Henry Z's blog
《Site Reliability Engineering》by Google 读书笔记
下一份工作要开始做 SRE 了,准备看下Google 出的《Site Reliability Engineering》稍微准备一下。感觉写的还是挺不错的, 顺便这篇博客记录读后感(期望更多的是个人的一些思考和感悟)。
陆陆续续读了快两年。。突然想起一句话:人生的意义不在于某个时间点的状态,而是随着时间流逝而留下的痕迹。希望这篇幼稚的笔记也能成为我在这个世界留下的一丝痕迹。
p.s. 划重点,欢迎交流或推荐好的书~

Part I - Introduction
Chapter 1 - Introduction
- dev/ops分离的历史: 最早时,在公司维护复杂系统的人叫做sysadmin(systems administrator),但后来因为 sysadmin 和 developer 需要的技术完全不一样, 所以逐渐分为了两个完全不同的岗位:developer & operations(ops), 应该就是我们所谓的开发与运维吧。
- 这种模型(开发与运维的完全分离),好处和坏处
- **1) 最大的好处就是:**业内有成熟的解决方案, 不用重复的造轮子, 所以用人与开发成本也比较低.
- 2) 但最大的坏处:
- Direct costs: 发布和变更需要人工干预 → 系统的规模和需要的人手成线性关系(例如总不能项目多部署一套环境, 就增加一个人手).
- Indirect costs: (个人理解是)开发与运维的矛盾: 开发需要尽快的上最炫最酷的新功能, 而运维则想保持服务100%的稳定性, 再加上完全不同的技术栈, 很容易造成矛盾. 所以一定要在两者之间找一个平衡点.
- google对于sre的目标: 以软件开发的方式打造一个系统, 将运维的工作变得全自动(automatic). (Site Reliability Engineering teams focus on hiring software engineers to run our products and to create systems to accomplish the work that would otherwise be performed, often manually, by sysadmins.), 终极目标就是: 减少第一条中的Direct costs(人为干预), 使得系统规模与运维人员的人数不成线性增长.
- 有一句话挺有意思的, 说的是要去评估SRE的消耗的时间分布, 才能保证开发人员在ops和development上花费时间的平衡. 因为sre与传统运维最大的不同就是加入了开发, 而不是一味的做operation. 但相对的develop 的时间不能超过50%, 以防止承担了过多原本属于development team的事情, 或一直投入运维人员, 而忘了利用原有的员工去做operation的工作.但打动我的是 “measure how SRE time is spent”, 感觉对人对团队对整个sre的measurement, 是所有事情能顺畅实现的基础.
- DevOps? (这个词近几年很火吧, 但惭愧的是一直没搞懂到底是什么. 书中说可以把sre当作一种devops的具体实现, 并包含一些独特的扩展?) - “One could equivalently view SRE as a specific implementation of DevOps with some idiosyncratic extensions.”
- Service’s SLO?: (第四章会详细解释一些含义)
- 不必过分追求100%?: 文中强调的一个观点挺有意思的: 对于sre来说, 100%并不是一个正确的指标? 作者说因为用户其实完全感受不到99.999%与100%的区别, 而且现实中用户家中的笔记本, 路由器, ISP等等远达不到99.99%的可用性 但还是需要定目标: 如果可用性达到99.99%, 0.01%就可以作为error budget, 然后利用这个error budget去冒风险发布一些新特性, 并吸引新用户. (感觉感觉作者认为这样就很好解决了第一条中所谓的indirect cost, 使得生产事故变成一种预期之内的事情?? 解决了开发追求急切的上新功能, 而运维想要保持100%可用性的矛盾. )
- blame-free postmortem culture: 强调出了事故, 不要过分的去指责而是仔细剖解问题, 防止下一次的发生? 在国内领导负责的国情感觉不是很现实 :P
Chapter 2 - The Production Environment at Google, from the Viewpoint of an SRE
- Machine: A piece of hardware (or perhaps a VM),Server: A piece of software that implements a service
- 硬件故障: 我们平时可能认为, 硬盘内存几乎是不可能坏的, 但文中说到, 对于一个超大规模的data center来说, 硬件出故障是个很常见的问题, 所以目标就是要让用户完全无法感知到硬件的故障.
- 因为不同的(几千个)任务动态的分布在不同的机器上, 所以不能单纯的用ip和端口去启动任务, 文中给出的一个解决方案:
/bns/<cluster>/<user>/<job name>/<task number>, 然而并不是特明白. - 对于任务的分布(例如一个任务需要3个cpu, 2g内存), 有趣的是文中说到要尽可能优化的放置(二次装箱问题). !!!但又不能把鸡蛋都放在一个篮子(同个Rack或Pod)里(很有可能一个路由坏了, 那就全gg了).
- Remote Procedure Call (RPC), 了解一下?
- Life of a Request: 在 17 年后台研发工程师的一年, 我一直在思考一个问题: 一个 request 的 lifecycle, 于是去读了web框架(Django)的源码, 自己去实现一个uwsgi, 看http, tcp协议… 看到书中的request lifecycle, 感觉今年的目标是更多的了解大型项目的request lifecycle, 例如高并发的负载均衡问题, 等等.(This request ultimately ends up at Google’s DNS server, which talks to GSLB. As GSLB keeps track of traffic load among frontend servers across regions, it picks which server IP address to send to this user.) 原来在dns server这就可以根据地区和负载情况, 分配对应的服务器ip, 但是为什么走到GFE反向代理找frontend server的时候, 又要去根据GSLB进行一次负载均衡的处理呢?
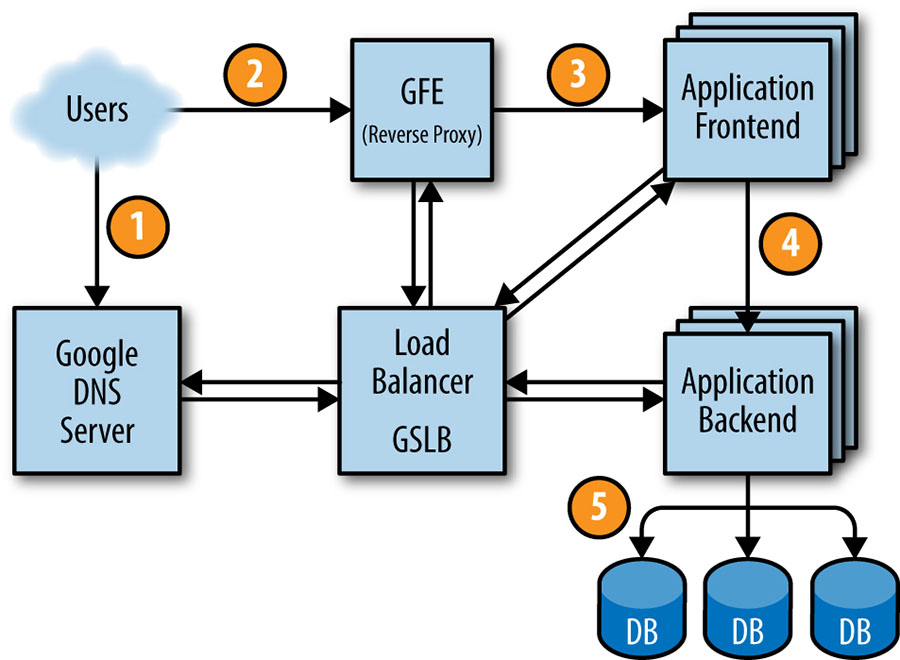
- QPS: queries per second
- N+2原则: 如果说预期3,470 QPS, 而一个backend server最多能处理100QPS, 则至少需要35个server. 但是一般采用N+2的策略(37个server), 因为:
- 如果在升级中, 会有一个server不可用
- 如果一个机器挂了, 会重新放置task到别的server.但是有时候也可以用
N+1的原则. 因为如果需要的server很少, 比如只需要3个server的情况, 就可以利用牺牲高延迟的风险, 去节省20%的硬件资源(+1相对于+2节省了一台虚拟机).
- 如果一个机器挂了, 会重新放置task到别的server.但是有时候也可以用
Part II. Principles
Chapter 3 - Embracing Risk (拥抱风险?)
- 100%的可用性是个错误的目标?(100% is probably never the right reliability target?) 文中的解释:
- 因为cost和reliability并不是线性关系, 99%→100%会带来极大的开销, 并对服务更新升级的速度造成负面影响.
- 像第一章里提到的那样, 用户其实很难感知到99.99%和99.999%的区别.
- rapid innovation and efficient service operations的平衡, 即保持服务的高可用 VS 用最快的速度把新功能新特性传递给用户.
- 如何评估服务的高可用: “Unplanned downtime is captured by the desired level of service availability, usually expressed in terms of the number of ’nines’ we would like to provide: 99.9%, 99.99%, or 99.999% availability.” 想起面试的时候, 问了面试官个很幼稚的问题:如何去评估一个系统的高可用能力, 他笑了笑, 说到了四个9和五个9,参考文章附录的《Availability Table》
- Time-based availability: availability = uptime / (uptime + downtime), 所以99.99%就意味着服务down的时间不能超过52.56分钟.但是! 文中提到google的server是分布在全球的, 就很难用这种方式去测量availability, 所以引出了一个新的概念: request success rate.
- Aggregate availability: availability = successful requests / total requests.但是!! 不同的request失败对用户的影响其实是不同的, 例如支付失败和获取好友信息request失败.
- (个人认为)measurement的重要性: 因为measurement是提升的基础, 没有量化, 如何比较提升还是破坏呢. 最简单的例子: 我们在优化一段代码速度的时候, 一定要先做profile, 再针对某几行代码做优化, 最后比较总的运行时间, 看运行速度提升了多少. 比如文中提到的: “By setting a target, we can assess our current performance and track improvements or degradations over time.”
- “Hope is not a strategy.” → The more data-based the decision can be, the better.
- 文中提到对error budget的使用(定义: 如果可用性定的目标是99.99%, error budget就是0.01%, 然后如果这个季度测量结果为99.992%, 那么error budget就可以认为使用了20%).所以可以用error budget很好的制约SRE团队与product development团队. 例如, 提前订好了reliability的目标, 如果在开发中, error budget消耗(使用)的太快了, 就放缓迭代发布的速率, 并增强测试.
Chapter 4 - Service Level Objectives
- 一开始就引出了三个概念:
- service level indicators (SLIs): service的指标, 比如请求的响应速度, 出错的概率, system throughput(requests per second)等等.
- service level objectives (SLOs): 目标, 例如latency在100ms内 or QPS(Query per Second)达到1万. 但一般QPS很难去制定目标, 因为它是未知的(比如某个明星出轨, weibo流量爆了).
- service level agreements (SLAs): 区分SLO和SLA的区别, SLA更侧重于如果没有达到之前定的目标应该怎么办. 比如Google search就没有SLA, 因为没有和用户达成协议, 就算某一天不能用了, 虽然会造成一系列的后果, 但不用对用户负责.
- 有一句话挺有道理的: 对于SLI并不是越多越好, 而是要去监测那些用户真正在乎的指标.
- 选择SLOs的准则!:
- Don’t pick a target based on current performance: ???
- Keep it simple: 和单元测试一个道理..太复杂的话, 功能一变动会很难维护.
- Avoid absolutes: 没有必要要求不管QPS多高, latency都保持很低.
- Have as few SLOs as possible: 和第二条类似.
- Perfection can wait: SLOs刚开始的时候不必太苛刻, 否则很容易造成开发时间的浪费. (想起我看Django性能优化官方文档的一句话: “Your own time is a valuable resource, more precious than CPU time. Some improvements might be too difficult to be worth implementing, or might affect the portability or maintainability of the code. Not all performance improvements are worth the effort.”)
