
GitHub: https://github.com/daya0576/beaverhabits/
Demo: https://beaverhabits.com/demo/
GitHub: https://github.com/daya0576/beaverhabits/
Demo: https://beaverhabits.com/demo/
从上海出发,两小时的飞行到首尔仁川机场(Incheon International Airport),后三天乘坐 KTX 到达釜山(Busan)。
虽说五一出行,但奇怪海关出境通道处,行人稀稀拉拉少的可怜。或是因为出关自动化效率极高。
北京时间下午五点左右的飞机,由于一小时的时差,八点抵达灯火通明的首尔:
落地后比较扫兴的是,入境处“外国人”多的吓人,欧美,日本,再加上书包上挂着爱豆卡通头像的“小朋友”。足足排了两个小时才顺利入境,抵达酒店时已是首尔时间凌晨。
p.s. 国内社交媒体上,充斥着韩国人歧视外来游客的言论,但实际体验下来倒是有一些出入,除了买衣服试了三件没买营业员逐步拉下来了脸,无论是酒店入住、便利店、餐厅、以及路人问路,都表现出专业的热情和发自内心的友善 :)
路上刷 Klook 时,意外注意到首尔排名榜首的活动是 DMZ (Demilitarized Zone),果断报名参加学习大韩民国近代史:
害怕听不懂英文被突突突,故报名中文团(相比英文团费用多出 30% 左右)。分配的导游是个会讲中国话的韩国女生,她的中文非常流利,但有趣的是,独特的口音一开口便让人知道她是韩国人。
次日清晨八点弘大地铁站大巴集合后,准时出发。坐在后方的是三个台湾大学生,一路“靠北”的欢快交流着,迎面扑来的青春感。驱车一小时抵达终点,下图中红蓝粗线之间便是 DMZ: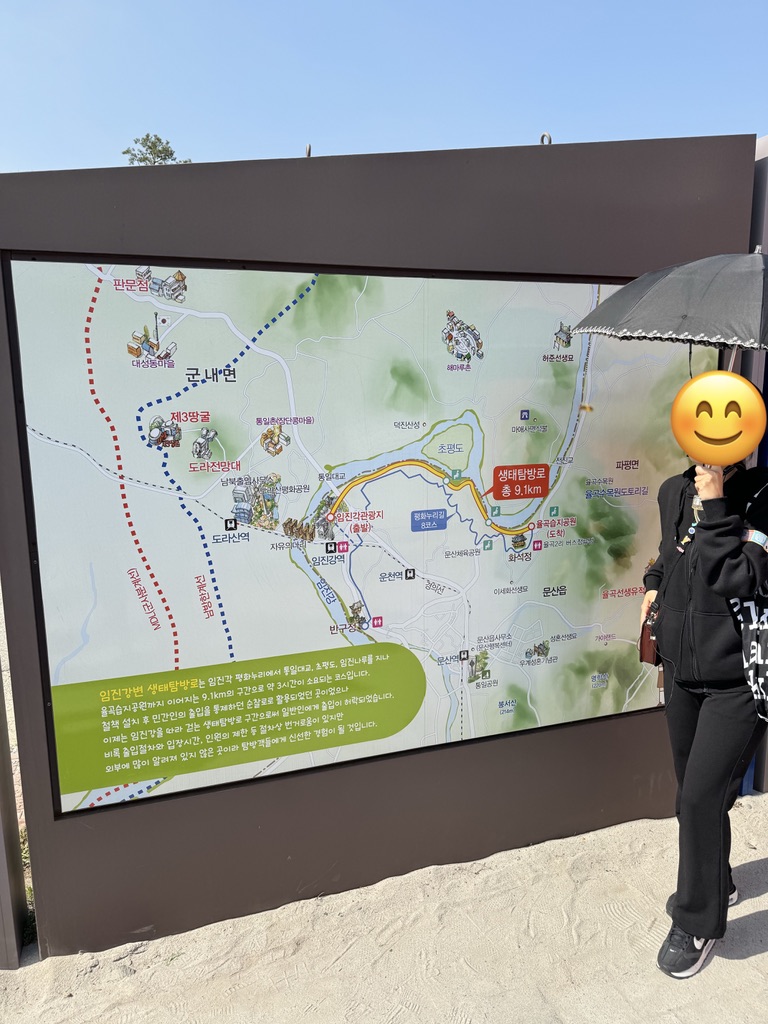
而上图细线虚线内则是军事区,所以大巴驶入时,会有韩国军人上车依次检查护照。满满的仪式感,实则是因为出现过游客反向操作,偷偷跑至北韩的事件...
