..
K-means学习记录, 没想到你是这样的聚类算法
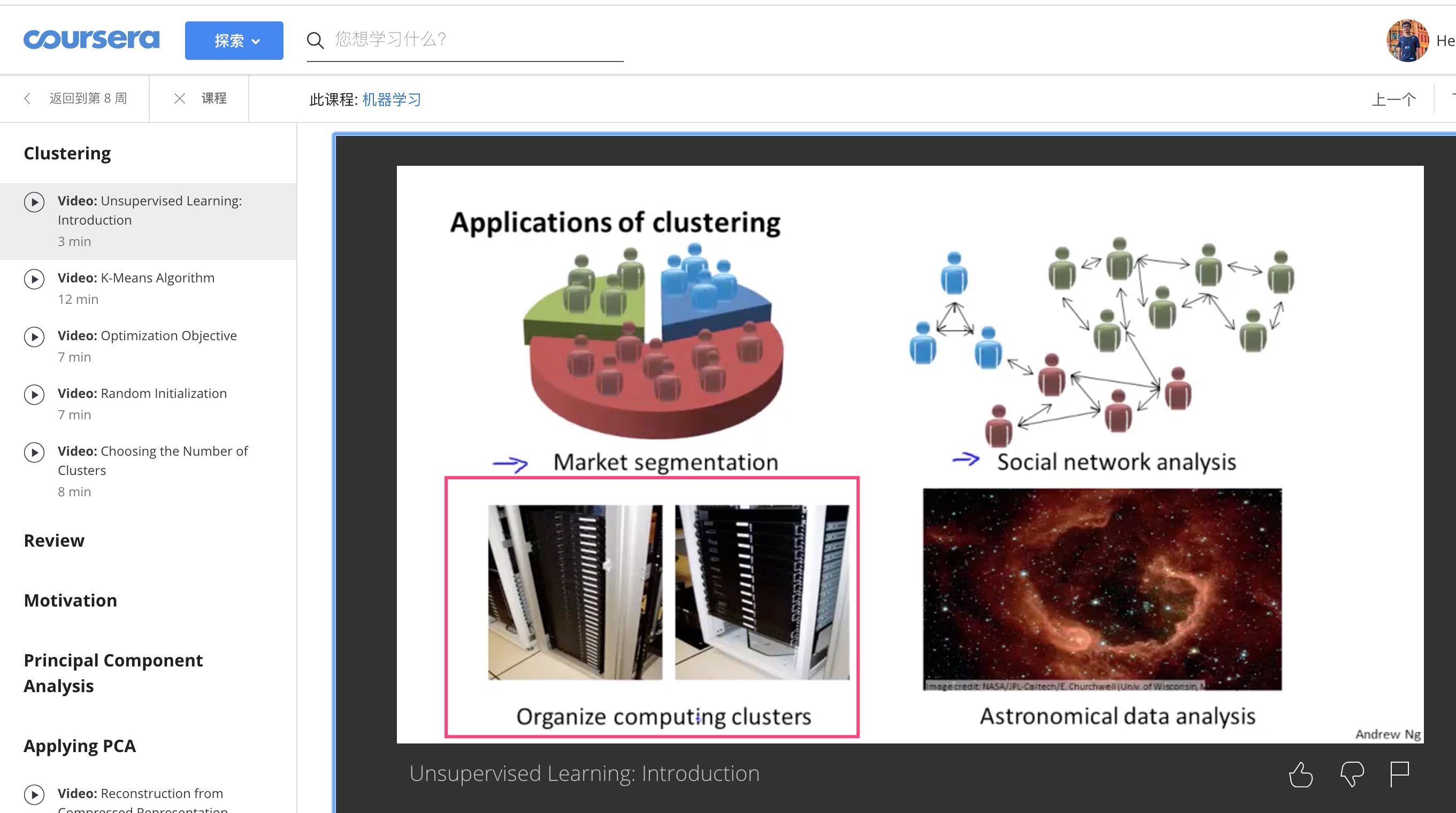
今日在学机器学习 第八章(Unsupervised learning) 的时候, 开头介绍时讲到了 K-means 应用在大型计算集群的资源分配上(见下图).
突然间一些回忆就猛的涌上心头: 本科跟着老师做的算法研究, 最后毕业论文的名字叫做《基于虚拟机放置策略的数据中心网络节能算法研究》, 其实和刚刚提到的资源分配非常类似. 当时在论文摘要中提到了K-means算法, 可惜并没有深入去了解原理. 惭愧, 趁这个机会好好学习下, 算法并不复杂, 更多的是作为一次记录与反省.