Chapter 5 - Eliminating Toil
- “If a human operator needs to touch your system during normal operations, you have a bug. The definition of normal changes as your systems grow.” 有点意思, 以前人们一提起运维, 就想到苦逼. 但真的是这样吗? 看到面试官微信的简介是
Never repeat yourself., 心里又多了一丝的希望的小蜡烛, 因为个人觉得这就是sre和传统运维不同的地方. - Operation work → Toil → 脏活累活, 定义如下:
- Manual
- Repetitive
- Automatable
- Tactical(没看懂): Toil is interrupt-driven and reactive, rather than strategy-driven and proactive. Handling pager alerts is toil.We may never be able to eliminate this type of work completely, but we have to continually work toward minimizing it.
- No enduring value: 无用功?
- O(n) with service growth!!!
- “The work of reducing toil and scaling up services is the “Engineering” in Site Reliability Engineering.” 有意思, 而且上文提到toil如果不及时处理, 就会很快的占据所有人100%的时间.
- Calculating Toil: 挺无脑暴力的一个计算, 如果说一个团队有6个人, 在一个周期(六周)中, 每个人on-call的时间总共是两周(一周primary on-call+一周secondary on-call), 那么他toil的占比至少为33%(1/6+1/6)
- 理论上每个SRE在toil上花费的时间不应该超过50%.
- Is Toil Always Bad? toil 并不是永远是不好的, 重复无脑的工作其实能让人变得无比平静(calming)?? 并且完成少量的toil还有一丝丝成就感呢.但多了就要gg了, 因为:
- 过多的toil会抑制你在实际项目中做贡献, 并令你职业生涯停滞不前.
- 每个人都会有忍耐的上限, 无限的toil只会让人精疲力尽并感到厌烦.
- 结论: 只要每个人都能消灭一点toil, 最终就能把精力都放在开发下一代更大规模的架构! 我们的口号是: “Let’s invent more, and toil less!!!”
Chapter 6 - Monitoring Distributed Systems
- 为什么需要监控:
- 了解整体的趋势: 比如数据库硬盘占用提升的速率, 日活跃用户增长的趋势. (可以提前做处理?)
- 量化提升: 与历史数据做对比, 很方便直观的比较性能变化.
- 及时报警: 在第一时间修复.
- 打造dashboard
- 监控报警不能太频繁: “When pages occur too frequently, employees second-guess, skim, or even ignore incoming alerts, sometimes even ignoring a “real” page that’s masked by the noise.” 不能稍微有点不对劲就报警, 不然就变成狼来了.
- The Four Golden! Signals 类似蚂蚁的 spm 自定义监控(常用服务指标)
- latency: 注意一定要将成功请求与失败请求的延迟数据区分开(我们都知道比如一个request失败并返回了500或502, 它的延迟一般都会特别的低) 所以不能将它用作计算到到平均的延迟, i.e.要将它们过滤出来.
- traffic: 对于web服务来说, 通常为HTTP requests per second.
- errors: 注意对error的定义. 还有要注意的一点, 如果502了, 例如Django的Sentry就捕捉不到了. 只能通过查看返回的信息是否正确来监控.
- saturation: 比如再来20%的流量, 系统是否能扛住. 或者预测到还有4小时, 数据库的硬盘就要满了.
- 讲到监测采集数据的频率其实不用太高. 虽然会发现一些隐藏的细节, 但分析和存储的成本都太高了.
- 监测不能搞的太复杂, 不然监测系统会变得很fragile, 而且难以维护. 说了三个原则, 其实就是开始时就让 incidents 保持简单, 并定期去清除很少用到的巴拉巴拉.
- “Every page should be actionable!” 还提到一点: 监测系统发起的报警的问题必须是可以被解决的. 不难理解, 因为如果报警了解决不了, 那就是完全无效的 → 每次都要忽略掉, 久而久之很可能会忽略掉一些严重的问题的报警.
Chapter 7 - The Evolution of Automation at Google
- 自动化(Automation)的好处:
- Consistency: 人总是会犯错误的, 相对于机器是个最大的缺点, 也是个最大的优势吧, 嘿嘿.
- A Platform: 可以扩展给多个服务?? 第二段没看懂.
- Faster Repairs: 可以自动的去修复一些常见的错误, 特别是在生产环境人工修复bug的成本是巨大的..
- Faster Action: 人的手速再快也比不上机器
- Time Saving: 写一个脚本花费的时间 vs 这个脚本未来能节省的时间. 在犹豫的时候, 亲身感受也会强烈自己去写自动化脚本.
- “If we are engineering processes and solutions that are not automatable, we continue having to staff humans to maintain the system. If we have to staff humans to do the work, we are feeding the machines with the blood, sweat, and tears of human beings. Think The Matrix with less special effects and more pissed off System Administrators.”
- Google偏爱automation的原因:
- google的规模很大, 服务于全球的用户, 所以对于consistency, quickness, and reliability有极高的需求.
- 复杂但是统一的生产环境: 相比直接购买成熟的软件, Google选择自己造轮子, 所以当无APIs可用时, 就方便快捷地去自己实现一个. 从而去搭建完善的自动化系统(用机器去管理机器).
- automate ourselves out of a job: 文中举了一个实际例子: Ads的SRE团队, 当初计划将mysql迁移到Google的cluster scheduling system上. 这么做的两个好处: 一是减轻维护的工作量, 因为这个平台(cluster scheduling system)会去自动的重启失败的任务. 二是可以将mysql instance做装箱放置. 也就是说在一个physical machine上, 尽可能多地放置mysql instance. 但遇到一个问题: failover需要消耗一个人30-90分钟去处理(有点没看懂failover是什么, 个人理解为机器或各种原因出了问题, 快速的将服务部署在新的硬件上.) 然后sre团队就做了一个自动化解决failover的东西叫做"Decider"(95%的情况下在30s内完成failover). 因为大家意识到"failure is inevitable, and therefore optimizing to recover quickly through automation.". 最终自动化带来的好处: 节省了无数(95%)的人力和物力, 节省了高达60%的硬件资源. 这句话写的挺好的: “the more time we saved, the more time we were able to spend on optimizing and automating other tedious work”
- 文中提到十年前的时候, Cluster Infrastructure SRE team每隔几个月就要去大量招人, 因为员工的速率和服务的规模成正比(turning up a service in a new cluster gives new hires exposure to a service’s internals). 想到原来的公司(Hypers)给新客户部署一套环境的时候(五六个不同的产品), 需要几周的时间, 和这种情况好类似. 然而手动的配置和shell脚本都各自的缺点. 好奇Google是如何解决这个问题的.
- (接上一条)有意思, 解决方案竟然是Prodtest (Production Test): extended Python unit test framework, 但是一个有很多依赖的单元测试(如下图):
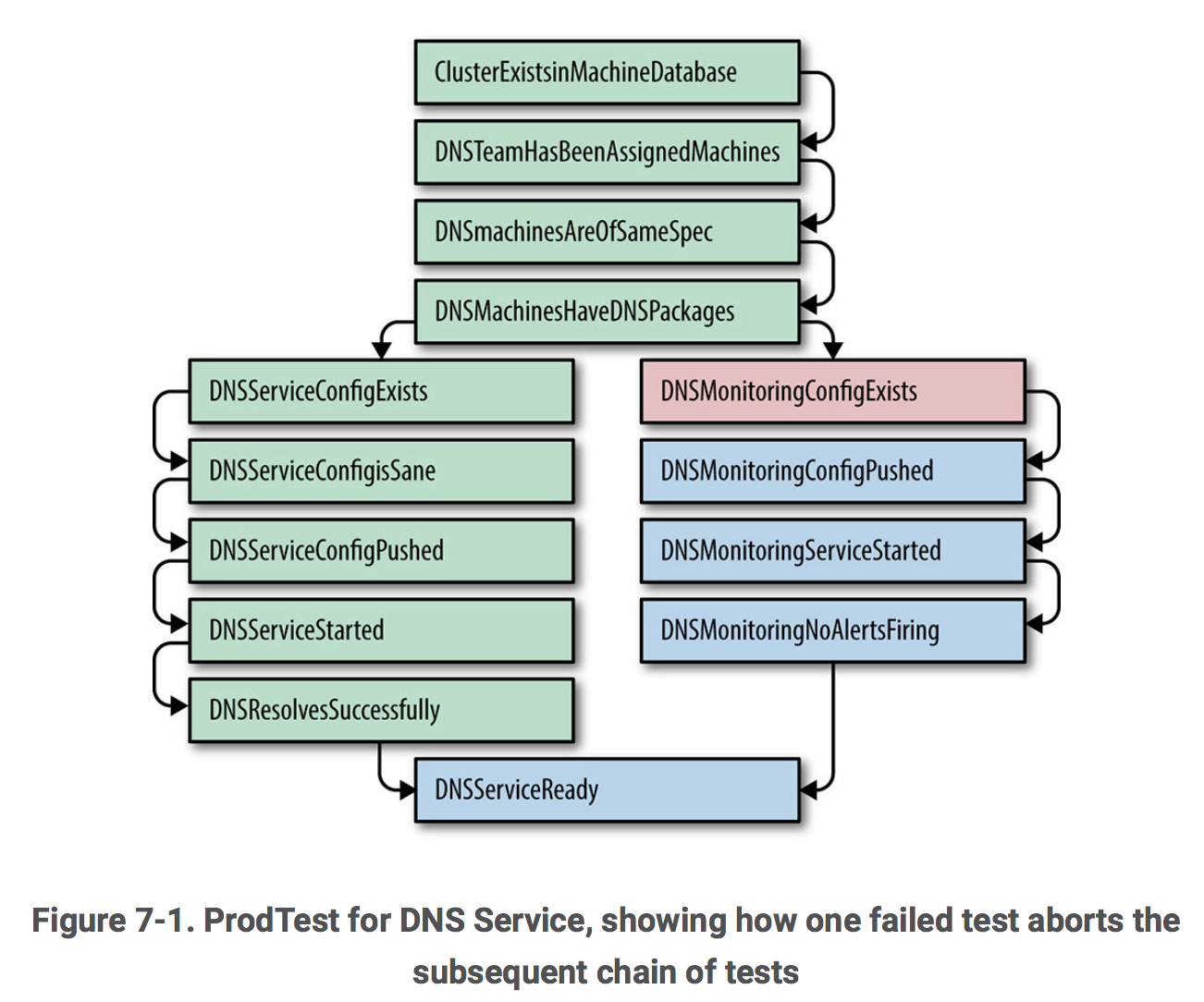 好处: 方便的校验配置是否正确, 如果出错了, 快速的定位出错的步骤和详细的错误信息. 而且每次出现配置出错造成延期的时候, 就将它加入到单元测试中, 保证相同的错误在未来不会重现.
具体疗效: 有史以来第一次, product manager可以预测服务上线的具体时间, 并遇到延期时, 可以了解到详细原因.
惊不惊喜(out of the blue): 新的挑战 → senior management让他们在一周内让五个新集群同时上线.
好处: 方便的校验配置是否正确, 如果出错了, 快速的定位出错的步骤和详细的错误信息. 而且每次出现配置出错造成延期的时候, 就将它加入到单元测试中, 保证相同的错误在未来不会重现.
具体疗效: 有史以来第一次, product manager可以预测服务上线的具体时间, 并遇到延期时, 可以了解到详细原因.
惊不惊喜(out of the blue): 新的挑战 → senior management让他们在一周内让五个新集群同时上线. - 进化!!!: 从利用Python单元测试去找到错误的配置, 变为利用Python单元测试去自动修复. 如下图所示, 如果
TestDnsMonitoringConfigExists没有通过, 就运行FixDnsMonitoringCreateConfig, 然后再尝试之前的测试. 这过程重试多次后如果还是失败的话, 就报错并通知用户. 缺点: “Not all fixes were naturally idempotent, so a flaky test that was followed by a fix might render the system in an inconsistent state.” 说实话没有看明白, 好像是说同一个fix很可能有的时候可以成功修复一个问题, 但有的时候又失败了, 造成系统的inconsistency. - 用RPC代替SSH: 因为用SSH去执行命令经常需要那台机器的root权限.