本趟 tour 最大的卖点竟然是瞭望台,通过望远镜“观察”神秘国度的生活日常。
来自世界各地的国际友人
第一次遇见免费的望远镜 =。=
除了瞭望台,另一个项目则是参观第三地道(第三个发现的疑似北韩挖掘的隧道),由于进入时不允许携带手机等电子设备,盗图一张供参考。实际体验一眼难尽,只能说是一场不错的 physical exercise。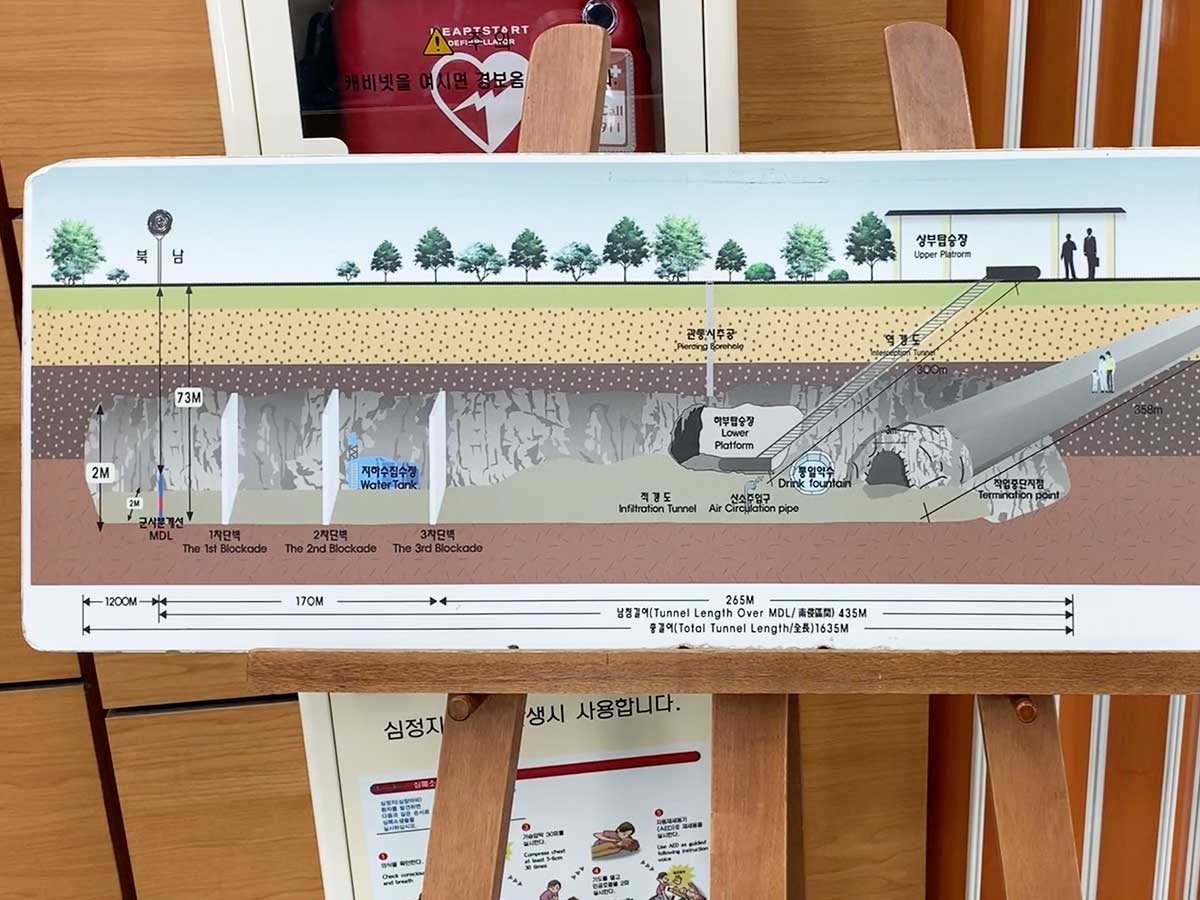
旅程结束时,导游眼汗泪光发自内心的感叹,希望有一天南北和平统一。参考KBS特别广播电视节目《寻找离散家属》,10189 名离散家属通过电视节目中,与他们的在战争中走散的亲人相见。可惜由于各种原因,两个国家越走越远...
微妙的 DMZ 冒险告一段落,继续向青瓦台前进!
