Henry Z's blog
《Java 8 实战》读书笔记
时光飞逝,还记得大二开始接触 java 时,那时主流的是 jdk1.6 与 eclipse 的天下。没想到转眼间 java8 也发布快六年了,其中 Lambda、方法引用、stream 这些新特性,每次看到都云里来雾里去。正好拜读一下《Java 8 实战》这本书一探究竟~
p.s. 本文更多的是个人的笔记,完整代码请参考这个 repo: https://github.com/daya0576/java8_practice
第一部分:基础知识
第一章:Why java8
- Stream API:灵感源自 linux 命令的管道流(|) -> 好处:天然的并行(执行的时候分块)
- 函数式编程:方法引用 -> lambda
第二章:通过行为参数化传递代码
了解过「策略设计模式」的同学,都知道将「行为」作为参数,可以增加代码的灵活性与可读性,但代码看上去还是有一丝累赘🤔 …
参考《在 java & python 中,如何优雅的筛选一堆苹果》
第三章:lambda 表达式
基本语法如下:
(Apple a1, Apple a2) -> a1.getWeight().compareTo(a2.getWeight());
主要分为三部分:
- **参数:**两个 Apple
- **箭头:**将「参数列表」与 「Lambda 主体」区分开
- **主体:**比较两个苹果的重量(注意控制流语句需用大括号包围:例如
return "Hello" + i)
使用场景
函数式接口? 原名叫做 functional interface,为只有一个抽象方法的接口。
java8 还专门给抽象方法 @FunctionalInterface 注解,在编译阶段做检查。
举个例子:
// 官方的 Runnable 接口
@FunctionalInterface
public interface Runnable {
public abstract void run();
}
public static void main(String[] args) {
Runnable r1 = () -> System.out.println("Hello World");
r1.run();
}
// 最终输出 Hello World
函数式接口
java.util.function 中几个函数式的接口:
- Runnable(
()->void) - Predict(
T->boolean) -> 输入一个参数,返回 boolean,用于例如列表中元素的筛选 - Compare(
(U,T)->R) -> 输入两个参数,返回 boolean,用于排序 - Consumer(
T->void) -> 返回 void,用于例如打印一个列表中的所有元素 和 Runnable的区别??Runnable 是没有参数的 - Supplier(
()->T): 用于实例化多个对象 - Function(
T->R) -> 返回任意泛型的结果,例如用于获取一堆苹果对应的重量
方法引用
以下两种写法是等价的:
// lambda
inventory.sort((Apple a1, Apple a2) -> a1.getWeight().compareTo(a2.getWeight()));
// 引用
inventory.sort(comparing(Apple::getWeight));
引用又分为三种:
- 静态方法,e.g. Integer::parseInt
- 类型 - 实例方法,e.g. String::length
- 实例对象 - 实例方法,e.g. expensiveTransaction::getValue
谓词复合
可以将多个 lambda 通过 and/or/negative 关联起来,例如筛选出又红又大的苹果:
Predicate<Apple> greenApplePredict = (Apple apple) -> "green".equals(apple.getColor());
Predicate<Apple> predict = greenApplePredict.and(Apple::isHeavyApple);
函数组合
利用 andThen 和 compose 两个默认方法,将函数组合成自定义的 pipeline
// g(f(x))
Function<Integer, Integer> f1 = x -> x + 1;
Function<Integer, Integer> g1 = x -> x * 2;
Function<Integer, Integer> h1 = f1.andThen(g1).andThen(f1);
int result1 = h1.apply(1);
System.out.println(result1);
// f(g(x))
Function<Integer, Integer> f2 = x -> x + 1;
Function<Integer, Integer> g2 = x -> x * 2;
Function<Integer, Integer> h2 = f2.compose(g2);
int result2 = h2.apply(1);
System.out.println(result2);
第四章:引入流 & 使用流
以前以为 java 中的流只是为了让代码看起来更加简洁优雅,但另一个非常重要的优势在于自动的多核并行处理,提升性能,同时不用再担心如何处理线程与锁(在书的第七章中会重点介绍)。
⚠️注意:stream 与 python 中的 generator 类似,产生后只能被消费一次。
Stream API 总共有几种呢?
