最近看了django关于性能优化的文档: 链接🔗
整理了一下笔记, 并写下几点比较深的感触和我优化django代码的总结.
你的时间才是最宝贵的:
文档里的这句话还是挺有意思的(自己的时间和性能优化的trade-off): Your own time is a valuable resource, more precious than CPU time. Some improvements might be too difficult to be worth implementing, or might affect the portability or maintainability of the code. Not all performance improvements are worth the effort.
最重要的原则: Work at the appropriate level
意思就是说要在对应的level(M V C)做对应的事. e.g. 如果计算court, 在最低的数据库level里是最快的 (如果只需要知道此记录是否存在的话, 用exists()会更快).
但要注意: queryset是lazy的, 所以有时候在higher level(例如模板)里控制queryset是否真的执行, 说不定会更高效.
下面这段代码很好的解释了不同level的意思:
1 | # QuerySet operation on the database |
用database中传统的优化手段
- 加索引. 对你经常要用的字段进行加索引, 会大大的提升查找数据(filter(), exclude(), order_by(), etc.)的速度, 毕竟O(1)或O(logn)对于O(n)相差还是很大的.
- 使用合适的字段类型. 例如你的数据多到几亿条了, 合适的字段也会帮你节省很多的空间.
理解Django中的QuerySets
对于queryset lazy特性的说明:
这段代码看上去对数据库进行了三次查找, 但其实只在最后一行的时候执行了数据库的操作.
1 | q = Entry.objects.filter(headline__startswith="What") |
那么问题来了, 既然queryset是lazy的, queryset什么时候会被evaluate呢?
- Iteration, ie. 对Queryset进行For循环的操作.
- slicing, e.g.
Entry.objects.all()[:5], 获取queryset中的前五个对象, 相当于sql中的LIMIT 5 - picling/caching
- repr/str
- len (Note: 如果你只想知道这个queryset结果的长度的话, 最高效的还是在数据库的层级调用count()方法, 也就是sql中的COUNT(). )
- list()
- bool()
以上的情况一旦发生, 就会查询数据库并生成cache(生成的cache就存在这个queryset对象之内的), 之后再对queryset做以上的操作就就不用再重新hit数据库进行查询了.)
**举个栗子: **
1 | queryset = Entry.objects.all() |
注意! 不会cache的情况:
Specifically, this means that limiting the queryset using an array slice or an index will not populate the cache.
意思就是说queryset[5]和queryset[:5]是不会生成cache的. 还有exists()和iterator()这样的也不会生成cache.
举个栗子:
1 | queryset = Entry.objects.all() |
最近发现values和values_list这两个方法也会重新查询数据库, 不知道是为什么.
TODO: 有空看一下 具体的实现原理.
研究的结果:
当调用values或values_list的时候, 会生成一个新的queryset with no cache.
也就是说, 除了上边说到的七种会产生cache的情况, 其他都会重新去数据库拿数据.
数据库层级的优化的总结
官方的文档介绍了很多, 我写几点最有效的和最常用的:
- 利用queryset lazy的特性去优化代码, 尽可能的减少连接数据库的次数.
- 如果查出的queryset只用一次, 可以使用iterator()去来防止占用太多的内存, e.g.
for star in star_set.iterator(): print(star.name).
感兴趣可以看看ModelIterable中重写的__iter__方法. - 尽可能把一些数据库层级的工作放到数据库, 例如使用filter/exclude, F, annotate, aggregate(可以理解为groupby), etc.
aggregate: https://docs.djangoproject.com/en/1.11/topics/db/aggregation/#cheat-sheetF: getting the database, rather than Python, to do work - 一次性拿出所有你要的数据, 不去取那些你不需要的数据.
意思就是要巧用select_related(), prefetch_related() 和 values_list(), values(), 例如如果只需要id字段的话, 用values_list('id', flat=True)也能节约很多资源. 或者使用defer()和only()方法: 不加载某个字段(用到这个方法就要反思表设计的问题了) / 只加载某些字段. - 如果不用select_related的话, 去取外键的属性就会连数据再去查找.
- bulk(批量)地去操作数据, 比如
bulk_create - 查找一条数据时, 尽量用有索引的字段去查询, O(1)或O(log n) 和 O(n)差别还是很大的
- 用
count()代替len(queryset), 用exists()代替if queryset: - ...
一点感想: 个人觉得ORM至少能 cover 95% 操作数据库的需求, 就像常常有人抱怨python慢一样, 绝大部分的情况是代码写的有问题罢了.