青瓦台从 1948 年为总统府,在 2022 迁往国防部大楼后,开始对外开放,参考 青瓦台,回到国民的怀抱中。
通过官网提前预约,或当场注册即可进入参观:
《首尔之春》中的“革命者”:
设置了特定的拍摄点,禁止在楼梯上进行摄影。
气派的外宾接待处:
出口处悠哉的小猫咪☺️:
辛苦了一天,以一顿丰盛的晚餐结束(효자왕족발)
酱肘子配上大蒜,再来一口传统米酒... 😮😲🤯😍😋😋🥰🥰🥰🥰
晚上未安排行程在酒店小憩。
老婆大人则去体验了本地的 tony 老师,效果拨群韩味十足,只可惜第二天就打回原形 :)
值得一提的是,在旅程过程中,手机经常收到告警,例如老人走失或极端天气,不清楚是根据定位还是批量推送: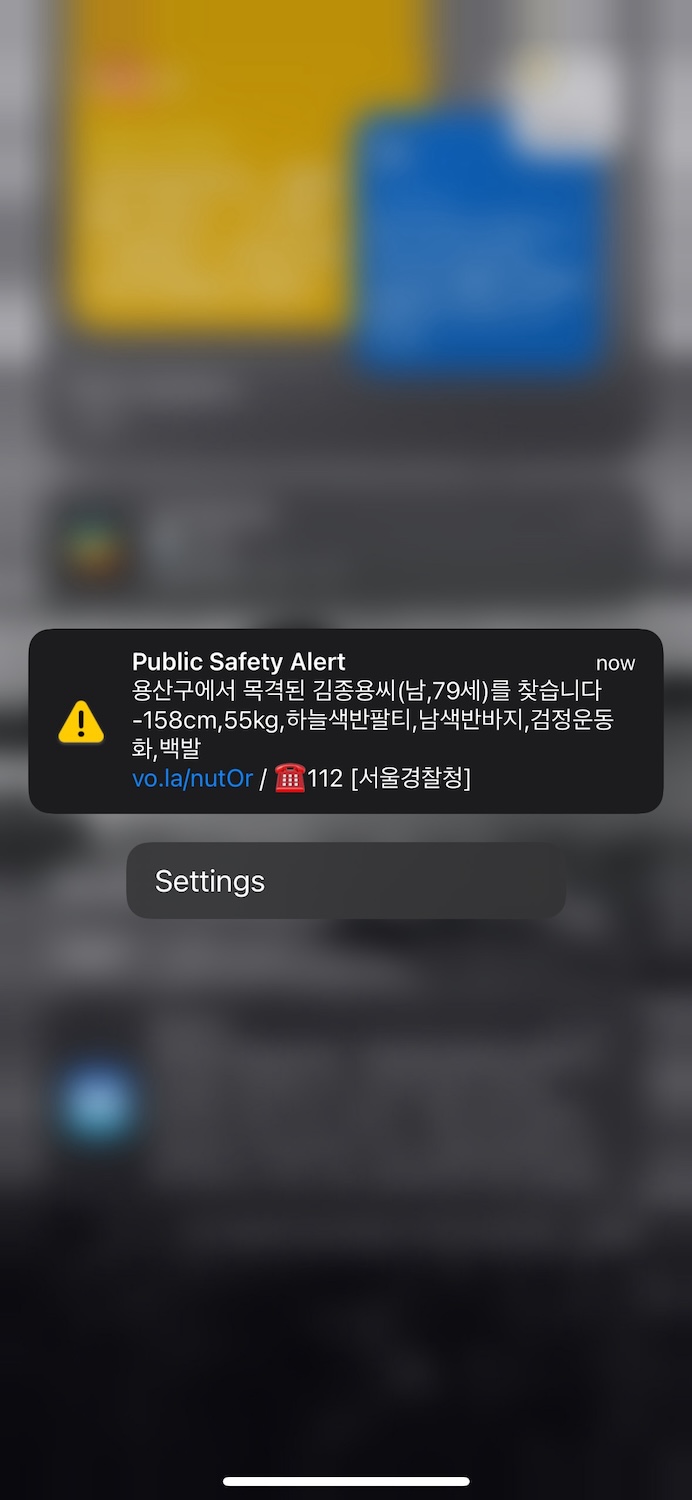
今日发出汉南洞,轻松购物的一天。
人山人海的潮牌店🤔,但排队的人群中,国人占据九成以上:
虽然今天主打陪伴,大部分时间寄存在咖啡厅摸鱼的一天🤪,但大部分的店比较好逛收获颇丰。
午餐是中规中矩的铁板章鱼🐙,性价比一般就不推荐店铺了。倒是用餐结束后,会用米饭继续炒饭,谁能拒绝碳水的快乐...
