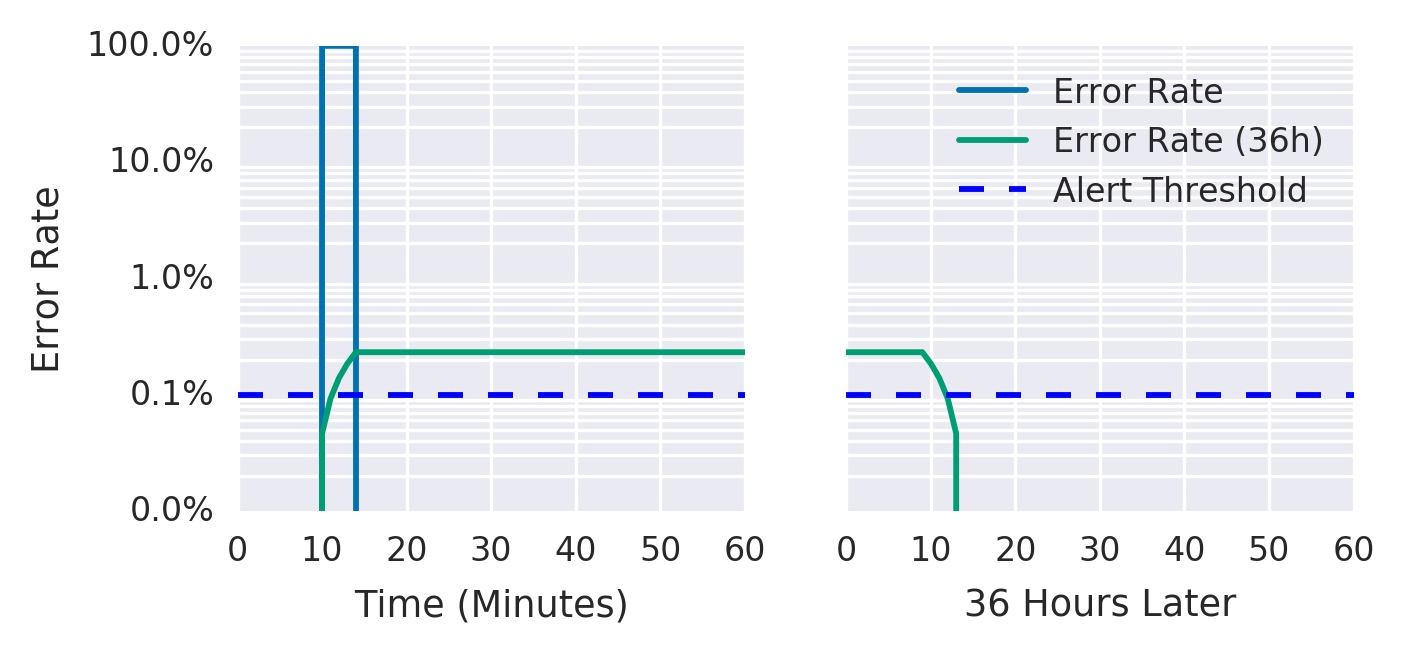
3)递增警报持续时间
连续 N 分钟大于某个阈值(any -> all):ratio_rate1m{job="myjob"} > 0.001 for: 1h
- 优点:准确率更高
- 缺点:召回率上存在一定缺陷(定时循环消耗 slo 但很快恢复),例如下图持续每五分钟产生一波 100% 不可用,但永远不会告警。
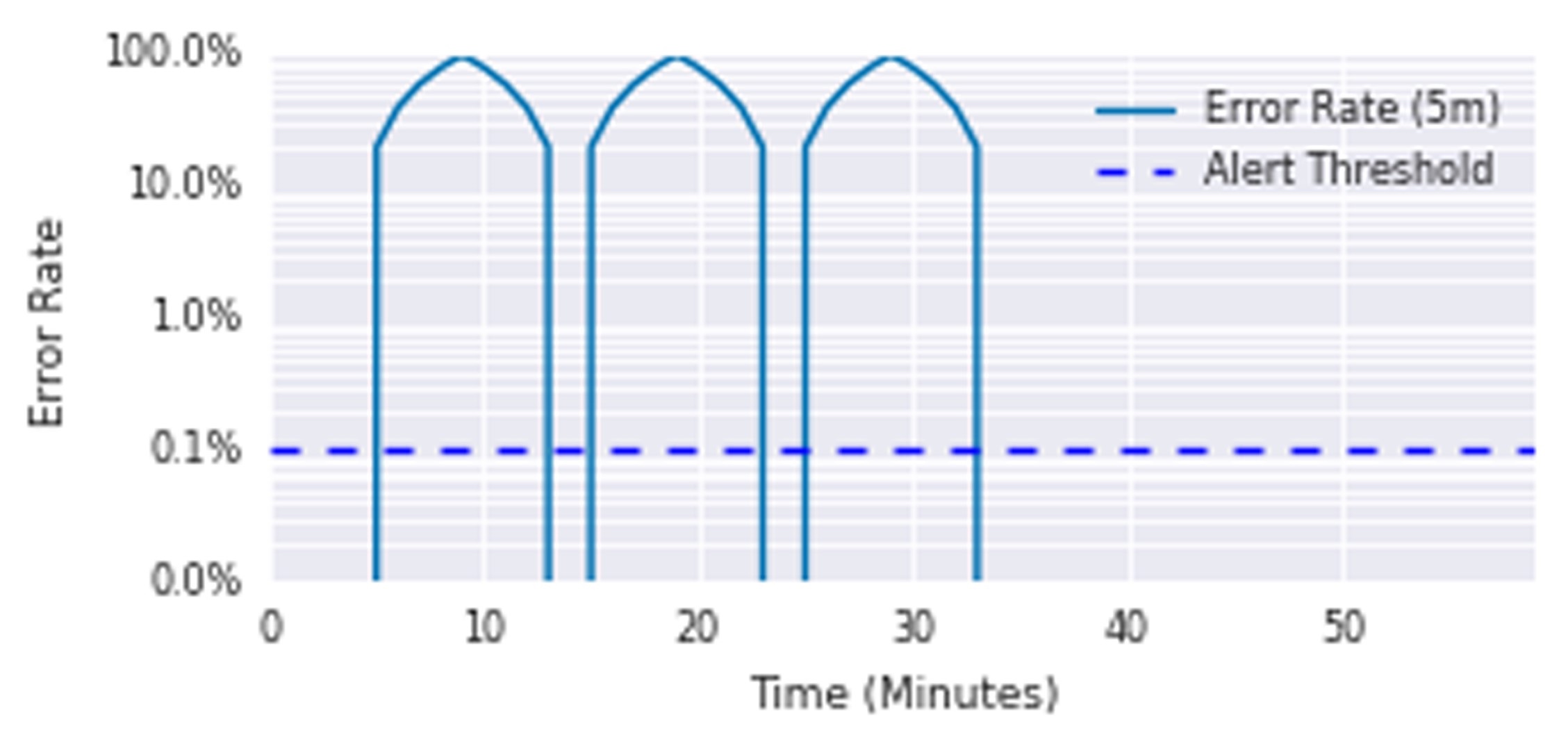
4)消耗速率警报 - burning rate
为了避免上几个方案,手动设置检测窗口的窘境,引入 burn rate 燃烧速率的概念。
例如下图,假设 SLO 为 99.9%(统计窗口为一个月 30 天):
- 如果燃烧速率为 1,则正好一个月消耗完 error budget
- 如果燃烧速率为 10(橙色),3 天(30 / 10)就会消耗完
新的告警规则:一小时内花费30天错误预算的5%:job:slo_errors_per_request:ratio_rate1h{job="myjob"} > 36 * 0.001
规则中 36 系数是如何的得出的呢?
// 当 Burning Rate 为 1 时
0.1% = 30x24h x Burning Rate 1 x Burning Speed
// 一小时内花费30天错误预算的5%
0.1% * 5% = 1h x Burning Rate B x Burning Speed
// 计算:
Burning Rate B = 30 x 24 x 5% = 36