- Google自动化的进程:
- Operator-triggered manual action (no automation)
- Operator-written, system-specific automation
- Externally maintained generic automation
- Internally maintained, system-specific automation
- Autonomous systems that need no human intervention
- Borg(集群管理系统): 诞生的原因: due to the fact that abstractions of the system were relentlessly tied to physical machines. 就是说server更多的要从物理机抽象出来, e.g.原来利用host/port/job分配任务的方式就要被废除了, 而是将集群看作一个整体的资源. 也就是说, 在集群中添加一个服务, 就像给一台计算机新加一块硬盘或RAM.
- 高度自动化的坏处: 会越来越依赖自动化程序, 如果有一天自动化出错了, 反而不知道该怎么办了.
Chapter 8 - Release Engineering
- 在Google有个专门的职位叫做release engineer, 要对很多东西都有深刻的理解, 甚至还包括customer support.
- 文中说google是数据驱动的, 所以有专门的tool(平台)记录每次发布的时间, 各个配置文件都是对应哪个feature. 这些平台都是由release engineer搞出来的.
- release engineering 的四个准则:
- Self-Service Model: 就是说release engineer要提供足够多的automated build system and our deployment tools, 使得发布变成一件全自动的事情. 只有出意外时, 才需要人为的介入.
- High Velocity: 一些暴露给用户的服务, 比如说Google搜索, 需要快速的迭代和发布, 这样每个版本之间的差别也越小. 最终使得 testing and troubleshooting easier(为什么呢?). 甚至还会有一种 “Push on Green"的模式, 只要有改动并且通过了所有测试, 就直接部署了.
- Hermetic Builds:
- 一致性: 如果有两个人, 在两台发布一个版本的代码, 结果应该是完全相同的.
- 密封的(hermetic): 就像docker的容器一样, 完全不依赖外部的库.
- 回滚: 通过重新发布(老的版本号)来便捷的实现. 而且连发布工具的版本也是之前发布时的旧版本.
- Enforcement of Policies and Procedures:发布的时候, 所有的代码改动都需要code review的流程, 并且集成到开发流程之中. 自动发布的平台会把代码变更输出一份报告, 让SREs更好的理解改动, 并在出问题的时候迅速定位. (其实这一小节并没有太看懂, 根据标题个人理解大意是说在发布时, 要严格执行一些规范流程.)
- cherry picking: …
- Rapid: Google的自动发布系统, 然后有一门语言叫做blueprints, 专门用来给Rapid写配置.
- Configuration Management: 配置管理应该是开发和sre合作最紧密的一块区域.. 而且配置更改是instability的潜在根源. 所以在google配置管理不断的进化, 发生了很大的变化:
- Use the mainline for configuration: 在head of the main branch修改配置文件, 更改review之后再apply到生产上(这里的head就是git里的HEAD吗? 没太看懂). 配置与发布版本解偶也导致不一致的问题.
- Include configuration files and binaries in the same MPM package: 和上条刚刚相反. 如果配置少的话, 可以直接把配置文件和执行文件一起打包发布(MPM package是什么东西). 但相对的配置的灵活性就差了很多.
- Package configuration files into MPM “configuration packages.”: 哎, 看了三遍还是没有看懂, 还有上边的cherry picking, 看了十遍也没看懂.
- Read configuration files from an external store: 如果配置变更很频繁, 可以放到第三方平台管理.
- 总结:
- 开发和SRE不应该为发布头疼. 只要有正确的工具, 合适的自动化, 规范的policy, etc. 发布只不过是按个按钮的事.
- 提早重视Release Engineering, 反而会降低成本.
- developers, SREs, and release engineers的合作非常重要, 而且release engineer也要去深入了解代码是如何编译和部署的.
Chapter 9 - Simplicity
The price of reliability is the pursuit of the utmost simplicity.: 有种代码越短, bug越少的意味…- 无聊是一种美德?? “Unlike a detective story, the lack of excitement, suspense, and puzzles is actually a desirable property of source code.” → sre的克星: 惊喜😂
- 不应该对没用的代码产生感情… 在生产环境, 每一行代码都应该是有意义的, 要是留很多没有的不会触发的代码(比如注释). 要Version Control System要何用呢?
- “software bloat”: 臃肿的项目.
- “perfection is finally attained not when there is no longer more to add, but when there is no longer anything to take away” - 和上一条有点类似, 如果暴露的API和参数越少, 就更容易理解. 除了问题也能更专注核心问题. less is more!
- 设计模块的时候一定要注意低耦合(大二软件工程学的, 虽然当时竟然觉得都是一些概念毫无用处). 一个好处就是: 当出了问题的时候, 可以在一个子系统中快速的解决并独立发布.
- “… it is also poor practice to create and put into production a “util” or “misc” binary. A well-designed distributed system consists of collaborators, each of which has a clear and well-scoped purpose.” - 真的吗?
- “Simple releases are generally better than complicated releases.” - simple is better than complicated, less is better than more. 文中的例子挺有道理的, 发布的时候, 发布时, 只有一个改动肯定比发布一百个没有关联的改动来的好. 因为出了问题, 一百个改动的就很难定位问题. 而且每次发布的东西少, 发布的时候也越自信, 最后达到小步快跑的效果😊.
- 总结: 只有保持simplicity, 才能保证reliability.
Part III. Practices
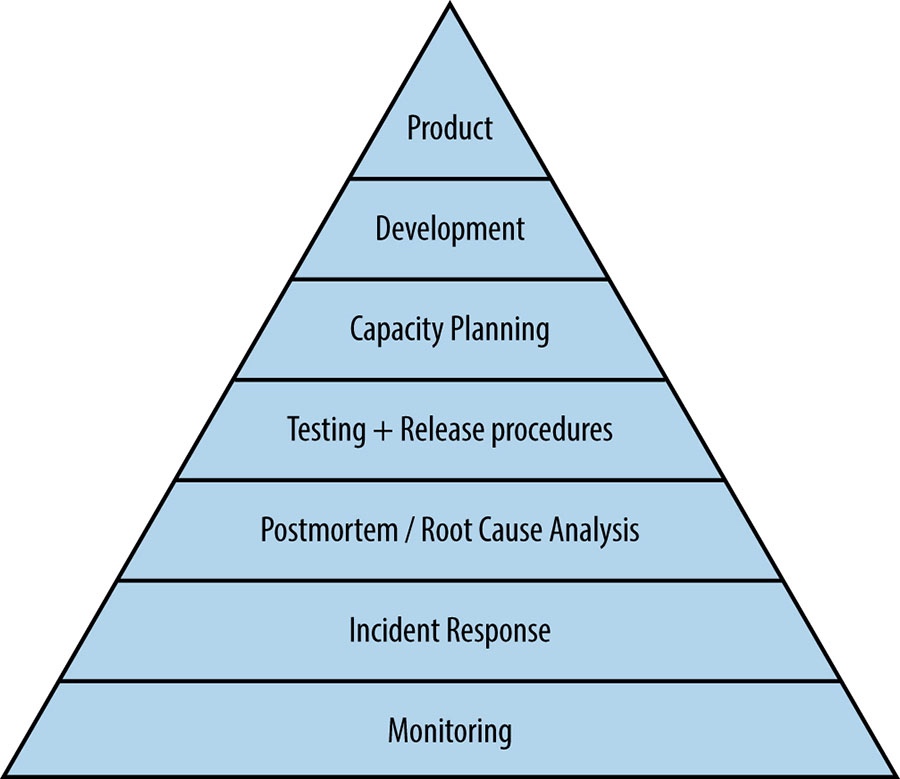
做了一个很有趣的比喻, 将如何运营好一个服务, 比做人类需求(五层次理论 - Maslow):
更有趣的是, 作者从底向上, 解释了模型的构成, 其中提到的各个子问题就对应第三部分的每一章节.
In an ACM article [[Kri12]](https://dl.acm.org/citation.cfm?id=2366332), we explain how Google performs company-wide resilience testing to ensure we’re capable of weathering the unexpected should a zombie apocalypse or other disaster strike.(????)
Chapter 10 - Practical Alerting
- “May the queries flow, and the pager stay silent.” XD
- 说到监控不仅仅是看一个请求响应的时间, 还可以分解并获取其中各个应用各个阶段的时间花费分布(比如公司内的的 Tracer 就能很完美的对每笔请求做阶段的分析).
- 黑箱和白箱监控:
- White-box monitoring: 从内部获取数据, 比如日志等.
- Black-box monitoring: 简单的说就是通过用户的角度去监控(比如应用宝)
- 日志系统Brog获取数据的基本用法:
{var=http_requests,job=webserver,instance=host0:80,service=web,zone=us-west} 10添加时间范围(最近十分钟), 就会出现十个值.:{var=http_requests,job=webserver,service=web,zone=us-west}[10m] 0 1 2 3 4 5 6 7 8 9 10还可以做aggregate:{var=task:http_requests:**rate10m**,job=webserver,instance=host1:80, ...} 0.9 - 监控系统Bornmon, 报警触发规则(配置), 慢慢形成了一门语言.. MaaS, Monitor as code 0.0
- 报警触发规则(语言)模版化的好处(提供很多现成的通用format的模版): 在一个新应用上线的时候, 会自带一些相联的基础配置, 添加新监控变得很简单. 最终使得维护难度不随系统规模线性增长.(之前也多次提到, 感觉是一个做SRE非常重要的原则, 感触颇深)
- 报警触发规则是语言, 就容易出现bug, 所以甚至提供了单元测试.
- 对于报警的处理(过去做了一段时间告警降噪,主要 focus 在对流量的算法分析,但其实如下合理的告警策略或事件告警聚合,也是另一维度,很有效的告警降噪):
- 严重紧急的报警发送给当前oncall工程师
- 重要但不紧急的发给工单
- 其他报警显示到dashboard.
Chapter 11 - Being On-Call
On-Call 对于维持系统稳定性来说, 是每个 SRE 工程师的重要责任(critical duty), 但存在几个大坑??, 会在下文中一一道来(如何保持reliable services and sustainable workload).
- “We cap the amount of time SREs spend on purely operational work at 50%; at minimum, 50% of an SRE’s time should be allocated to engineering projects…” - 相对于纯手工的工作,每个 SRE 至少抽出超过一半的时间做平台开发。之前的章节也反复强调过这个原则了。
- 计算 oncall 数量和质量的两个公式:“The quantity of on-call can be calculated by the percent of time spent by engineers on on-call duties. The quality of on-call can be calculated by the number of incidents that occur during an on-call shift.” 每个主管都有义务去根据这两个指标,量化并平衡 oncall 的工作。
- “multi-site team”, 好处是不用上夜班了,并且保证每个人都对生产环境保持熟悉感。但于沟通和协作会存在一定的困难(有业务团队在美国,确实会有这个问题,上班时间完美的错过了)。
- “Adequate compensation needs to be considered for out-of-hours support.” - 会对应急的同学提供适当的补偿是非常有必要的,例如 Google 会提供调休和金钱上的奖励。
- 应急需理性.. 因为直觉往往都是错的😂,所以要尽量减少应急人员的压力。文中提到了"Well-defined incident-management procedures”,蚂蚁有个专门的部门叫做 GOC(Global Operation Center),在应急的时候统一指挥,在这点做的还是挺不错的。但我认为更重要并有一定争议的一个原则叫做: “A blameless postmortem culture” / “focusing on events rather than the people”.