晚上乘坐 KTX(类似国内高铁),历时接近 3 小时到达釜山。对。。就是《釜山行》中的那趟列车。。。
整体乘坐体验丝滑无比,没有安检,也没有检票,一路畅行。 行驶过程中车厢乘客安静的可怕,害得我咀嚼蛋挞也不敢用力。
值得一提的是,今日早餐尝试了 Dunkin' Donuts 的现做“汉堡”?味道好极了
吃饱喝足地铁出发 Blueline Park。遗憾未预约到胶囊小火车(Sky Capsule),不如沿着海边徒步也是极好的: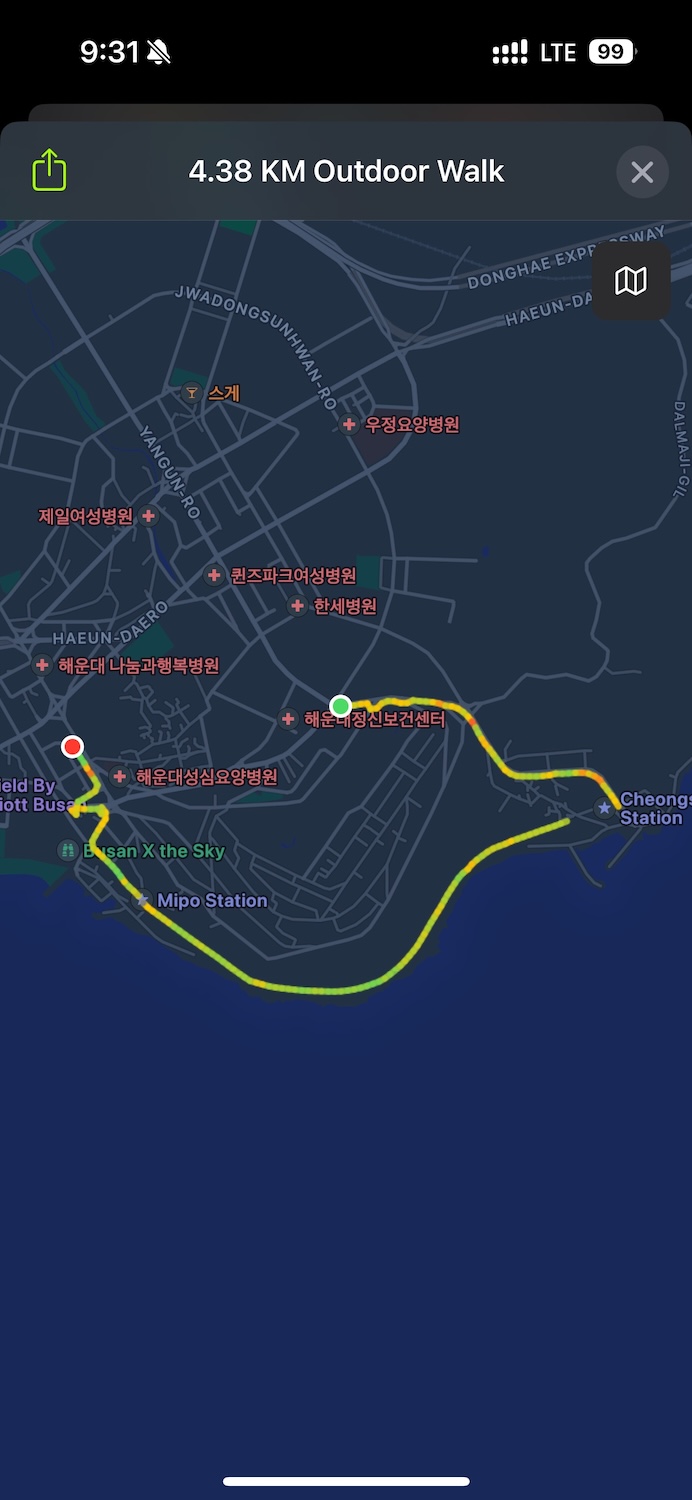
可惜天不作美,陆陆续续下着大雨,虽然撑着伞但也淋成了落汤鸡 🤣
辗转偶遇一家不起眼的满分本地美食 😍😍😍 一口泡面忘却所有的烦恼。
印象深刻的全自动化泡面机器:
吃完之后,只想和图中老奶奶一样双手点赞👍👍
韩国本土的桑拿也是这次旅行的必选活动,启程 Club D Oasis SPA 放松一下。
缴费 -> 寄存鞋子 -> 更换衣服 -> 进入桑拿区。
不同的桑拿室对应不同的温度供选择,害怕不小心烤焦,选择新手区躺倒小憩半小时。身体仿佛开启了快充,迅速 100% 恢复体力💪
当然少不了经典水煮蛋 🥰
p.s. 强力推荐 iOS 自带的 translation 工具,不论是扫描还是拍照,基本秒级展示准确结果:
住在 Busan station 附近,地铁两站便抵达 BIFF Square、国际市场、Fish Market 等景点。
猜猜是谁的手印:
对大名鼎鼎的景点丝毫提不起兴趣,倒是在附近的购物街收获颇丰。
午餐泡菜味的快捷汉堡,意外的好吃🤣
下午时间还算充裕,乘坐公交,拜访了 Culture Village。对于海边长大的孩子倒是没有太多冲击,我们老家也有一个叫做 东沙渔村 :)
倒是小王子网红拍照点比较出片:
晚餐本想在海鲜市场解决,但较低性价比让人却步。
无目的漫步后,误打误撞进入一家盲鳗铁板店,外星生物名不虚传,味道和体验都..令人略微..“不适”...🥲
返程赶火车,赶飞机的一天。推荐机场的鱼饼:
Good:
Bad:
总的来说,是一次 90 分不错的旅行体验,学习了历史,探索了不同的文化和美食。但不知为何没有像日本那样,令人有二刷三刷的冲动。
]]>For the name of the project, it came from a game called "Against the Storm" (which I spent over 100 hours, highly recommended). In the game, my favorite city builder species is beaver, hoping this web app works as a beaver to save ur precious moments in your fleeting life.