解决性能问题的具体方法:
原生的explain方法:
1 | print(Blog.objects.filter(title='My Blog').explain(verbose=True)) |
connection.queries 方法
可以利用这两两句代码来分析你的代码的sql执行情况和花费时间:
1 | from django.db import connection |
django-debug-toolbar
一个在github上有四千多个星星的开源项目: https://github.com/dcramer/django-devserver
很棒的一个可视化的工具, 但缺点是只能处理text/html类型的response, 因为是通过中间件修改返回的html代码实现的.
解决办法: 可以再使用这个库: django-debug-panel,
再配合链接中最后的chrome插件使用, 就可以查看所有异步请求的详细信息!
如图: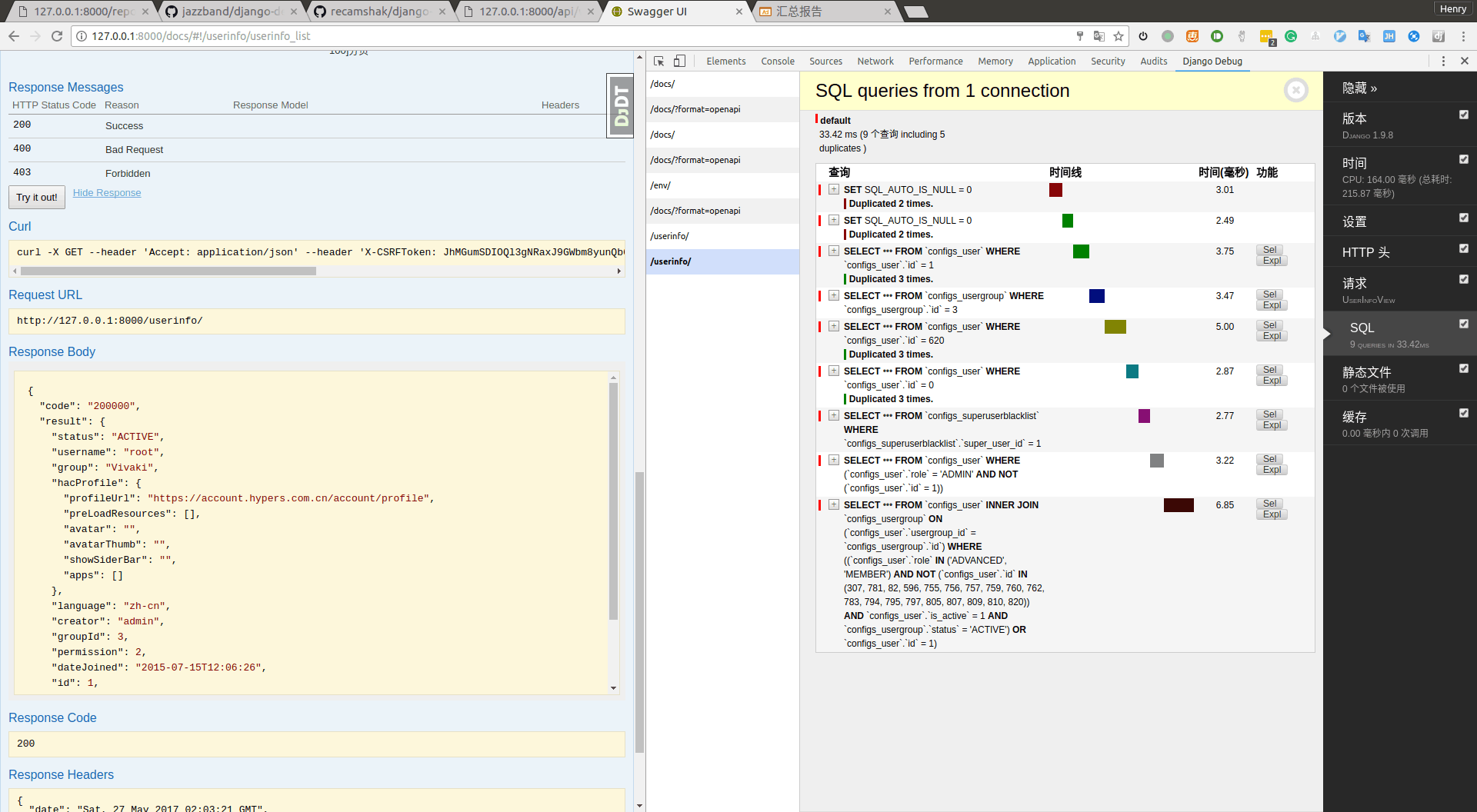
优点:
1. 统计了总的SQL查询时间.