- “Finally, when an incident occurs, it’s important to evaluate what went wrong, recognize what went well, and take action to prevent the same errors from recurring in the future.” - 复盘很重要!
- “Recognizing automation opportunities is one of the best ways to prevent human errors” - 人类总是会犯错的,所以无论什么事,都可以提倡自动化。
- “Operational Overload” - 之前提到每个人的手动运维的工作不能超过 50%,但如果就是没控制过超过了呢?文中提到比如临时抽调一个有经验的 SRE 加入,但最理想的情况下,overload 的情况应该像业务系统一样可以被监控和第一时间发现。但是 overload 的原因是什么呢?一个主要的原因就是 “Misconfigured monitoring”

- “Operational Underload” - 总是说做了过多的 toil, 但如果生产环节如果太"安静“了(故障发生的频率并不是很高),导致应急人员手生了要怎么办呢? “Google also has a company-wide annual disaster recovery event called DiRT (Disaster Recovery Training) that…” Google 每年也会有演练,模拟故障。和蚂蚁的红蓝攻防一个意思。
Chapter 12 - Effective Troubleshooting(20190713)
“However, we believe that troubleshooting is both learnable and teachable.” - 有个比喻好形象,传授如何排查线上问题就像如何教别人骑车一样,只可意会不可言传~
- 文中总结了应急效率低的一些原因,感觉是一些挺繁琐的理论,但正是因为理性的分析支撑,才能更加科学的解决日常问题吧。
- “The system is slow → the expected behavior, the actual behavior, and, if possible, how to reproduce the behavior.” - 提问的艺术中也提到的「最小重现」。
- “Ideally, the reports should have a consistent form and be stored in a searchable location, such as a bug tracking system. Here, our teams often have customized forms or small web apps that ask for information that’s relevant to diagnosing the particular systems they support, which then automatically generate and route a bug.” - 所有历史 case 沉淀为知识库(减少重复的工作)。
- “Many teams discourage reporting problems directly to a person for several reasons:” - 例如出了问题,不鼓励直接找认识的 sre, 而是找对应本周值班的同学👍
- “Novice pilots are taught that their first responsibility in an emergency is to fly the airplane” - 经常听人提到的,应急中业务恢复止血永远是放在第一位的,而不是查找根因。
- “Ask “what,” “where,” and “why”” - 排查的时候,想清楚这几个问题,下次我也试试。
- “What touched it last” - 系统运行的好好的,为啥会出问题,肯定是引入了某些变更。现实中,绝大部分的故障是由于变更导致的。
- “Case Study” - 举了一个真实的故障 case, 描述的还挺引人入胜的,感兴趣的可以看一下。
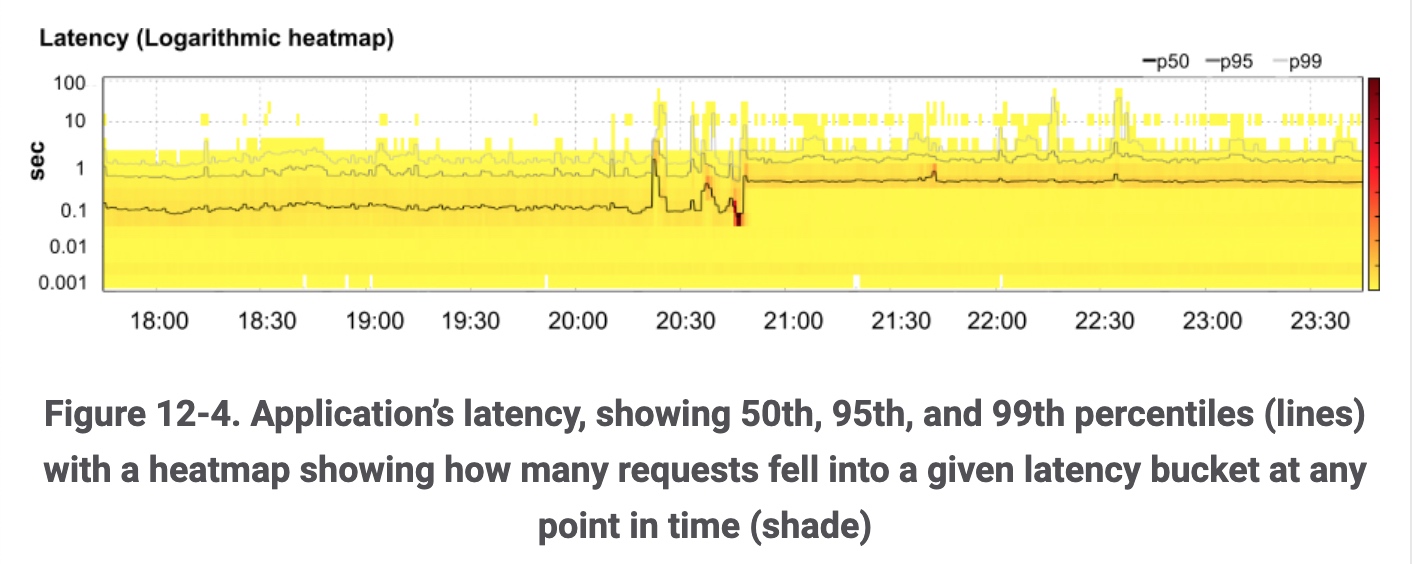
- “Application’s latency, showing 50th, 95th, and 99th percentiles” - 耗时的监控,99th percentiles 代表,假如整体样本如果有100个,排在第99的那个数值。还是挺有启发的,因为平均值很多时候会误导人。
Chapter 13 - Emergency Response(20190718)
这一章举了很多实际的例子, 来说明如何应急。
- “However, it should be noted that in this case, our monitoring was less than ideal: alerts fired repeatedly and constantly, overwhelming the on-calls and spamming regular and emergency communication channels.” - 故障发生时告警爆炸的情况,每个公司都会碰到,如果能比较好的解决也会带来很大的价值。
Chapter 14 - Managing Incidents(20190728)
公司有一个专门的组织叫做 GOC(Global Operation Center), 专门负责应急的调度和故障生命周期管理,不知道 Google 是怎么做的 🤔
- 举了一个故障应急的反例,然后列出了不足与应该遵守的一些原则:
- Recursive Separation of Responsibilities: 应及时分工分层需明确,又可以细分为一下几个角色:
- Incident Commander: 让我想到了公司的「值班长」
- Operational Work
- Communication: 这个角色有点像公司的 GOC
- Planning
- A Recognized Command Post: google 发现在处理故障的过程中,及时通讯软件很有用??不太理解。
- Live Incident State Document: 多人事实统一编辑故障的最新进展
- Clear, Live Handoff: 我理解更多是故障处理的交接吧。。但在国内的公司估计很难有这种情况。。
- Recursive Separation of Responsibilities: 应及时分工分层需明确,又可以细分为一下几个角色:
- “In many situations, locating the incident task force members into a central designated ‘War Room’ is appropriate.”: “War Room”.. 哈哈… 不就是我们的闭关室嘛 😂😂😂
- 针对文章开头的反例,又根据上面的几个原则,重新改造成了一个正确的例子。这个文章结构还是挺新奇的。但好多理论的东西,感觉有点虚。
Chapter 15 - Postmortem Culture: Learning from Failure
Postmortem 这个单词很有意思,中文里叫做「验尸」,而在公司我们通常把 Postmortem 称为复盘。“The cost of failure is education.” - 复盘很重要,就像文章开头说的,可以让我们在失败中不断学习,很多公司都有这样的文化,可以参考我最近写的一篇文章:《Cloudflare 全球宕机复盘读后感》
- 复盘的三个主要⚠️目的:
- 所有故障都有可以被文字的形式归档。
- 根因被理解并调查清楚。
- 设定对应 action, 防止犯相同或类似的错误。
- 写复盘不应该是一种负担或者惩罚,而是应该被当作一次珍贵的学习机会。 即使 tradeoff 是会消耗一些工作时间。
- 写复盘还有一个重要的原则是之前提到好多次的 blame free. 在公司参加过几次复盘,真的会变成甩锅大会(每个故障需要定责)… 简单说是浪费时间,但真正可怕的问题是有些被事实隐瞒了:“people will not bring issues to light for fear of punishment.”
- Google 的复盘模版:链接,从模版排版上可以看到,最重要的是 Root Cause & Actions,接着是 Lessons learned,最后是 整体的 Timeline.
文档是维护在 Google docs 上的,好处是可以支持多人实时编辑(上学的时间经常用,体验真的很棒.貌似yuque也在做这方面的努力,希望可以早日像 Google docs 一样顺滑)。但更加重要的是分享,尽可能越大范围的传播,每个读者都可以在上面评论与注释(这点公司因为权限的关系,感觉有点差异:“Our goal is to share postmortems to the widest possible audience that would benefit from the knowledge or lessons imparted.")。 - “Introducing a Postmortem Culture”:复盘应该是深入 SRE 血液的一种文化,而其中很重要的一点是协作和分享,例如可以尝试:
- 每月复盘集锦
- 线上复盘讨论小组
- 线下复盘学习俱乐部(reading club)
- 故障重演/演练(Wheel of Misfortune):真实重现故障,并让新人扮演当时对应的各个角色。
- 介绍了两个最佳实践:
- 大力奖励在应急中,有魄力做出正确决策的人
- 对于复盘的有效性,持续寻求反馈
- 总结:
- 感谢复盘的文化,让 Google 不断减少故障,并带来更好的用户体验。
- 但有个虚拟复盘小组发挥了很大的作用,例如统一了各个产品(YouTube, Google Fiber, Gmail, Google Cloud, AdWords, and Google Maps)的复盘文档模版,并支持应急中使用的工具,实现模版生成自动化,并可以抓取复盘的数据做趋势分析,等等。这不就是 GOC 嘛
- 积累这么多复盘文档后,如何挖掘这个宝库也是个很有价值的课题。目前可以做到自动聚类相似的文档,并且在未来会使用机器学习去根据复盘的知识库预测可能的缺陷和风险点,并实时分析事件,识别相同的故障并防止重复处理。
Chapter 16 - Tracking Outages
如果量化都做不到,何谈改进呢?稳定性也是一个道理。记得去年面试的时候,问了面试官,如何量化稳定性呢?对方笑了一下,说你听说过四个9或者5个9嘛?
“‘Outalator’, our outage tracker, is one of the tools we use to do just that. Outalator is a system that passively receives all alerts sent by our monitoring systems and allows us to annotate, group, and analyze this data.” - 和公司的故障管理系统的区别点在于,对于数据的接受和处理🤔。
- 复盘的局限性:对于很多小范围不严重的问题,无法覆盖。
- 有很多有价值的信息:例如每次 oncall 期间一共收到了多少告警?其中多少是噪音(nonactionable)?哪个服务创造的最多的 toil? 过去一年在公司搞的平台貌似也涉及到这部分 0.0
- 有个系统叫做 Escalator, 如果有些告警长时间没人阅读或处理,将会被降级,例如告警等级从 primary 变为 secondary(很不错的想法).
- “it is worthwhile to attempt to minimize the number of alerts triggered by a single event,” - 告警横向聚合为事件,也是一种关键的降噪方式。
- “Historical data is useful” - 文中更多的指的是数据的统计,例如每个月的故障数,各个故障的告警数,或是哪个服务或基础设施贡献了最多的故障,需要持续关注和改进。我们之前也有类似的想法,把所有故障和事件沉淀为知识库,抽象出一些特征值出来,例如监控(告警),订阅人,等等。相当于一个**「故障切片」**,当一个新的故障来的时候就可以快速匹配并给出最可疑的根因。
- “the Outalator also supports a “report mode,” in which the important annotations are expanded inline with the main list in order to provide a quick overview of lowlights.” - 这个和业务同学也聊过。。。尝试将对应告警聚合和事件关联起来,使用 tag 管理,最终调用在线文档 api, 自动生成对应业务的每周高可用报告。
- …
Chapter 17 - Testing for Reliability
- MTTR: Mean Time to Repair。MTTR 为零意味着上生产前,bug 就都被测出来了🤔。
- MTTD: 对应的发现时长: mean time to detect.