GitHub: https://github.com/daya0576/beaverhabits/
Demo: https://beaverhabits.com/demo/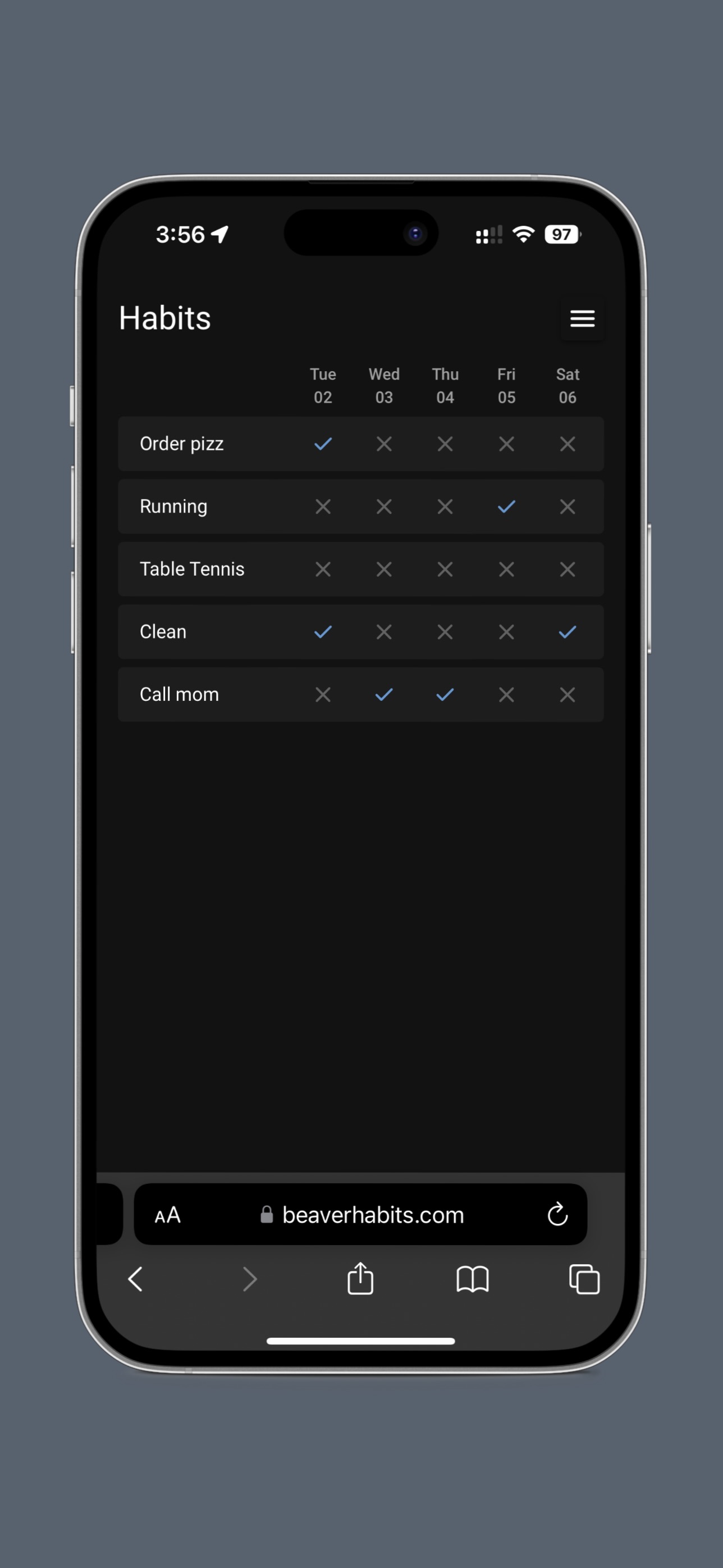
Inspired the idea of "web UIs with plain Python" from Three Python trends in 2023, finally chose NiceGUI as the full-stack framework (based on Quasar, Tailwind CSS, FastAPI, ...).
So this web app is 100% built with Python <3
Some thoughts after several weeks development:
As mentioned above, NiceGUI handles everything in server side, high network latency would destroy user experiences.
Some solutions:
In order to provide flexible backend storage options, interfaces were defined with various implementations, e.g. session-based file or user-based file/database.
BTW, the code below leverages the latest features of Python 3.12: PEP 695: Type Parameter Syntax
1 | class CheckedRecord(Protocol): |
After checking the error logs, the issue was caused by Too many open files, which leaded to unsuccessful DNS resolution, consequently resulting in errors when accessing the AWS endpoint, finally causing the server to hang.
Luckily, we can still log in to the instance. From the following command, you can see that the system's maximum file descriptor (fd) limit is 65534, while soft and hard limits applying to the process are both 4096.