一、筛选:
- filter
- distinct
- limit
- skip: 跳过前 n 个元素
二、映射:
- map
- flatMap: 将多个 list 直接打平
flatMap 的例子:
List<String> words = Arrays.asList("hello", "world");
List<String> wordsParsed = words.stream()
.map(word->word.split(""))
.flatMap(Arrays::stream)
.collect(toList());
// [h, e, l, l, o, w, o, r, l, d]
以及如何生成笛卡尔积(但有一句说一句,感觉不是很直观。。):
// 给定列表[1, 2, 3]和表[3, 4],返回笛卡尔积:
List<Integer> numbers1 = Arrays.asList(1, 2, 3);
List<Integer> numbers2 = Arrays.asList(3, 4);
List<int[]> pairs = numbers1.stream()
.flatMap(i -> numbers2.stream().map(j -> new int[]{i, j}))
.collect(toList());
三、查找和匹配
anyMatch/allMatch
findAny: 注意这个方法返回的是 Optional 容器类(代表一个值存在或不存在),目标为有效的避免 NPE 的情况。
findFirst: 故名思义,与 findAny 的区别在于是否有序的第一个
sorted
distinct
四、归约
- reduce: 举几个例子
- reduce(0, (a, b) -> a + b): 0 代表初始的指
- reduce(0, Integer::sum) / reduce(0, Integer::min)
但如果你想找到多个交易中,金额最大的拿笔交易:
// 找到最大金额的交易
Optional<Transaction> maxTransaction = transactions.stream()
.reduce((t1, t2) -> t1.getValue() > t2.getValue()?t1:t2);
总结
用文中的一张图总结一下:
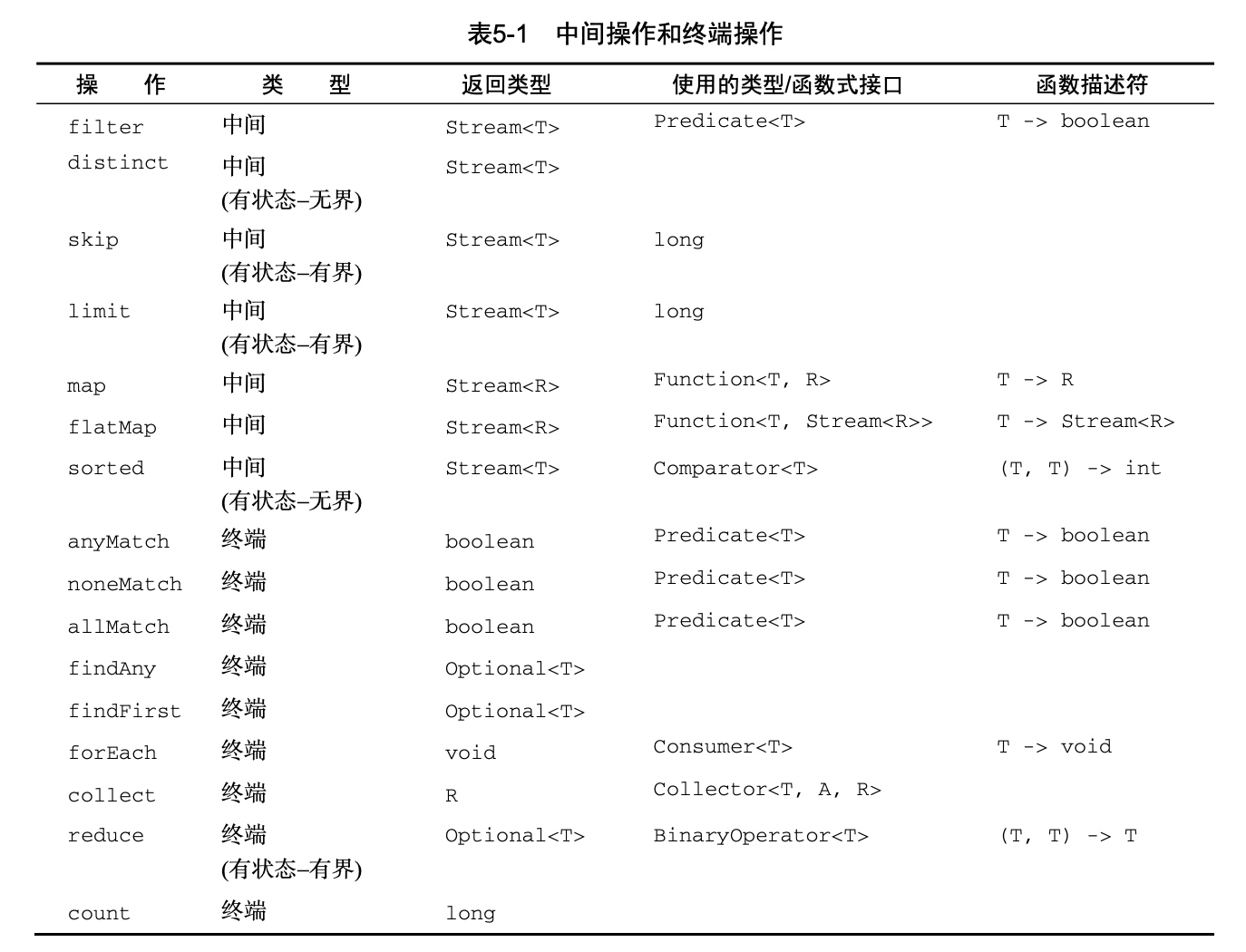
第六章:用流收集数据
collector 的三大功能:
- 将流元素规约和汇总为一个值
- 元素分组
- 元素分区
1. 汇总
- 最大值/最小值
Comparator<Dish> dishCaloriesComparator =
Comparator.comparingInt(Dish::getCalories);
Optional<Dish> mostCalorieDish =
menu.stream()
.collect(maxBy(dishCaloriesComparator));
- 总数
int totalCalories = menu.stream().collect(summingInt(Dish::getCalories));
- 连接字符串
String shortMenu = menu.stream().map(Dish::getName).collect(joining());
2. 元素分组
其实就是 groupby
Map<Dish.Type, List<Dish>> dishesByType = menu.stream().collect(groupingBy(Dish::getType));
也可以直接计算 count
Map<Dish.Type, Long> typesCount = menu.stream().collect( groupingBy(Dish::getType, counting()));
还可以多级的分组。。。不太喜欢,就不列例子了