- smoking test: 冒烟测试,来源原来是电路测试中,如果通电后没有冒烟,表示一切正常可以继续。
- Stress test: 大促压测
- Canary test: 灰度环境测试,原来来源把一只金丝雀🐦放到煤矿中做测试,防止人直接吸入有毒气体。但值得注意的是灰度环境并不完美,无法检测出所有的潜在风险。
- (…看的头晕,不是很感兴趣,先跳过了)
Chapter 18 - Software Engineering in SRE
“Overall, these SRE-developed tools are full-fledged software engineering projects, distinct from one-off solutions and quick hacks” - 自己也亲身经历过一个很大的矛盾点:SRE 的职责是负责整个公司线上的稳定性,但可笑或者无奈的是,往往对于自己开发的工具或产品,无法保证高可用。这时突然想起《进化》中的一句话:“运维能力是整体技术架构能力的体现,运维层面爆发的问题或故障一定是整体技术架构中存在问题,割裂两者,单纯地看技术架构或运维都是毫无意义的”。
- “the vast scale of Google production has necessitated internal software development” - 和蚂蚁一样,google 大部分面向内部的产品都是自研的,因为外部开源项目的 scalability 等方面无法满足。而 SREs 则是开发这些产品的不二人选。
- “Google always strives to staff its SRE teams with a mix of engineers with traditional software development experience and engineers with systems engineering experience.” - SRE 需要不同背景的人才,而通过软件工程实践项目,减少 sre 工作量的同时,也是吸引和保留他们的重要手段。
- 花了大篇章幅描述了一个关于「容量评估」的 case study, 感兴趣的可以看看。
- “Because Google SRE teams are currently organized around the services they run, SRE-developed projects are particularly at risk of being overly specific work that only benefits a small percentage of the organization.” - 过去一年我一直在探索如何快速创造业务价值,但确实存在文中说到的陷阱:产品的 scope 过小,例如一个 sre 负责一条业务线,最后设计的方案只适用该业务线,假设每条业务线都搞个类似的方案,不可避免的导致 duplicated efforts and wasted time。所以最近也常常思考,方案如何跨团队复用,在整个公司成为标准,甚至产品化对外输出。
- “Dedicated, noninterrupted, project work time is essential to any software development effort.” - 挺新奇的一个论点,SRE 务必强行保留一些专注于写代码的时间,才可以开始思考如何在不停的打断和 on-call 中去寻求平衡。
- “Therefore, the ability to work on a software project without interrupts is often an attractive reason for engineers to begin working on a development project.” - 哈哈,想起之前的玩笑:“希望每天来到公司,戴上降噪耳机,不用和一个人说一句话专心写代码,直到下班”。玩笑归玩笑,同时一定要提防 sre 不能变成一个纯开发!因为需要对生产环境的深刻理解和独特视角,才能创造出一个为 sre 自身服务的优秀产品,去解决真正的痛点:“The unique hands-on production experience that SREs bring to developing tools can lead to innovative approaches to age-old problems”
- “Therefore, you’re working against the natural instinct of an SRE to quickly write some code to meet their immediate needs.” - 哈哈,完善的研发流程可能是必不可少的,但可能会违背 sre 的天性:因为 sre 都是快枪手,需要在第一时间止血解决问题,所以很多时候写代码也是一把梭,而这种不遵从软件开发规律偷懒的行为,最后反而会导致人力和资源更大的浪费。
- “SREs often develop software to streamline inefficient processes or automate common tasks, these projects mean that the SRE team doesn’t have to scale linearly with the size of the services they support.” - 回到 Software Engineering 必要性的问题,因为只有这样才能保证最核心的那个原则:业务的指数扩张与人员的增加不会成线性增长。最终每个 sre 员工,sre 团队,甚至整个公司都会因此收益。
Chapter 19 - Load Balancing at the Frontend
how we balance user traffic between datacenters: 本章主要讲 google 如何在 idc 外部之间做负载均衡。p.s. 下一章会阐述如何在 idc 内部做负载均衡。
- “when you’re dealing with large-scale systems, putting all your eggs in one basket is a recipe for disaster.” - 很简单的道理,不能把鸡蛋放到一个篮子里,即不可以存在单点问题(去中心化)。
- “The differing needs of the two requests play a role in how we determine the optimal distribution for each request at the global level” - 针对一个请求很难有最优的“策略”,因为会存在各种各样的变量。例如两个用户请求,分别是搜索和上传视频,前者追求的是更低的 RTT 以达到最快的响应,而后者则需要尽可能大的带宽。
- 负载均衡策略的又分为以下两种:
- “Load Balancing Using DNS” - 但 DNS 有各种限制,想到了阿里的 GSLB 智能解析,有空可以好好研究一下是如何解决这些限制的。
- “Load Balancing at the Virtual IP Address” - LVS, 转发的策略为
id(packet) mod N, 这样所有属于一个连接的包都被转发到对应的机器上,并且是无状态的方案:不用在内存中记录每个连接与机器的对应关系。看上去很完美?但想象 backends 中有一台机器挂了被移除或者新机器上线的场景,那不就全部错位了,需要从头开始 hashing (mod 就是一种最基本的 hashing),最后导致缓存命中率下降 db 负担增加。所以 1997 年的时候,提出了一种新的方案叫做 consistent hashing:看了一下简单说就是将输入的 id 分为 n 个区间(假设 id 是 32 位的,那它肯定有一个取值的范围,头尾相接刚好形成一个环),不同区间对应后台不同的机器,当上线或下线机器时,可以简单的分割或者合并区间。好美妙的算法,但如何保证不会出现热点问题呢?是不是在 consistent hashing 前要做一次预处理,以保证输入足够均匀。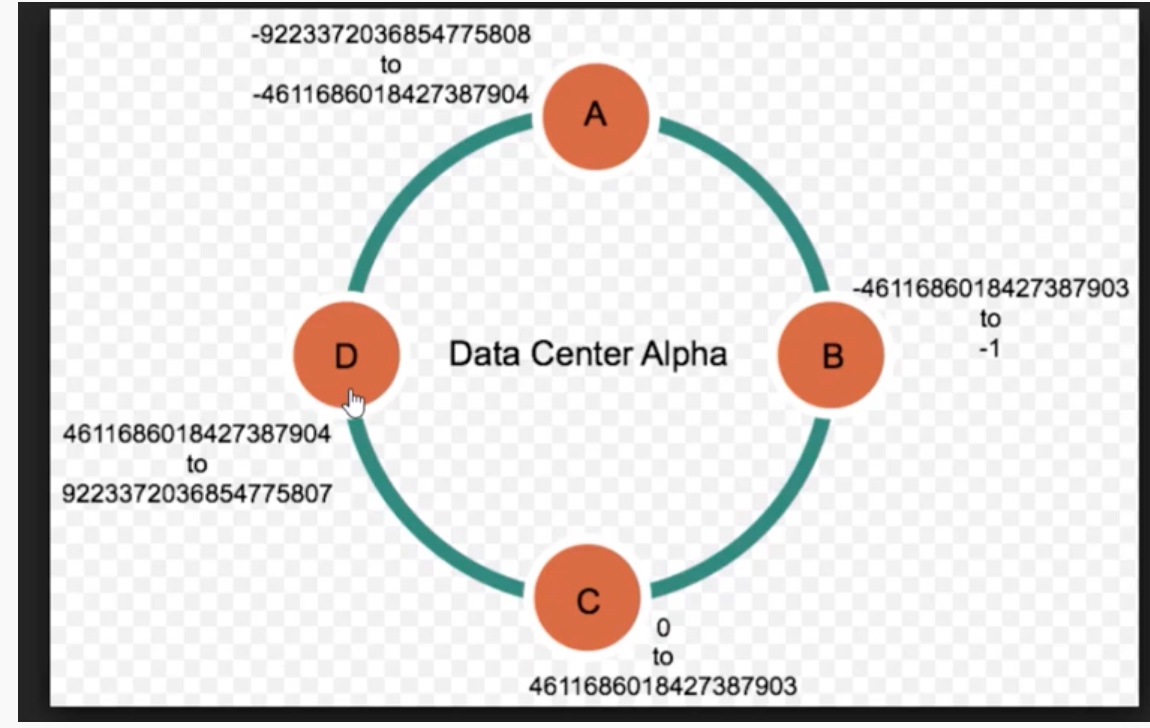
Chapter 20 - Load Balancing in the Datacenter
“This chapter focuses on load balancing within the datacenter.” - 紧接上一章,描述 idc 内部如何实现负载均衡,达到资源最优利用的目标。
- “Before we can decide which backend task should receive a client request, we need to identify and avoid unhealthy tasks in our pool of backends.” - 在做负载均衡之前,需要先找出不健康的任务并干掉。有分如下几种方法:
- Flow Control: 设定活跃连接数上限的阈值,但缺点也很明显,会导致机器的资源无法被完全榨干(静态阈值的局限性)。
- Lame Duck State: 为机器自身定义状态,分为 Healthy, Refusing connections & Lame duck(端口还可以继续接受请求,但明确告诉客户端不要再发送请求过来了)。但如何判断机器进入
lame duck state呢🤔?貌似是有一定的健康检查机制。这样的好处是提升用户体验,不会直接得到一个错误的响应。
- “A Subset Selection Algorithm” - 这部分有点复杂没太看懂,个人理解就是不同 Subset size 情况下(客户端),如何处理后端机器资源整体利用率与每台机器负载平衡的 tradeoff.
- 常见的负载均衡策略:
- Simple Round Robin: 大学里学的滚瓜烂熟,莫名的有一份亲切感。。这个算法简单且有效,但在现实复杂的场景下存在一定弊端,因为不同请求消耗的资源以及不同物理机可以提供的资源的存在巨大差异(varying query cost and machine diversity):例如上一章说到的 Google 搜索与 YouTube 加载视频的请求的差异;以及不同物理机 A 型号的 CPU 可能比 B 型号的 CPU 快两倍。如果你的负载均衡策略无法动态的处理各种无法预测的“变量”,那最终会导致后端机器负载极不均衡。接下来介绍 Least-Loaded Round Robin 与 Weighted Round Robin 两种算法,看看是如何解决上面的缺陷的🤔
- Least-Loaded Round Robin: 每个客户端各自记录,所以对应的后端任务的活跃连接数,每次选择连接数最小的那些后端任务进行轮询。但这个地方有几个坑,一是如果请求失败的话,例如 500 502 等是会立即返回的(在之前 99 分监控中也有一定涉及)并造成很大的干扰,其实也暴露出一个本质的问题:活跃的连接数并不等同于负载。还有就是客户端视角的活跃链接数并不能代表这个后端任务全部的活跃连接数。所以在实践中发现,这种负载均衡策略与 Simple Round Robin 效果一样差。
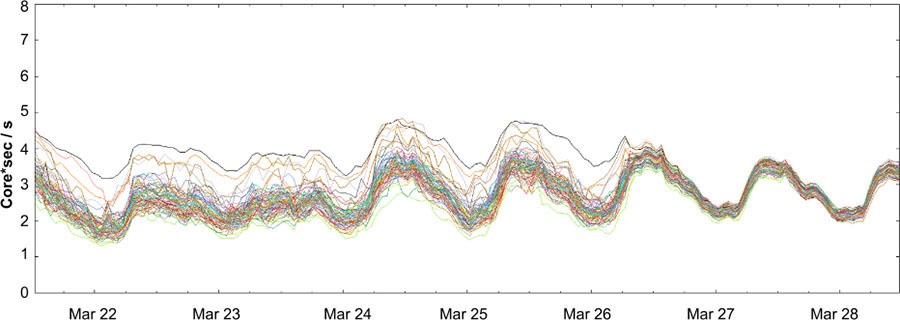
- Weighted Round Robin: 这个算法在负载均衡决策的时候,不再是无状态并不感知后端,而是需要后端提供一些自身的信息:每个机器给自己的容量实时自评(capability score),然后客户端定时的去选择最优的 backend task 处理请求。从下图可以看到,切换为这种算法以后,不同机器 load 的差异明显变小了,还是挺震撼的:
Chapter 21 - Handling Overload
不管负载均衡设计算法的多好,总不可避免会出现 overload 的情况(例如秒杀或者双十一的情况),优雅的解决这个问题是保证服务如丝般润滑的基石。
- One option for handling overload is to serve degraded responses - 一个选项就是对服务进行「降级」,例如依赖本地缓存返回结果,牺牲实时性来提升性能。但极端情况下,甚至连 degraded responses 都无法被返回,这时候的策略就是「限流」:对部分请求直接返回异常,来限制 idc 接收流量不超过它的上限。例如一个 idc 内有 100 个后端任务,而每个后端任务最高可以处理的 QPS 是500,那整个 datacenter 就需要限流 50,000 QPS,真的那么简单吗?
