Henry Z's blog
git clone 大提速
不管是工作还是学习中,相信你经常遇到这要的窘境:执行 git clone <url> 之后,不管是因为网速还是仓库过大,等你带薪拉屎结束,命令行还是龟速前行。
这篇博客简单分享几个提速小技巧⚡️⚡️⚡️
git clone 大提速
1. 设置 proxy
如果在大陆境内,可以暴力为终端配置代理端口:
export all_proxy=socks5://127.0.0.1:13659
2. 减小 clone 的大小
强烈推荐先阅读博主 18 年的一篇文章:《Git Internal (初探 git 的内部实现)》,了解 git 底层的数据结构:
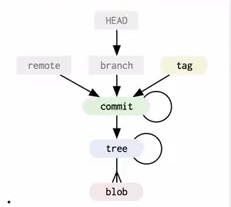
因此绝大部分情况时候没有必要获取仓库完整的历史(所有 commit 对应的无意义文件,i.e. blob)
下面三个参数可以按需使用:
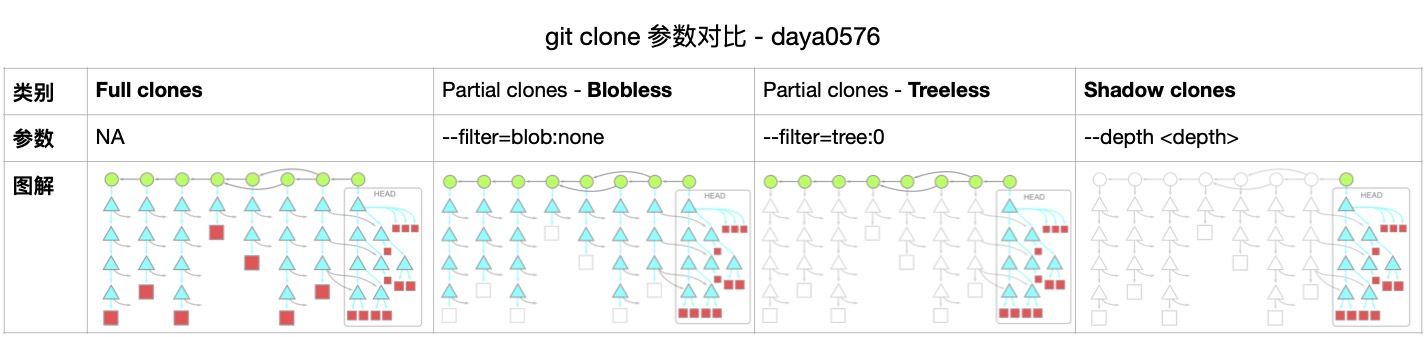
速度对比测试&说明
以 git@github.com:JetBrains/jdk8u_hotspot.git 为例,进行性能测试对比(未取平均值,仅供参考)
# 1)Full clones: `gcl <url>`
# 无参数执行完整 clone, 耗时最久.. 达到了夸张的 40 分钟 :(
17.79s user 8.67s system 1% cpu 39:31.18 total
# 2)Blobless clones:`--filter=blob:none`
# 只下载 commits & trees,尽可能保留历史记录的同时,避免加载隐藏在历史 commit 中的大文件
# 仅在执行 `git checkout` 时下载该 commit 对应的所有文件(blob)
3.62s user 2.32s system 1% cpu 9:18.32 total
# 3)Treeless clones:`--filter=tree:0`
# 如果有些 repo 历史过于悠久,也可以选择不加载 trees,仅保留 commits 历史
# 速度提升的同时,相对于 Blobless clones,存在大量局限性:
# 例如执行 `git merge-base` 或者 `git log`时不会触发数据的自动加载,
# 而 `git log -- <path>` 则会触发几乎每个 commit 的数据下载。
1.69s user 1.09s system 1% cpu 2:55.05 total
# 4)Shallow clones: `gcl --depth 1 <url>`
# 虽然快,但会,甚至在即用即拋的
1.06s user 0.80s system 2% cpu 1:26.68 total
总结
日常开发推荐 2)Blobless clones,兼顾性能与信息完整性。
3)Treeless clones 仅适用于例如即用即拋的自动化单元测试,或者本地的编译打包。 ⚠️ 不推荐 4)Shallow clones,存在描述信息丢失或错乱的可能,弊大于利。