3. 分区
以下的返回结果分别为 true/false 对应的 map
Map<Boolean, List<Dish>> partitionedMenu = menu.stream().collect(partitioningBy(Dish::isVegetarian));
第七章:并行数据处理与性能
好复杂,跳过
第三部分:高效 java8 编程
罗列了一些设计模式,跳过。
第八章:重构、测试和调试
如何调试
一、堆栈
Q: 这个挺有意思的,下面堆栈中的 $0 是什么意思呢?
A: 这些表示错误发生在Lambda表达式内部。由于Lambda表达式没有名字,所以编译器只能为 它们指定一个名字。
Exception in thread "main" java.lang.NullPointerException
at Debugging.lambda$main$0(Debugging.java:6)
at Debugging$$Lambda$5/284720968.apply(Unknown Source)
at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline
.java:193)
二、日志
利用 peek 插入打印日志的动作:
List<Integer> result = numbers.stream()
numbers.stream()
.peek(x -> System.out.println("from stream: " + x))
.map(x -> x + 17)
.peek(x -> System.out.println("after map: " + x))
.filter(x -> x % 2 == 0)
...
第九章:默认方法
Q: 首先回答为什么需要默认方法呢?
A: nterface 新增一个方法的时候,不让已有的代码报错,从而有了默认方法。
举个例子:java 中 extend 只能继承一个父类,但可以 implement 多个接口。好处在于默认方法的复用
public interface Rotatable {
void setRotationAngle(int angleInDegrees);
int getRotationAngle();
default void rotateBy(int angleInDegrees){
setRotationAngle((getRotationAngle () + angle) % 360);
}
}
public interface Moveable {
int getX();
int getY();
void setX(int x);
void setY(int y);
default void moveHorizontally(int distance) {
setX(getX() + distance);
}
default void moveVertically(int distance) {
setY(getY() + distance);
}
}
public interface Resizable {
int getWidth();
int getHeight();
void setWidth(int width);
void setHeight(int height);
void setAbsoluteSize(int width, int height);
default void setRelativeSize(int wFactor, int hFactor) {
setAbsoluteSize(getWidth() / wFactor, getHeight() / hFactor);
}
}
// 可以 旋转、移动、
public class Monster implements Rotatable, Moveable, Resizable {
...