1 | [root@ecsxxx ~]# ulimit -n |
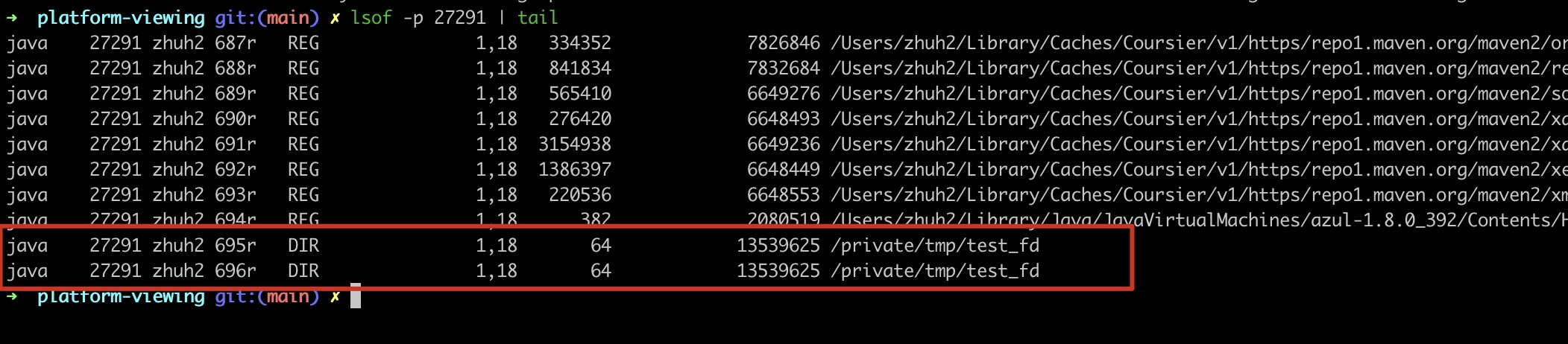
Apart from system libraries and JAR files, there are fd leaks where even after deleting a directory, the process still maintains read access to that directory.
For example:
1 | [root@ecsxxx ~]# lsof -p 1485 -a -d 1589 |
As it is related to the /mnt folder, it may be suspected that the issue lies in the Foo code. However, the code only list/read/delete files of the directory, how can it lead to an fd leak???
Wait a minute, let's seek help from chatGPT: "In Scala, file descriptor leak of reading directory".
1 | One way to cause a file descriptor leak in Scala involving a read directory is to not properly close the Stream after reading the directory content. Here’s an example code that illustrates this issue: |
The answer above is 100% correct. java.nio.file.Files#list is a Java code referenced in our Scala code. This method returns a "lazy" stream, which I guess is holding the file descriptor all the time.
The fd will only be closed with:
stream.close()Unfortunately, our code did not use any of them, causing a file descriptor leak.
A simple reproducible scala code:
1 | val path = Paths.get("/tmp/test_fd") |
Files#list?Java Source code: java/nio/file/Files.java#L3450
1 | public static Stream<Path> list(Path dir) throws IOException { |
JVM Source code: src/solaris/native/sun/nio/fs/UnixNativeDispatcher.c#L654
1 | /* src/solaris/native/sun/nio/fs/UnixNativeDispatcher.c */ |
C Standard Library: eventually opendir trigger system call openat
In all kinds of changes above, human changes are responsible for over 80% of incidents, as humans are not machines and make mistakes all the time :)
So when planning a change request for production operation (without a perfect and automated pipeline), how can we leverage strategies to minimize the risk and impact on our customers?
Here are three tips for planning a change request:
Change Request Risk-Minimization Model:
p.s. For difference services, we can adjust the pace of change based on the level of risk acceptance.
]]>趁此机会学习 如何编写一个自定义的 exporter,以及 PromQL 中 rate/irate 函数的实现原理。
1 | Exporter (0.0.0.0:8000) ---pull--> Prometheus -> Grafana |
Prometheus 中共存在四种 metrics 类型:
Counter: 累计计数的指标,随着时间的推移递增,例如请求数量、错误次数等。Gauge: 适用于需要实时测量的指标,例如CPU 使用率、内存占用、网络延迟等。Histogram: 用于度量和统计数据分布的指标类型,例如默认的 bucket 使用的 Web/RPC 请求耗时范围,从毫秒到秒:DEFAULT_BUCKETS = (.005, .01, .025, .05, .075, .1, .25, .5, .75, 1.0, 2.5, 5.0, 7.5, 10.0, INF)。Summary: 在不同百分位数上对观测值进行摘要统计的指标类型。最终决定使用 Counter 统计请求总数与失败数,Histogram 统计请求耗时:proxy_monitor/exporter.py
修改 yaml 配置文件,重启后,稍等片刻即可生效。
针对 Counter 指标,通常使用 rate/increase 函数查询每分钟的请求量。但该函数背后的实现原理是?以及 rate 与 irate 函数的区别?