- The Pitfalls of “Queries per Second” - QPS 的陷阱🤔,我也想到了,毕竟上面提到过两遍了:Different queries can have vastly different resource requirements. 不管以什么静态的资源建模,总是不靠谱的,那怎么办呢?很类似上一章的 Weighted Round Robin,更加科学的做法是直接根据后端自身的实时可用的容量来决策:A better solution is to measure capacity directly in available resources.
- 限流又分为以下两种种:
- Per-Customer Limits: 在用户维度进行限流,例如 Gmail 每个用户最多只能消耗 4,000 CPU seconds per second. 但怎么实时计算每个用户当前消耗的资源呢?
- Client-Side Throttling: 思考这么一个问题,即使对用户维度进行限流,后端还是需要对请求处理,并返回响应(告诉用户自己无法处理了),结果大量的资源还是被浪费掉了(处理 HTTP 协议也需要消耗资源)。而客户端维度的限流可以解决掉该问题:当客户端检测到自己发起的大部分请求都被服务端因为 out of quota 被拒绝掉了,就直接不发起其请求了,文中把这种技术叫做 自适应的限流策略(adaptive throttling), 具体的实现参考下面的公式,计算后返回的结果叫做 Client request rejection probability:
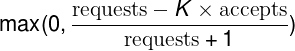 正常情况下 requests 和 accepts 是相等的(根据过去两分钟的数据统计),但后端任务开始拒绝请求时,accepts 就会比 requests 小,当 K 等于 2 并且 accepts 持续小于 requests 的一半时,就会直接在客户端开始限流(根据上图公式计算得出的概率)。当请求持续上升的时候客户端抛弃请求的概率也也会不断上升。但我理解在如果请求量减少的情况,后端任务的压力减少并可以正常处理请求的时候,i.e. accepts 大于 requests 的一半,客户端的限流又自动解除了,所以叫做自适应的限流,很酷哦 🤔
正常情况下 requests 和 accepts 是相等的(根据过去两分钟的数据统计),但后端任务开始拒绝请求时,accepts 就会比 requests 小,当 K 等于 2 并且 accepts 持续小于 requests 的一半时,就会直接在客户端开始限流(根据上图公式计算得出的概率)。当请求持续上升的时候客户端抛弃请求的概率也也会不断上升。但我理解在如果请求量减少的情况,后端任务的压力减少并可以正常处理请求的时候,i.e. accepts 大于 requests 的一半,客户端的限流又自动解除了,所以叫做自适应的限流,很酷哦 🤔
- Criticality - 每个请求可以被分为四种,很酷的想法呀,
- CRITICAL_PLUS: 最高优先级的请求,如果失败会严重影响用户的体验。
- CRITICAL: 线上请求的默认类型,同样会对用户产生严重的影响,只是没有 CRITICAL_PLUS 严重。
- SHEDDABLE_PLUS: 偶尔不可用是预期内的,例如批量离线任务,但后续会重试。
- SHEDDABLE: 可以容忍偶尔完全不可用的情况。
- We found that four values were sufficiently robust to model almost every service. - 刚在想只有这四个属性是不是不太够用。。文中也提高曾多次讨论要不要在上面四种属性之间增加更细的类别,但假如增加后会带来大量的维护的成本,并使得决策的系统变得过于复杂。
- A well-behaved backend, supported by robust load balancing policies, should accept only the requests that it can process and reject the rest gracefully. - 总结:一个 robust 的负载均衡系统,在瞬间流量激增的时候,都应该可以高质量的处理预期内的请求,并自动并优雅抛弃无法处理的请求。我们有个常见的误解一样,直觉认为机器过载了 hang 住了就是先把它下线呗,但理论上后端任务不应该在流量超过一定阈值的时候就完全崩溃(当然这里阈值也不能太极端了,例如超过正常的容量的 10 倍..)。
Chapter 22 - Addressing Cascading Failures
什么是 Cascading Failures 呢?举个例子,一个容器因为 load 过高挂掉之后,直接导致该集群剩余容器负载增加,最终形成多米诺骨牌效应:该服务所有实例 hang 住。这章就会讲如何解决这个问题。
- “Note that many of these resource exhaustion scenarios feed from one another—a service experiencing overload often has a host of secondary symptoms that can look like the root cause, making debugging difficult.” - 这个观点挺有意识的,大部分资源耗尽的场景,人看到都是表象(而不是根因),导致排查起来格外困难。例如下面这个 case(很难在第一时间定位到根因):
- 前端应用参数设置的不合理导致频繁的触发 GC
- 前端服务器 CPU 资源的耗尽
- 每个请求处理的耗时变长,导致服务中等待的请求越来越多 → 内存占用越来越高
- 缓存可以使用的内存也变得越来越少,自然缓存的命中率随之降低,越来越多的请求被发往后端机器。
- 最终后端某台机器的 cpu 资源被耗尽,健康检查失败,导致滚雪球般的崩溃。
- Preventing Server Overload - 如何避免呢?
- 压测:必须是在生产环境做压测,不然很难发现一条链路上哪个节点会资源耗尽,及崩溃后的影响。
- 限流 & 服务降级:例如 CPU,内存等指标表示负载达到一定上限,或某一时刻请求数量达到阈值时,自动抛弃一部分流量,达到自我保护的目的。还可以与 last-in, first-out (LIFO) 结合起来,直接抛弃不值得处理的流量(好可怜)。另外引入了一个概念叫做 Graceful degradation, 拿搜索服务距离,优雅的降级指的是,仅搜索内存中的数据,而不是全量搜索硬盘中的数据,牺牲搜索结果时效性,换取性能的策略。文中提到一个点挺有意思的,日常泡跑不到的代码分支(降级的情况),通常是无法正常工作的。所以需要定时的做演练保鲜。
- 在负载均衡的更上层系统拒绝服务,例如在反向代理对 ip 做限制等等
- 容量规划:降低 overload 发生的可能性。
- Queue Management - 队列是个对 overload 最符合直觉并有效的解决办法,但它本质上牺牲了 memory & latency, 并且存在一个常见的问题:queue 增长的速度大于消费的速度,越来越多的时间都在耗在排队中。文中推荐的最佳实践是 it is usually better to have small queue lengths relative to the thread pool size (e.g., 50% or less)
- Retries - 简单说,就是重试的次数一定有上限,并且时间的间隔必须是指数级增长的。
- Latency and Deadlines - 记得之前公司有个故障,一个弱依赖服务的超时时间比上游长,导致整条链路都失败了。但文中说到弱依赖时间设的过短可能导致失败的概率增加,需要找到那个平衡点🤔 针对上面说的故障,文中说的一个 Deadline propagation 还挺有意思的,通常一条链路为树形结构,每个节点的超时时间,是从底向上不断的传递并自动生成的,cool~
- “Slow Startup and Cold Caching” - 一个应用刚刚重启时,通常处理一个请求会比平时花费更多时间,还真是,还有最近遇到的一些应用一次启动需要十分钟。。造成这个现象的原因有很多,例如第一次连接的创建,类的延迟加载(java),还有缓存的预热,所以需要一些保护机制。
- “Load test components until they break. " - 太狠了,意思是需要找到那个崩溃的临界值或第一个挂掉的组件,这次压测才有意义。但如何在真实性和不影响线上用户之间做权衡,也是个不小的难题。
- “Test Noncritical Backends” - 即使是弱依赖也不能掉以轻心,甚至需要模拟下游一直不响应的场景,观察对主链路的影响。
- “Closing Remarks” - 当系统 overload 无法继续工作时,总是需要一些取舍的,但舍弃也是分优先级的,例如返回低质量的结果,而不是直接返回服务异常。
Chapter 23 - Managing Critical State: Distributed Consensus for Reliability
- CAP 理论,一个分布式系统无法同时满足下面三个属性。直白的说,如果两个节点之间无法通信(属性三),该系统将无法处理请求(属性二之可用性)或者导致返回的数据不一致(属性一)。
- Consistent views of the data at each node
- Availability of the data at each node
- Tolerance to network partitions
- “network partitions are inevitable” - 网络的中断是不可避免的,所以构建分布式系统就是处理好可用性与一致性。
- " BASE (Basically Available, Soft state, and Eventual consistency)” - 在 ACID 上对分布式存储提出一套理论。
- “eventual consistency.” - 一般根据 timestamp 选择最新的数据来实现最终一致性,当然也会存在很多问题,例如时钟偏离等。
- “Paxos Overview” - 大名鼎鼎的 Paxos 协议,浅显的理解一下。。第一阶段 proposer 发起投票(每一轮都严格对应一个 sequence number),如果大部分 acceptor 都同意这个决策,则进入第二阶段尝试让它们提交执行(并保存对应的状态)。但 proposer 是怎么选出来的呢?
- (…略…)
- “It should be noted that adding a replica in a majority quorum system can potentially decrease system availability” - 经常听到的一个词叫做三地五副本,文中也提到推荐推荐五副本的模式(增加一个副本也就是六副本可能反而会影响系统的可用性)。如果五副本中两个副本挂了,系统还可以正常工作(剩余的三副本形成多数派),也就是容忍 40% unavailable. 而在六副本的情况下,需要四个副本正常工作才能维持系统正常运行,也就是只能容忍 33% 的 unavailable.
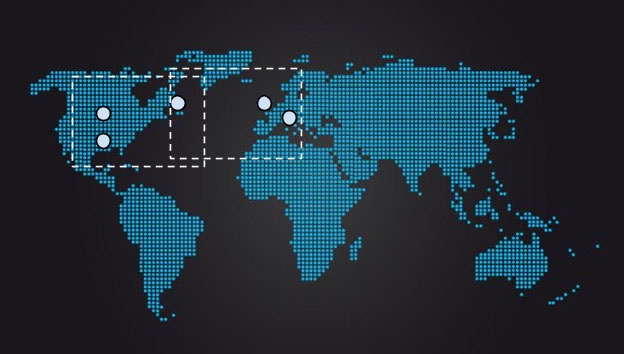
- “Such a distribution would mean that in the average case, consensus could be achieved in North America without waiting for replies from Europe, or that from Europe, consensus can be achieved by exchanging messages only with the east coast replica.” - 下图的部署模式不知道和我们常提的三地五中心是不是一个意思,好处在于每次的 proposal 只要左右三节点,任意一边能正常响应即可达成一致性。
- “We deliberately avoided an in-depth discussion about specific algorithms, protocols, or implementations in this chapter.” - 汗。。分布式真的是太复杂了,这章只看懂了 10%。结尾这段话,感觉自己被鄙视了:“If you remember nothing else from this chapter, keep in mind the sorts of problems that distributed consensus can be used to solve, and the types of problems that can arise when ad hoc methods such as heartbeats are used instead of distributed consensus.”
