我的 python 线程为什么执行到一半就消失了!!!
如果一个bug可以在本地重现, 那基本上已经解决了一半.
最近遇到一个无法在本地重现的多线程bug, 和同事花了一个星期终于解决了, 真的是更深的理解了上面这句话.
背景
在我们的Django应用中, 一个完整http请求的处理链路如下:
最后三步(view + 线程池 + method)的代码逻辑如下:
from concurrent.futures import ThreadPoolExecutor
alarm_handler = ThreadPoolExecutor(max_workers=22, thread_name_prefix="alarm_handler")
def method(request):
try:
# do some post requests
pass
except Exception as e:
...
def view(request): # noqa
future = method(_handle_new_alarm, request)
# Add a callback to raise Exception when future.result is Exception
tools.raise_when_error(future)
多么完美的处理流程呀! 但诡异的是, 经常会发现有请求处理到一半中断的情况, 但重跑却没有任何异常!!!
排查
线索一: 日志
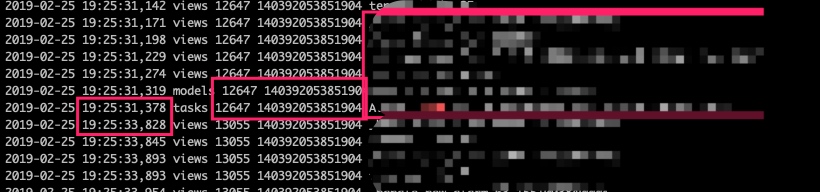
遇到这类线上问题, 第一直觉肯定是去查看日志. 花了一些时间尝试多打印日志定位问题, 但最后发现每个线程的日志会在流程最后一步中(抛给线程池并执行的method)中随机中断, 并且没有抛出任何异常, 如果有的话肯定会被 future 的 callback进行处理, 并被 sentry 捕捉到).
但是! 有个重要的细节被忽略掉了: 线程处理中断的时候, 线程id没有改变, 但进程id新起了一个, 这个点为未来埋下了伏笔
线索二: 重现的频率
发现这个bug后, 第一时间新建了一个错误数的监控, 发现整体上涨的趋势其实比较平稳(接近每五分钟发生一次, 但分布零散).
猜猜猜
基于上述两个线索, 机智的同事猜到了 bug 的原因: 我们在 uwsgi 的配置文件中设置了 max-requests=5000, 也就是说如果每个 worker 收到超过 5000 个请求, 就会被杀掉并且重启(killed and restart):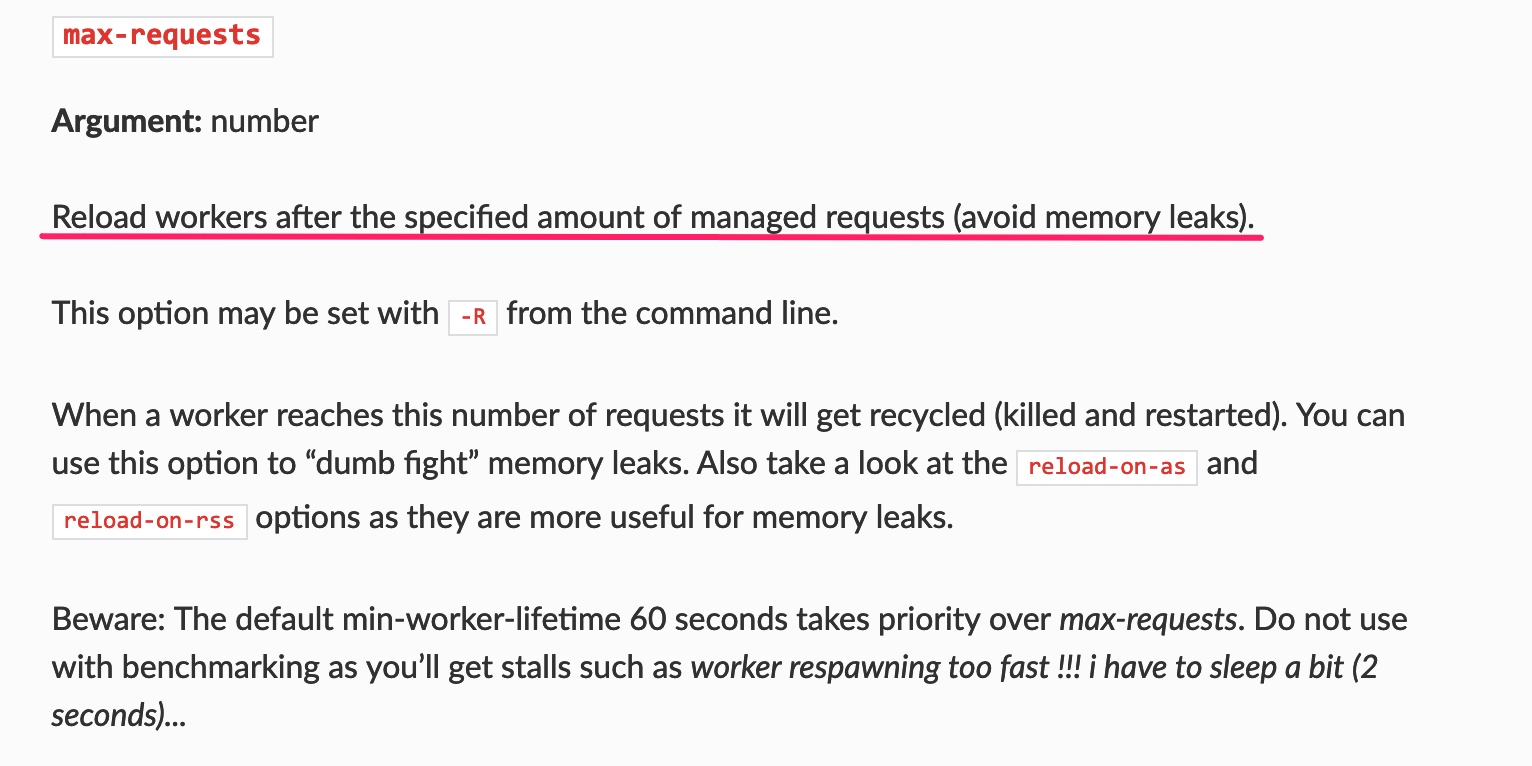
一般情况下, 这是没有什么问题的, 因为 worker 每次 respawn(重生)的时候, 会等它 gracefully 处理完所有的请求. 但我们的view把任务抛到线程池处理直接返回了, 导致uwsgi 认为请求处理完毕并reload worker 了.
在 uwsgitop 中, 可以最后一列看到每个 worker 最后一次 respawn的时间, 验证了这个猜测.
本地重现
起一个本地的 uwsgi 进程, 并设置 --max-requests 为 5, 可以看到第五次请求的时候, 进程会被 killed and respawned:
[pid: 88900|app: 0|req: 5/5] 127.0.0.1 () {40 vars in 549 bytes} [Sat Mar 2 16:49:47 2019] POST /new_alarm => generated 194274 bytes in 303 msecs (HTTP/1.1 500) 1 headers in 63 bytes (2 switches on core 0)
...The work of process 88900 is done. Seeya!
worker 1 killed successfully (pid: 88900)
Respawned uWSGI worker 1 (new pid: 89687)
反思
借官方文档的一段话:
Finally: Do not blindly copy & paste! Please, turn on your brain and try to adapt shown configs to your needs, or invent new ones.
Each app and system is different from the others.
Experiment before making a choice.