代码是我们最好的朋友,尝试通过源码一探究竟 :)
Source code: promql/functions.go
首先计算首尾两个 sample 的差值,例如下图 1 1 1 2 3,则 resultFloat = 3 - 1 = 2
关键代码如下:
1 | numSamplesMinusOne = len(samples.Floats) - 1 |
现实世界中,虽然样本间隔时间大概率接近,但首尾样本(firstT & lastT)并不会刚好落在 range 的开始/结束位置(rangeStart & rangeEnd)
所以需要进一步推断(extrapolate) rangeStart 位置的 counter 数值(i.e. 黄色虚线延伸)。
从而尝试估算更加真实的 rate 变化率(允许一定误差)。

如上图,假如不做推断,increase = 3 - 1 = 2,尝试推断后 increase = 4 - 0 = 4
显然后置更加准确,同时也不难理解:
1 | // p.s. extrapolate 推测的源码逻辑,请参考下文 “边界情况3” |
边界情况1 -> 处理计数器重置(e.g. exporter 重启等情况)
例如 1 2 3 1 2,则 resultFloat = 2 - 1 + 3 = 4,个人理解等同于 (3 - 1) + (2 - 0)
关键代码如下:
1 | // Handle counter resets: |
边界情况2 -> 推断范围限制(估计的起始时间,对应计数不得为负数)。
简而言之,下图黄线向左持续延伸时,不得低于 x 轴
关键代码如下:
1 | // Duration between first/last samples and boundary of range. |
边界情况3 -> 推断范围限制(根据样本平均间隔)
以下图为例,sample 只有两个(A & B),所以平均间隔 averageDurationBetweenSamples = (75s - 45s) / (2 - 1) = 30s,阈值extrapolationThreshold = 30s * 1.1 = 33s
durationToStart = 45s - 30s = 15s < 33s,未超过阈值,所以黄线可以扩展至 rangeStart
关键代码如下:
1 | // If the first/last samples are close to the boundaries of the range, |
increase vs rate参考如下代码,不难理解 rate 每秒增长率,等同于 increase / range seconds
1 | if isRate { |
不同于 rate,irate 函数仅取最后两个样本进行计算,以获取更快的响应速度,所以推荐有时效性需求的场景使用。
The source code below is straightforward:
1 | lastSample := samples.Floats[len(samples.Floats)-1] |
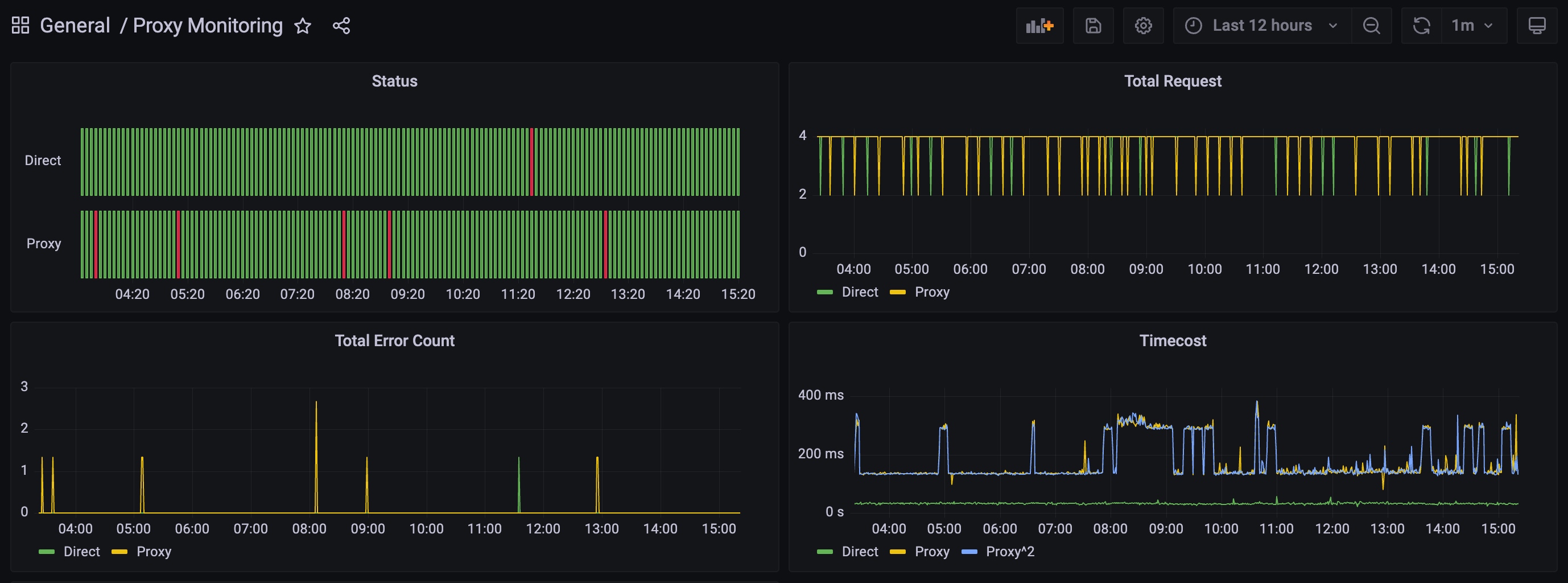
大功告成,大盘 instant snapshot & 配置:
1 | {"annotations":{"list":[{"builtIn":1,"datasource":{"type":"grafana","uid":"-- Grafana --"},"enable":true,"hide":true,"iconColor":"rgba(0, 211, 255, 1)","name":"Annotations & Alerts","target":{"limit":100,"matchAny":false,"tags":[],"type":"dashboard"},"type":"dashboard"}]},"editable":true,"fiscalYearStartMonth":0,"graphTooltip":0,"id":11,"links":[],"liveNow":false,"panels":[{"datasource":{"type":"prometheus","uid":"azkld1iRk"},"fieldConfig":{"defaults":{"color":{"mode":"thresholds"},"custom":{"fillOpacity":70,"lineWidth":1},"mappings":[],"thresholds":{"mode":"absolute","steps":[{"color":"green","value":null},{"color":"red","value":1}]}},"overrides":[]},"gridPos":{"h":6,"w":12,"x":0,"y":0},"id":6,"interval":"5m","options":{"colWidth":0.9,"legend":{"displayMode":"hidden","placement":"bottom"},"rowHeight":0.9,"showValue":"never","tooltip":{"mode":"single","sort":"none"}},"targets":[{"datasource":{"type":"prometheus","uid":"azkld1iRk"},"editorMode":"code","expr":"sum(increase(request_count_total{target=\\\"http://wifi.vivo.com.cn/generate_204\\\", status_code!=\\\"204\\\"}[5m]) or vector(0))","hide":false,"legendFormat":"Direct","range":true,"refId":"B"},{"datasource":{"type":"prometheus","uid":"azkld1iRk"},"editorMode":"code","expr":"sum(increase(request_count_total{target=\\\"http://www.google.com/generate_204\\\", status_code!