- 优点:precision 精度相比上一步
连续 N 分钟的阈值配置 大幅提升 - 缺点:
- recall:存在问题易漏漏洞,假设 burn rate 保持在 35,会在 20.5 小时内烧完 30 天的错误预算。
- Reset time:最坏 58 分钟的 Reset time 依旧过长
5)多个消耗速率警报:
一小时内消耗2%的预算 or 六小时内消耗5%的预算:ratio_rate1h{job="myjob"} > (14.4*0.001) or ratio_rate6h{job="myjob"} > (6*0.001)
告警分级:
- 阈值 窗口 燃烧率 告警手段
- 2% 1小时 14.4 呼叫
- 5% 6小时 6 呼叫
- 10% 3天 1 工单
虽然解决上一个方案 recall 召回率的漏洞的同时,新引入告警分级,但还存在两个问题:
- reset time:三天的告警重置窗口(持续预警)
- 规则为或关系,可能导致事件重复产生与投递
6)多窗口,多消耗率警报
We can enhance the multi-burn-rate alerts in iteration 5 to notify us only when we’re still actively burning through the budget
5min & 60m 的窗口同时破线,才触发预警:“多个消耗速率警报”的升级版,「短窗口」通过 burning rate 保证 precision&recall,「长窗口」进一步保证 recall 的同时,帮助判断故障是否恢复,完美解决 reset time 的问题。