Chapter 24 - Distributed Periodic Scheduling with Cron
linux 上自带的 cron,蚂蚁的分布式系统定时调度 Scheduler,google 的分布式 Cron,分别有什么不同呢 🤔
蚂蚁的 Scheduler 有个很神奇的特性,最小刻度是秒,i.e. crontab 多了一位
- linux 自带的 cron 的高可用问题:1) 单点 2)无状态,例如机器重启过程中被漏掉的任务不会重新发起。
- “Cron jobs are designed to perform periodic work, but beyond that, it is hard to know in advance what function they have. " - 一个问题是用户设置的任务对于定时调度系统是是完全无感知的,例如日志清理或垃圾回收任务,可以容忍偶尔忽略执行,或者重复执行多次,但其他任务可能是百分百无法容忍的。但是一般来说,漏了一次比重复执行来的好 😂,不难理解漏发了邮件通知,总比发了两次容易补救。
- “In its “regular” implementations, cron is limited to a single machine. Large-scale system deployments extend our cron solution to multiple machines.” - 为了解决 linux 自带 cron 的单点问题,要将 cron 做成分布式到多台机器上。个人理解就是两个解耦:1)物理机器和服务的解耦,运行一个服务就像向「整个机房」发一个指令,底层自身保障高可用 2)状态和服务的解耦,由分布式文件系统(GFS)来保持状态,就算服务被迫迁移机器,也不会有影响。
- “Tracking the State of Cron Jobs” - 这个地方有两个选项:1) 分布式文件系统 2) 系统内部 但经过深思熟虑后,最终的决策是第二个,但刚刚不还是说放到 GFS 里吗。。原因一是 GFS 一般都是放大文件,不适合这类小型的写操作,延迟比较高。二是定时任务这类重要的服务,要存在尽可能少的依赖。
- “We deploy multiple replicas of the cron service and use the Paxos distributed consensus algorithm to ensure they have consistent state.” - 用了 Paxos 协议来保证一致性和系统高可用(一个 leader 多个 followers 的模式,故障时多数派选举 leader 自动切换)。
- “Beware the large and well-known problem of distributed systems: the thundering herd.” - 这个真的是学到了,例如大部分人配置每日执行的定时任务都会设置在凌晨零点执行:
0 0 * * *。理论上没有问题,但在大型系统中如果大量的任务在那个时间点同时触发,可能会瞬间原地爆炸,有个术语叫做 thundering herd,所以在 crontab 中引入了问号?,例如针对每日任务,代表可以在一天中任意一个时间点执行:0 ? * * *,来降低某些时间点的负载。
Chapter 25 - Data Processing Pipelines
介绍 Google 的 Workflow 系统,数据的流处理,不是很感兴趣,跳过了。。
Chapter 26 - Data Integrity: What You Read Is What You Wrote
尝试从数据完整性(Data Integrity)的角度,看我们的资金安全,会不会有一些启发?但貌似是完全不同的两个东西。
- “Now, suppose an artifact were corrupted or lost exactly once a year. If the loss were unrecoverable, uptime of the affected artifact is lost for that year.” - 像之前章节说的,我们通常用几个 9 来衡量服务的高可用能力,但对于数据完整性来说有些不同:假设某个用户有一份数据意外丢失并无法恢复时,对于该用户可用性就直接跌零了。
- “the secret to superior data integrity is proactive detection and rapid repair and recovery.” - 对于保障数据完整性最好的办法就是提早主动发现 & 恢复
- “No one really wants to make backups; what people really want are restores.” - 说到恢复,有一句话说的好:没有人真的在意那些备份,而是在乎出故障时是否可以将数据及时恢复。“When does a light bulb break? When flicking the switch fails to turn on the light? Not always—often the bulb had already failed, and you simply notice the failure at the unresponsive flick of the switch.” - 针对恢复的重要性在下面引申出另一个非常关键的问题,如何保证数据恢复的有效性?因为即使刚刚成功实施了数据恢复,也无法保证下一次就可以成功,所以需要对整个流程设计自动化的端到端测试,在灯泡故障时就立即告警,而不是在真正要用的时候才发现坏了。。
- “Combinations of Data Integrity Failure Modes” - 下面这张图还挺有意思的,从数据的生命周期看防止数据丢失的三道防线:1)Soft Deletion:保护用户侧的误删除,可以在回收站中直接恢复。2)Backups and Their Related Recovery Methods:热备份:保留一到两天的数据,可以联系管理员协助恢复。冷备份:3-6个月保存长期的数据,防止有些 bug 数月以后才发现并需要恢复的场景。3)Early Detection:越早发现,数据越容易恢复也越完整。
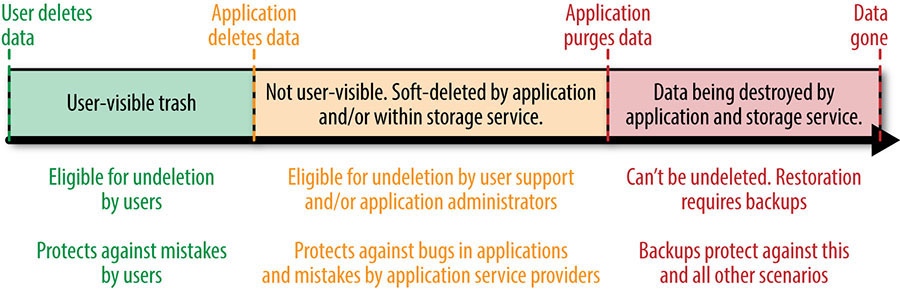
- 总结:
- 目标(数据快速恢复)比过程(数据备份)重要的多。
- 线上系统任意一个部分都有可能出错,所以必须找出所有维度的可能性进行排列组合,利用测试 100% 覆盖,并不断自动化回归,才能保障我们每天睡个好觉。
- 当针对各种意外,将数据恢复时间不断完善并接近于 0 的时候,可以将策略重心从恢复转向预防,最终目标是 all the data, all the time. “Achieve this goal, and you can sleep on the beach on that well-deserved vacation.” - 哈哈
Chapter 27 - Reliable Product Launches at Scale
“Site Reliability’s role in this process is to enable a rapid pace of change without compromising stability of the site. " - SRE 一个重要的职责,保障快速迭代与稳定性的平衡。本章主题是介绍 google 的发布协调小组和利用 checklist 来保障更快的迭代和发布新功能。
- “Launch Coordination Engineers (LCEs)” - 针对发布,google 有个专门的虚拟小组叫做发布协调工程师? who are either hired directly into this role, or are SREs with hands-on experience running Google services. - 我理解这个小组是由 SRE 的一个子集。
- “this team specializes in guiding developers toward building reliable and fast products that meet Google’s standards for robustness, scalability, and reliability.” - 这个 LCEs 小组的职责:
- 检查发布的内容是否符合公司的稳定性准则和最佳实践
- 在参与发布的多个团队之间进行沟通协调
- 针对开发者进行培训,利用文档等一系列的资源,使他们熟悉内部的各种服务
- “Google has honed its launch process over a period of more than 10 years. Over time we have identified a number of criteria that characterize a good launch process” - google 针对自己的发布已经打磨了超过十年,总结出一个好的发布流程有以下几个重要特性:
- Lightweight: 对开发者友好,简单易用
- Robust
- Thorough: Addresses important details consistently and reproducibly(不知道怎么翻译,对所有重要的细节都能从始至终的闭环解决掉?)
- Scalable: 可扩展性
- Adaptable: 适用性,对各种各样的发布类型都能做到兼容
- “As you can see, some of these requirements are in obvious conflict” - 挺有意思的,针对上面的几个原则,文中提到存在明显的矛盾,例如无法同时做到 lightweight and thorough. 为了解决这些问题,又搞出了几个策略:Simplicity / A high touch approach / Fast common paths. 总结一下就是针对通用的部分尽可能的进行抽象复用,例如在一个新的国家上线产品的流程,同时留口子供经验丰富的工程师自己去定制发布流程。
- “In a large organization, engineers may not be aware of available infrastructure for common tasks (such as rate limiting).” - 在大公司中因为信息不对称,经常出现重复造轮子的情况,例如限流功能等等。而在 google 几乎所有的团队都是使用的一个的发布流程,所以可以利用发布 checklist 这个卡点,促使大家遵循使用经过历史考验的标准组件,避免重复造轮子。 其实这个 checklist 在蚂蚁对应了系分(系统分析),技风(技术风险系分)和发布计划等,思路都是类似的。
- “Developing a Launch Checklist” - checklist 简单却有效,起草新产品的一份 checklist 都需要包含的内容如下(但如何保证用户认真确认并遵守呢?我们公司的发布平台也有类似的机制,但说实话我都没仔细看过,每次都是直接跳过):
- Architecture and Dependencies - 上下游依赖:例如分析从用户到最终的后端机器的请求流
- Integration - 需要集成的内部服务,例如域名 DNS 解析,负载均衡,监控等。
- Capacity Planning - 容量评估,会不会有活动?上线后的峰值和增产趋势?
- Failure Modes - 例如是否有单点的设计等等
- Client Behavior - 客户端侧的检查,例如某个链接对于用户的点击上限等
- Processes and Automation - 虽然提倡 DRY, 但自动化不是完美的,例如流程的推动等还是需要人工操作。为了防止人的单点问题,需要文档化。这样才能在紧急情况下继续运转。
- Development Process - 检查所有的代码和配置都有版本控制
- External Dependencies - 第三方依赖梳理
- Rollout Planning - 一次复杂的发布通常耗费很长的时间,而 PR 部门有一些变态的需求,例如在某页 ppt 的时候,发布某个新功能😂 针对这些发布中的风险点,需要提前好预案,例如准备 backup slide 来防止意外。
- “Google also uses version control for other purposes, such as storing configuration files.” - 熟悉的味道 XD
- Selected Techniques for Reliable Launches - 保障发布稳定性的一些技术手段:
- Gradual and Staged Rollouts: 只要灰度做的越精细,变更带来的风险也会降到最低。比如从一台机器开始,如果发现异常立即回滚。
- Feature Flag Frameworks: 针对某些小的特性,可以实现对用户的投放,优雅的从 0% -> 100%
- “Evolution of the LCE Checklist” - 随着公司的不断发展,线上环境日益复杂,checklist 也越来越繁重,LCE 也做了一系列努力让发布变得更轻量。其中一个手段就是对不同发布的风险进行分级,例如低风险的发布,只要通过简单的 checklist 即可发布,大约占到 30% 左右。
- “Problems LCE Didn’t Solve” - 文中提到也有一些尚未解决的问题:
- Scalability changes: 例如某个产品大卖,流量剧增,在不断开发新特性的同时,原先的架构已经变得非常复杂并难以维护。这时候只能重构了,但对应的迁移成本是巨大的,也会对新功能的迭代造成负面的影响。
- Growing operational load: 新功能发布后,后续的维护工作会变得越来越多,甚至包括那些自动化 pipeline 结束后的邮件通知 XD,会占据 sre 日常工作的越来越多时间。
- Infrastructure churn: 意思是说基础设施的变更,需要上层应用 owner 花精力去配合修改依赖或配置文件等等。所以要尽可能提供自动化的工具。
Chapter 28 - Accelerating SREs to On-Call and Beyond
本章主要讲了如何让一个 SRE 新手 newbie 快速开始进入 on-call 的队伍。曾有人说教游泳的最好办法是直接把那个孩子扔到水里,但文中并不太赞同这个观点,成为一名合格的 sre 需要体系化的学习和实践。
p.s. 之前在火车上读过这章了,忘记做笔记了,就先跳过吧。
Chapter 29 - Dealing with Interrupts
最近小明的公司故障频发,而遏制故障最佳的手段就是严控变更,甚至对每一个线上变更做人肉审批。虽然风险确实被控制住了,但 trade off 在于 sre 值班人员会被无穷无尽的“骚扰”。这一章讲的是 sre 如何处理 interrupts,还是挺期待的。
- “Any complex system is as imperfect as its creators. In managing the operational load created by these systems, remember that its creators are also imperfect machines.” - 人无完人,所以由人设计出的系统也永远不会是完美的🤔,人工的介入是无可避免的。就像开车一样,每隔一段时间需要做一次保养。
- “flow time” - 程序员的贤者时间 XD 突然好像有一丝共鸣,比如我自己写代码一般都会挑在深夜,比较容易进入「贤者时间」,保持极高的专注力与效率。
- “In order to limit your distractibility, you should try to minimize context switches.” - 描述的好形象,为了使程序员减少上下文切换(被打断去处理别的事情),要让 working period 尽可能的长。理想是一个星期,但一般实践是一天或半天。换句话说,就是在某个时间段,只专注于计划好的事情,例如安排下周负责 on-call, 那他只需要把这一件事情做好,不再关注别的项目:“A person should never be expected to be on-call and also make progress on projects (or anything else with a high context switching cost).”