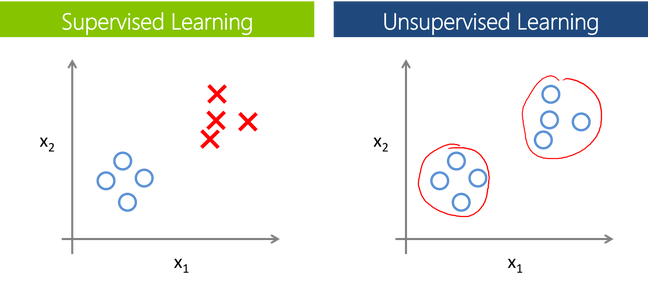
supervised learning 与 Unsupervised learning的区别
个人理解 一是知道了一堆人中男人和女人, 找个方法把他们分开, 然后新来一个人也能根据这个方法来判断他的性别. 二是把一堆人自动分为两类.
K-means 聚类算法的解释
K-means 聚类算法属于 Unsupervised learning 的一种, 下文会分四个步骤详细解释一下.
第一步: randomly initialize two points
随机选择两个点. 如果想把图中没有标记的点分为K类, 就随机选择K个点.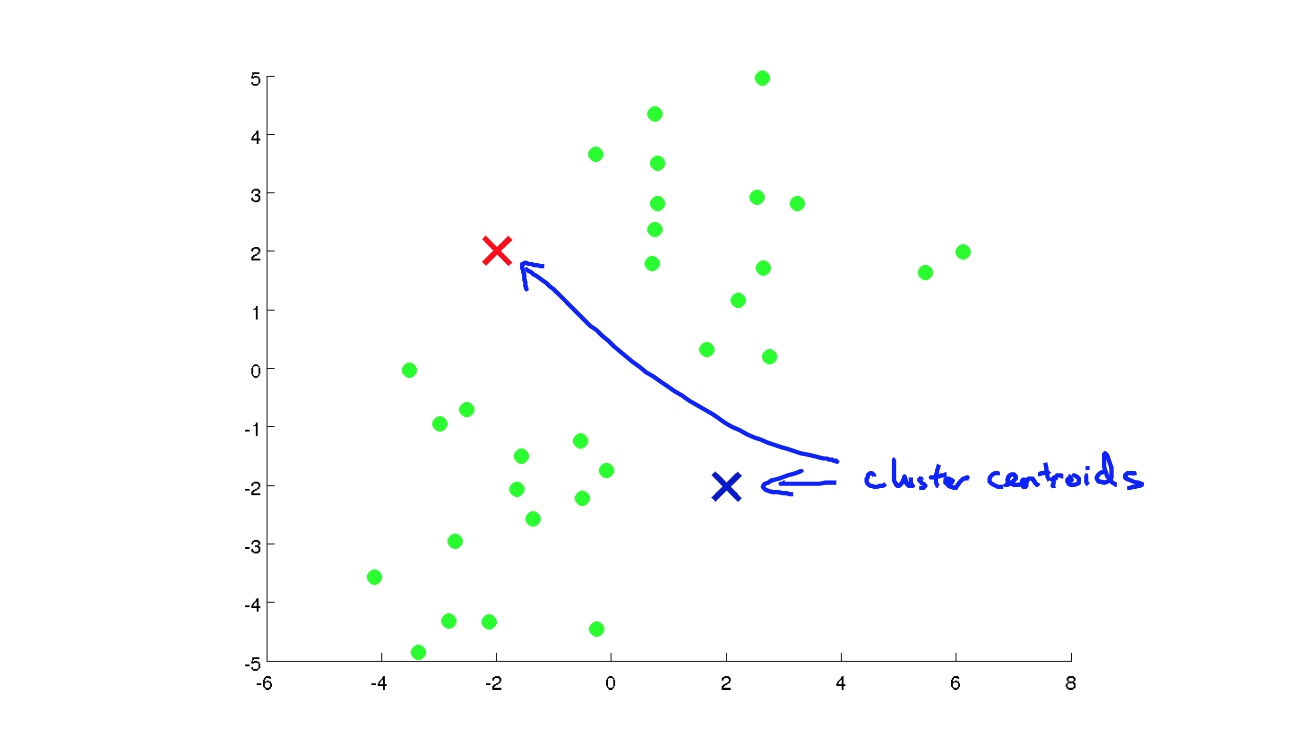
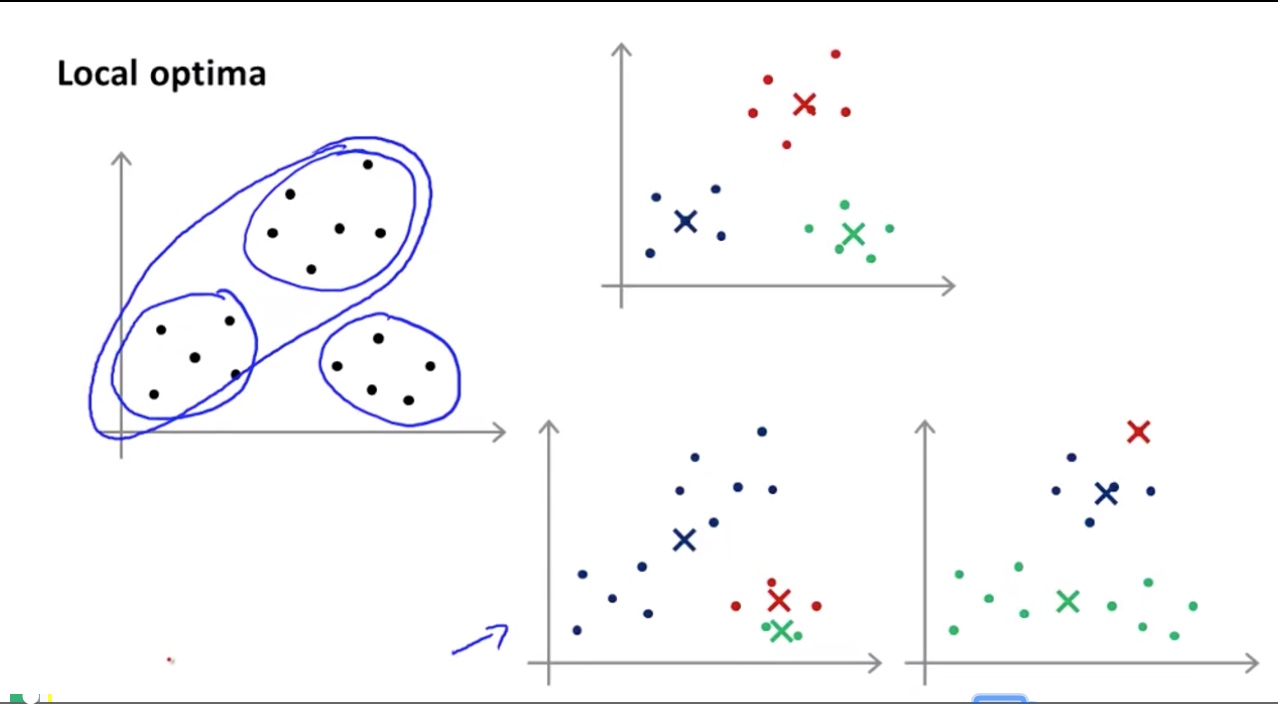
优化: 如下图随机选取三个点, 但如果初始化不好的话, 很可能两个点会一直在一个cluster中, i.e. 另外两个cluster被合在一起了.
解决办法: 也是挺暴力的, 执行随机放置初始化的点(也就是步骤一)一百次, 挑最好的那次来避免这种情况(randomly initialize for 100 times, and pick one for the lowest cost).