}
public class Sun implements Moveable, Rotatable { ...
}
但假如 Rotatable 和 Moveable 接口,都存在一个相同名字的默认方法,造成的冲突要如何解决呢?
第十章:用Optional取代null
为避免 NPE 引入了 Optional 对象
创建 Optional 对象
空的 Optional
Optional<Car> optCar = Optional.empty();
非空值创建 Optional, 注意如果 car 为 null,则立刻抛出一个 NPE
Optional<Car> optCar = Optional.of(car);
可接受 null 的 Optional
Optional<Car> optCar = Optional.ofNullable(car);
获取 Optional 中的值
如何重构下面的代码呢?
person.getCar().getInsurance().getName();
假设 person 是一个 Optional 的对象:
person.flatMap(Person::getCar)
.flatMap(Car::getInsurance)
.map(Insurance::getName)
.orElse("Unknown");
上面 flatMap 与 map 的区别:
都是在不为 null 的情况下,根据约定 flatMap 返回的是 Optional 对象,而 map 则直接返回对应的值。
将 Insurance 定义为 Optional 类型的另一个好处在于,告诉未来的同事,它很明显可能是一个空值。
实战
case1: 用Optional可能为null的结果
// 优化前
Object value = map.get("key");
// 优化后
Optional<Object> value = Optional.ofNullable(map.get("key"));
case2: 巧用异常处理
// 优化前
Integer.parseInt(String)
// 重构后
public static Optional<Integer> stringToInt(String s) {
try {
return Optional.of(Integer.parseInt(s));
} catch (NumberFormatException e) {
return Optional.empty(); }
}
}
第十一章:CompletableFuture:组合式异步编程
使用 异步线程 + future,避免一些 IO 操作的时候阻塞当前线程:
p.s. 完整可运行的代码:链接
public class Main {
static List<Shop> shopList = Arrays.asList(
new Shop("shop1"),
new Shop("shop2"),
new Shop("shop3")
);
private static void findPrices() {
List<String> productList = shopList.stream()
.map(shop -> shop.getPrice("apple"))
.map(Quote::parse)
.map(Discount::applyDiscount)
.collect(toList());
System.out.println(productList);
}
private static void findPricesAsync() {
List<CompletableFuture<String>> productFutures = shopList.stream()
.map(shop -> CompletableFuture.supplyAsync(
() -> shop.getPrice("apple")))
.map(future -> future.thenApply(Quote::parse))
.map(future -> future.thenCompose(quote ->
CompletableFuture.supplyAsync(
() -> Discount.applyDiscount(quote))))
.collect(toList());
List<String> productList = productFutures.stream()
.map(CompletableFuture::join)
.collect(toList());
System.out.println(productList);
}
public static void measure(Runnable r1) {
long start = System.currentTimeMillis();
r1.run();
long end = System.currentTimeMillis();
System.out.println(end - start);
}
public static void main(String[] args) {
// 3 x (100ms+100ms) ≈ 600ms
measure(Main::findPrices);
// 100ms+100ms ≈ 200ms
// 使用多线程的方式将多个查询任务并行执行
measure(Main::findPricesAsync);
}
}
如果需要对多个商品发起查询呢?
可以考虑使用 parallelStream 并行运行,提高性能(因为运行不要求是有序的)
等待所有 查询 执行完毕后,进行汇总。当然也可以使用 anyOf 方法,意味着任意一个查询结束即返回。
CompletableFuture[] futures = findPricesStream("myPhone")
.map(f -> f.thenAccept(System.out::println))
.toArray(size -> new CompletableFuture[size]);
CompletableFuture.allOf(futures).join();
p.s. 说实话有点过于复杂了,不太喜欢。。
第十二章:新的日期与时间API
(略)
第四部分:超越 Java 8
(略)