- “handover process” - 不管是告警处理,日常的单子等等,都需要有完善的转派机制。
- “At some point, if you can’t get the attention you need to fix the root cause of the problems causing interrupts” - 有时候需要找到根因并彻底解决掉 interrupts 的源头。例如变更就是应该由系统保障的强制三板斧,去掉人工审批的环节,达到无人值守的目标。
- “A caveat to the preceding solutions is that you need to find a balance between respect for the customer and for yourself. " - 这里并不是说不尊重客户,而是像很多开源项目的 issue 管理一样,用户首选要对自己负责(现实中大部分人提问都是不经过脑子的),需要尽可能提供足够多的信息甚至最小重现的 case(提问的智慧),开发者才能产出高质量的回答并帮助解决。但现实中百分之九十的问题都是重复的,如何将它们沉淀下来也很重要的。
Chapter 30 - Embedding an SRE to Recover from Operational Overload
之前文中提到一个词叫做 toil, 而 sre 很容易陷入不停做 toil 的自我麻痹的快感中,看看这章是如何通过加入一个新的 sre 帮助团队从繁重的运维工作中解放出来的。
- “One way to relieve this burden is to temporarily transfer an SRE into the overloaded team.” - 抽调一个新的战力,加入到被运维重压下的 sre 团队。但不仅仅只是贡献人力,而是带来新的理念和更好的实践,来把 ticket queue 清空。
- “SRE teams sometimes fall into ops mode because they focus on how to quickly address emergencies instead of how to reduce the number of emergencies. " - 很有道理的样子,因为任何表面现象都需要去深挖根因,找到本质的问题。🤔 举个简单的例子,例如很多团队日常答疑很苦恼,表面上看是人手不足,但本质是排班机制或者自动化的能力不足,比如可用通过文档,历史提问,外包等等,一层层的防线,在保证咨询质量的同时,尽可能减少重复问题的处理。
- “Releases need to be rollback-safe because our SLO is tight. Meeting that SLO requires that the mean time to recovery is small, so in-depth diagnosis before a rollback is not realistic.” - 每个决策或者要求的背后都应该有强有力的逻辑支撑,才能让团队的每个人都心服口服的去执行。就算有一天你离开这个团队了,你种下的一些理念才会根深蒂固的继续执行。
Chapter 31 - Communication and Collaboration in SRE
相对于研发工程师,SRE 的工作比较杂,人员的背景也不同,甚至遍布于全球,所以内外部有效的沟通和协作十分关键。
- “One way to think of this flow is to think of the interface that an SRE team must present to other teams, such as an API” - 不同 sre 部门之间,研发与 sre 之间,好的协作模式就像设计良好的 API,可以高效的交流协作。这一点最近深有感触,例如最近发现某个应用的风险点,需要研发做代码改造,需要站在研发的位置思考,找对应的 owner 沟通排期,给出 roadmap,并每周监督,生怕放了鸽子。。理论上研发应该提供一个接受技术风险需求的 API, sre 输入各项参数发起请求,即可返回系分,测试,上线的各个时间点。
- …
Chapter 32 - The Evolving SRE Engagement Model
Engagement Model?? SRE 这个职位其实有个很大的「困境」:没有故障风平浪静时,好像没有人会想起你,但只要出了一个大故障,又好像全都是你的锅。这章我理解就是阐述 SRE 分别面对新旧业务时,如何参与其中保障线上稳定性,提升存在感,发挥我们应有的价值。
- “In the first case, just as in software engineering—where the earlier the bug is found, the cheaper it is to fix—the earlier an SRE team consultation happens, the better the service will be and the quicker it will feel the benefit.” - 不难理解 bug 越早发现就越容易修复,技术风险也是一样的道理,越早把风险扼杀在摇篮里越好。 让我想起了公司其他 bu 的一些实践:针对一些大的业务项目,SRE 甚至会从 PRD 就开始跟进,后续研发产出系分同时,SRE 产出技风(技术风险系分,有详细的模版,作用类似之前提到的 checklist),在整个开发生命周期都深度参与。也就是书中说的将风险扼杀在摇篮,本章结尾用了一个词叫做 “design for reliability”,还是蛮有启发的。
- “Simple PRR Model” - 书中有点过于理论,举个例子,某个产品 A 随着用户规模和盈利的不断增长,对应的研发人员已经对日常的告警处理和稳定性工作应付不过来了,需要 SRE 的协助。但这时候需要通过这个所谓的 PRR(Production Readiness Review) Model,完成以下六个步骤后才可以顺利接手(将生产环节的运维职责转移至 sre)。这个模型第一次听说,感觉有时候 sre 确实需要“强势”一些。
- Engagement 决定团队,启动制定对应的 SLO/SLA 等等
- Analysis 根据历史最佳实践,分析潜在风险
- Improvements and Refactoring 协作重构提升稳定性解除
- Training -> Onboarding -> Continuous Improvement
- “Early Engagement” - 上面模型的进化,顾名思义,在开发的生命周期的初期就开始让 sre 融入其中。最终的目标都是一致的,可以更好的接管线上。好处见第一条就不重复了,但需要识别有价值的重要项目的眼光。
- “Toward a Structural Solution: Frameworks” - 随着业务的发展,如果持续使用上一条的模式,SRE 永远都是不够用的,需要不断的向以下几个原则靠齐:
- Codified best practices: 将最佳实践代码化,实现不断的沉淀和复用
- A common production platform with a common control surface: 拒绝非标,幸福你我他
- Easier automation and smarter systems: 自动化智能化,例如故障发生时,快速将所有相关的监控数据,报错日志,近期变更等等都自动汇集到一个页面,这不就是我们去年想做的智能应急工作台 😂
- “The original SRE engagement model presented only two options: either full SRE support, or approximately no SRE engagement.” - 如果你想得到 sre 的线上支援,就必须 follow sre 设计的框架和一系列标准。这样让研发只需要专注于业务逻辑的开发,减少 SRE 工作量的同时,保障了线上稳定性。
- Simple PRR Model / Early Engagement / Frameworks for production services:三种模式不断演进进化而来,也是同时共存的关系。但最后一种 Frameworks 的模式,就是将最佳实践代码化标准化,才能最大化发挥 SRE 自身的价值,不断提高线上环境的质量。
Part V. Conclusions
进入最后两章,将 SRE 与其他重视稳定性的行业相比较,个人感觉确实会存在大量的相似之处。
Chapter 33 - Lessons Learned from Other Industries
其他行业例如民航公司,是如何保障稳定性的呢?毕竟如果网页宕机了只是影响用户体验造成舆论危机,但假设波音 737 出了问题,那可是几百条人命。本章总结了一些最佳和最差实践。
- 员工的背景都挺有趣的,有国防部任职的,救生员,激光手术(视网膜)软件设计,核电行业的安全顾问,核潜艇工程师等等,这些行业对可靠性都有着极高的要求。
- 从下面四个关键点看可靠性:
- “Preparedness and Disaster Testing” - 又引用了这句话,Hope is not a strategy. 就像同事经常说的,做稳定性就看我们想的多不多,准备了多少对故障进行预防,并不断的通过演练去验证。
- “Relentless Organizational Focus on Safety” - 从组织层面对线上安全进行重视,引用 CTO 鲁肃大大的最近的一句话:无论走到哪里,对技术团队来说,最重要的永远是稳定性,技术团队有很多坚持的原则,但是稳定压倒一切是第一原则。
- “Attention to Detail” - 例如在核电潜艇行业,对添加润滑剂这个微小细节的忽视,都会造成非常严重的后果。
- “Swing Capacity” - 在通信行业,流量是很难预估的,所以要做到动态可伸缩。
- “Simulations and Live Drills” - 各个行业都需要线上的演练来保证人员的熟练度,就像蚂蚁的红蓝攻防,甚至提到游泳馆的救生员,也会有人故意落水来对他进行考核和训练,类似于餐饮业的神秘顾客 :)
- “Defense in Depth and Breadth” - 纵深防御,文中提到核电站的多层防御和隔离,不难理解对核故障是零容忍的,类似公司经常提到的四道防线。
- “Postmortem Culture” - 任何行业在真正的灾难发生前,都会有类似的小事故多次上演,我们需要抓住这些机会不断的进行学习和优化。文中救生员半开玩笑举的例子挺形象的:只要我们有一只脚踩入了水中,就会有大量的报告需要填写 😂 这样当真正重大的事故发生时,还是能遵守对事不对人的原则,甚至会让对应的救生员接受心理辅导,你已经尽力了。
- “Automating Away Repetitive Work and Operational Overhead” - Never repeat yourself, 不管是不是 sre 应该对所有重复性的劳动都进行抵制,不难理解只要是人总会犯错。
- “Structured and Rational Decision Making”
- data is critical, 让数据说话做决策。
- if it works now, don’t change it. - 其他行业的一个不同,最近我也在思考的一个问题,如果这个一段代码跑的好好的,为什么要去动它呢?但这样肯定是不对的,暴露了投入产出比无法量化的问题。
- 文中提到的交易行业例子挺有趣的,当系统出现异常时,独立的风险控制部门会直接把整个系统关闭,不进行交易至少就不会亏钱。。 想到之前章节提到的 error budget,是不是当用完的时候就封网禁止线上一切变更 😂 没变更就不会有故障。
- “Preparedness and Disaster Testing” - 又引用了这句话,Hope is not a strategy. 就像同事经常说的,做稳定性就看我们想的多不多,准备了多少对故障进行预防,并不断的通过演练去验证。
- 总结:SRE 与不同行业的稳定性相比,确实在核心原则上基本大同小异,但有个很大不同的是 velocity,因为相对于核电站,人员安全排在第一,对故障零容忍,系统设计好就尽量不去变更;但现代互联网公司讲究的是以快制胜,快速变更创新的同时利用 error budget 保障线上稳定性。
Chapter 34 - Conclusion
领导发言总结,鼓掌👏👏
假如你对文中的 SRE 理念比较认同,并想了解支付宝的每一笔交易付款中都发生了什么,如何做到如丝般顺滑,不妨关注一下我们的招聘。
工作地点:杭州 / 上海 / 深圳 / 北京
招聘目标:技术风险研发工程师 / DBA / 资金安全架构师 / 高可用架构师
岗位要求:见链接
欢迎发送简历到 daya0576[AT]gmail.com 联系内推。