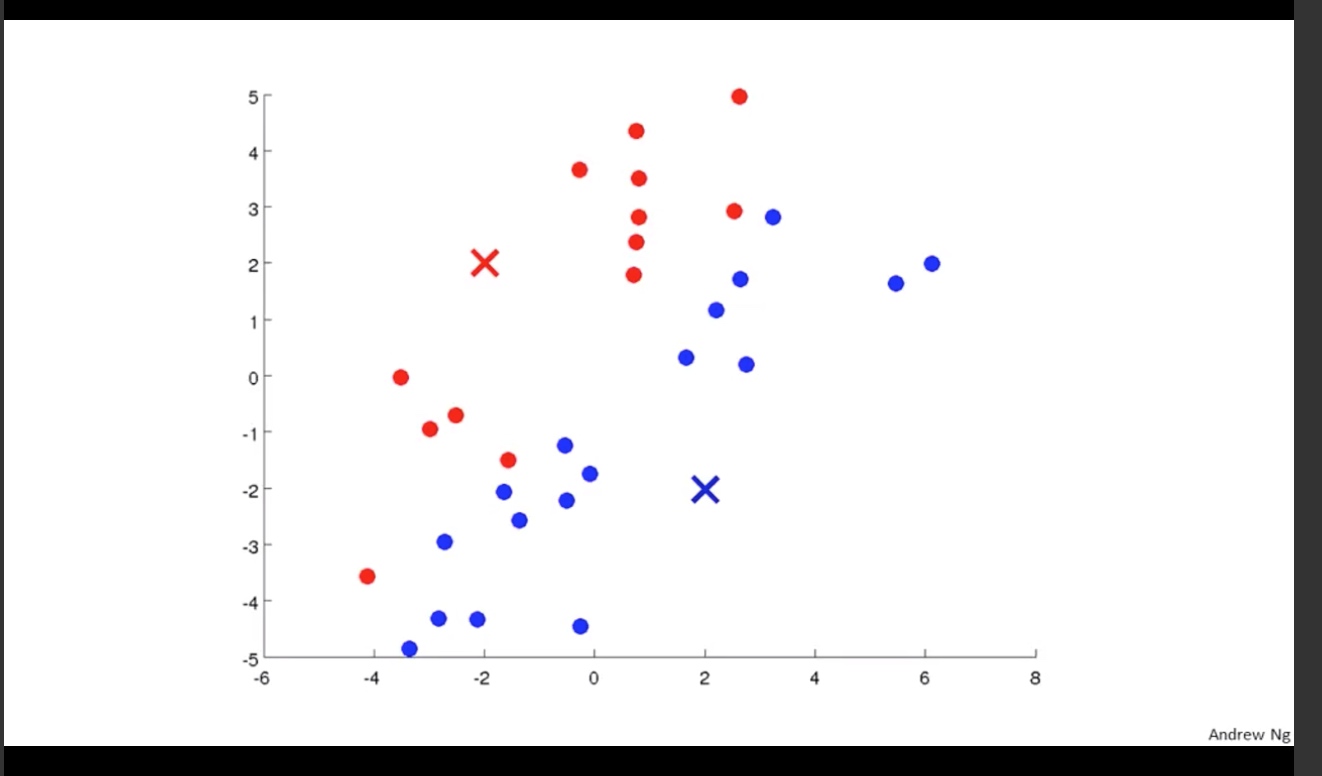
第二步: cluster assignment
将图中的所有点, 根据与初始化点的距离, 分为两组.
第三步: move two points to the new means(e.g. average of the all the blue points)
根据第二步得出的两组点, 重现计算新两个的中心(见下图箭头所指的点所示).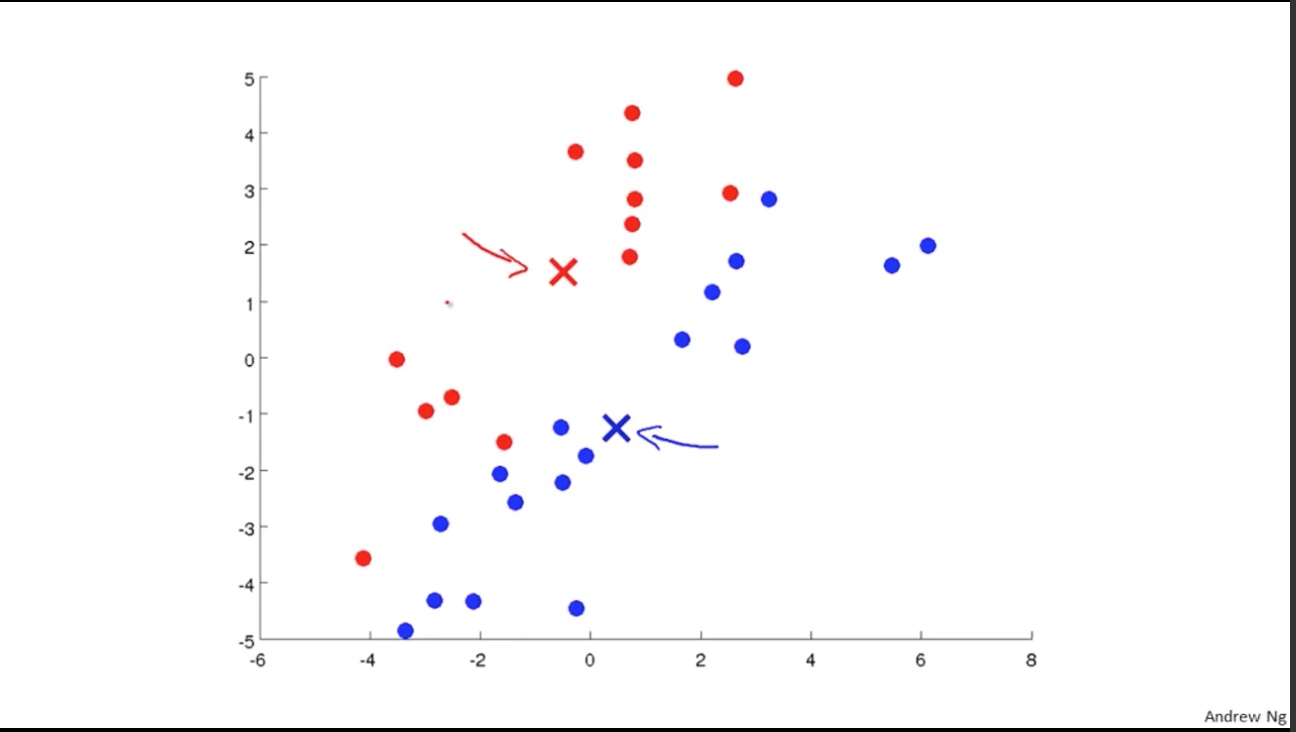
第四步: until the two point not moving any further.