2. 重复查询的sql的数量, 在每条sql详细信息中显示重复的次数.
3. 执行sql的具体代码位置!!!
4. sql 语句的高亮
5. sql 查询到的数据结果.
配置参考:
1 | # debug_toolbar settings |
django-devserver
项目github主页: https://github.com/drinksober/django-devserver
这个项目好久没有维护了..已经跑不起来了. 可以试试同事的修复版:
https://github.com/drinksober/django-devserver
line profiler:
其实最好用的还是用line profiler去找程序的瓶颈:
效果如图所示, 显示了一个方法内哪行代码运行的时间最久: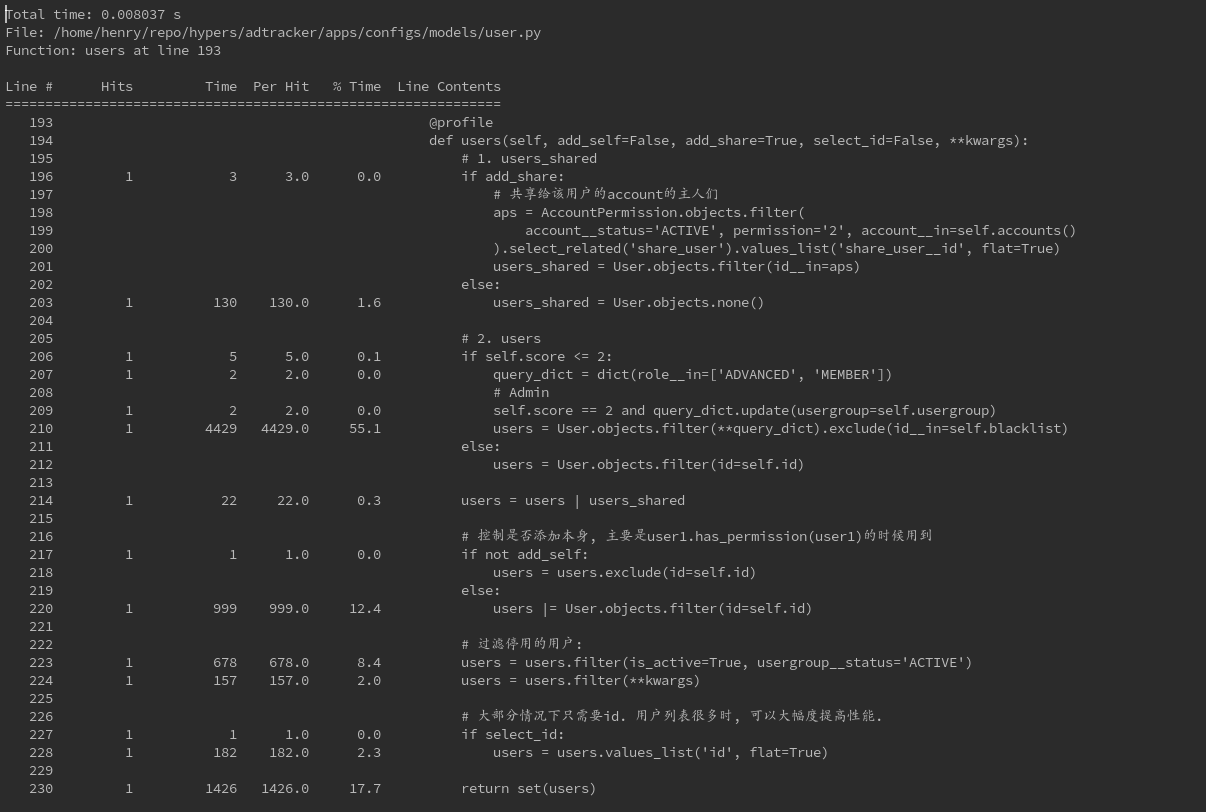
使用方法(从同事黄俊那偷来的代码):
1 | class Line_Profiler(object): |
举个栗子:
最近重新写了一个项目里很常用的方法(之前也是我写的, 但感觉稍微有些慢), 利用上文说的一些知识, 把执行时间从200多ms降到了20ms.
1 | def users(self, add_self=False, add_share=True, select_id=False, **kwargs): |