ratio_rate1h{job="myjob"} > (14.4*0.001)
and
ratio_rate5m{job="myjob"} > (14.4*0.001)
例如下图仅红色区域触发预警事件:
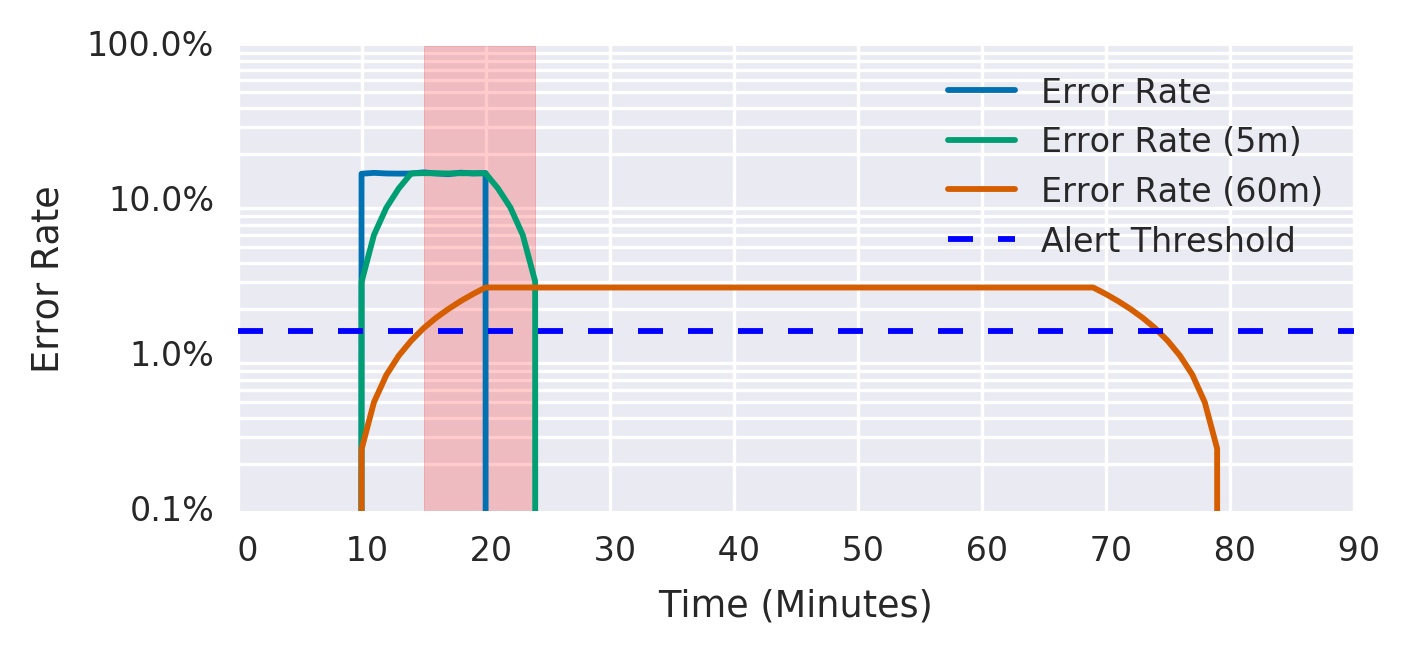
P.S. 困惑与成功率的区别???e.g. 最近五分钟平均成功率<90% && 最近1h平均成功率 < 99% 理论上等同,但 burn rate 优势在于仅用一个阈值:36,而成功率还要重新换算,个人理解。
P.S. 关于小流量的问题,文中提到几种解决思路:
- 人为模拟流量(黑盒测试)
- 多个小服务合并为大服务进行统一监控
- 降低 SLO(或者说增大检测窗口-根据当前实时流量自动计算)
THE END
回到现实,由于公司金融业务的特殊性(最高五个九可用率指标,要求一分钟发现,五分钟定位,十分钟恢复),SLO 文化是否无法适用?
但仔细一想,两者并不矛盾,所谓“一分钟发现”完全可使用「多窗口,多消耗率警报」替换:线上环境将「短窗口」从 5min 缩短为 1min;灰度环境通过「长窗口」的错误预算消耗检测,甚至增强问题发现能力。
问题在于:监控系统未按业务重要程度(e.g. SLO目标)科学自动设置预警。甚至针对非核心业务,用户手动配置一笔失败即告警的案例也屡见不鲜。
而 SLO 文化指引的缺失,更根本的原因在于:当前系统无法精确回答用户的一笔请求是否可用(SLO-impacting error),文中并没有做过多解答。希望有一天,针对可用性监控,所有业务系统的下单支付服务,也能像 http 接口一样,通过 5xx 即判断是否影响用户。。