一直重复前三步的操作, 直到新的中心不再变化为止.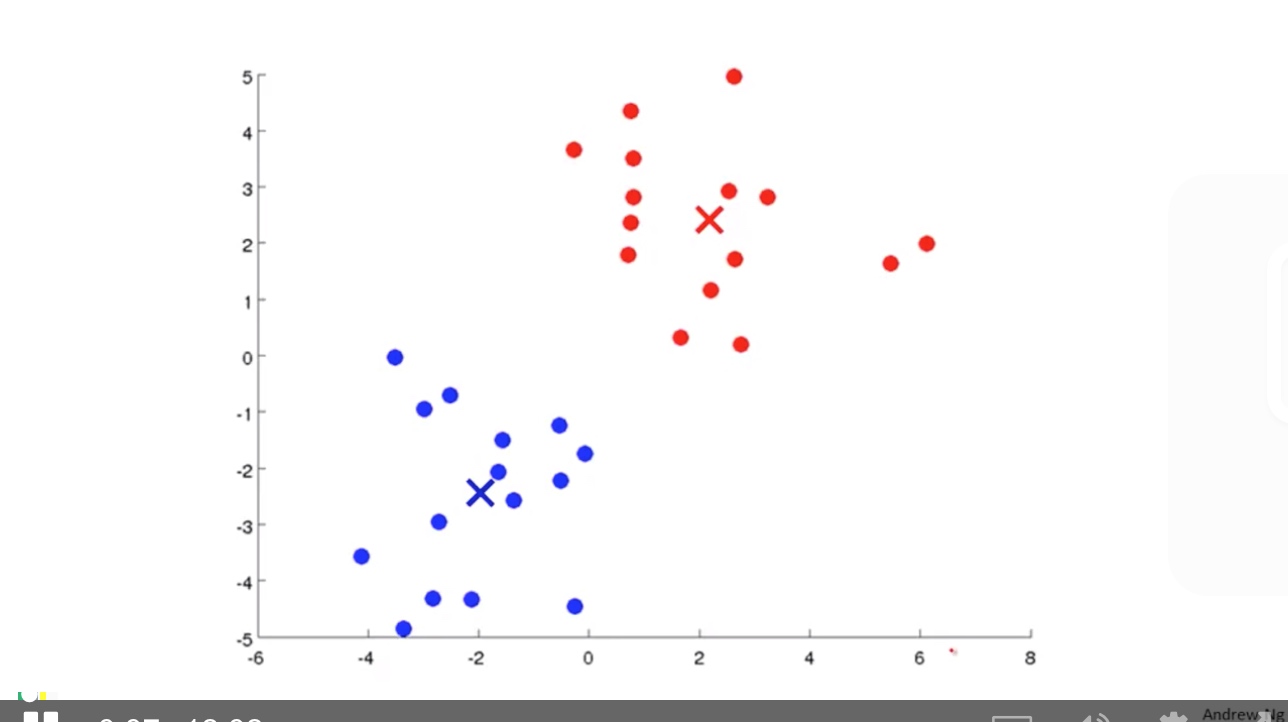
其他
有不懂的地方尽管给我留言哦, 笔芯.
–EOF–