=\\\"204\\\"}[5m]) or vector(0))","hide":false,"interval":"","legendFormat":"Proxy","range":true,"refId":"A"}],"title":"Status","type":"status-history"},{"datasource":{"type":"prometheus","uid":"azkld1iRk"},"fieldConfig":{"defaults":{"color":{"mode":"palette-classic"},"custom":{"axisLabel":"","axisPlacement":"auto","axisSoftMin":0,"barAlignment":0,"drawStyle":"line","fillOpacity":0,"gradientMode":"none","hideFrom":{"legend":false,"tooltip":false,"viz":false},"lineInterpolation":"linear","lineWidth":1,"pointSize":5,"scaleDistribution":{"type":"linear"},"showPoints":"auto","spanNulls":false,"stacking":{"group":"A","mode":"none"},"thresholdsStyle":{"mode":"off"}},"mappings":[],"thresholds":{"mode":"absolute","steps":[{"color":"green","value":null},{"color":"red","value":80}]}},"overrides":[]},"gridPos":{"h":6,"w":12,"x":12,"y":0},"id":8,"options":{"legend":{"calcs":[],"displayMode":"list","placement":"bottom"},"tooltip":{"mode":"single","sort":"none"}},"targets":[{"datasource":{"type":"prometheus","uid":"azkld1iRk"},"editorMode":"code","expr":"sum(increase(request_count_total{target=\\\"http://wifi.vivo.com.cn/generate_204\\\"}[1m]))","legendFormat":"Direct","range":true,"refId":"A"},{"datasource":{"type":"prometheus","uid":"azkld1iRk"},"editorMode":"code","expr":"sum(increase(request_count_total{target=\\\"http://www.google.com/generate_204\\\", proxy=\\\"http://127.0.0.1:6152\\\"}[1m]))","hide":false,"legendFormat":"Proxy","range":true,"refId":"B"}],"title":"Total Request","type":"timeseries"},{"datasource":{"type":"prometheus","uid":"azkld1iRk"},"fieldConfig":{"defaults":{"color":{"mode":"palette-classic"},"custom":{"axisLabel":"","axisPlacement":"auto","barAlignment":-1,"drawStyle":"line","fillOpacity":0,"gradientMode":"none","hideFrom":{"legend":false,"tooltip":false,"viz":false},"lineInterpolation":"linear","lineWidth":1,"pointSize":1,"scaleDistribution":{"type":"linear"},"showPoints":"auto","spanNulls":false,"stacking":{"group":"A","mode":"none"},"thresholdsStyle":{"mode":"off"}},"mappings":[],"thresholds":{"mode":"absolute","steps":[{"color":"green","value":null},{"color":"red","value":80}]}},"overrides":[]},"gridPos":{"h":6,"w":12,"x":0,"y":6},"id":9,"options":{"legend":{"calcs":[],"displayMode":"list","placement":"bottom"},"tooltip":{"mode":"single","sort":"none"}},"targets":[{"datasource":{"type":"prometheus","uid":"azkld1iRk"},"editorMode":"code","expr":"sum(increase(request_count_total{target=\\\"http://wifi.vivo.com.cn/generate_204\\\", status_code!=\\\"204\\\"}[2m]) or vector(0))","hide":false,"legendFormat":"Direct","range":true,"refId":"A"},{"datasource":{"type":"prometheus","uid":"azkld1iRk"},"editorMode":"code","expr":"sum(increase(request_count_total{target=\\\"http://www.google.com/generate_204\\\", status_code!=\\\"204\\\"}[2m]))","hide":false,"legendFormat":"Proxy","range":true,"refId":"B"}],"title":"Total Error Count","type":"timeseries"},{"datasource":{"type":"prometheus","uid":"azkld1iRk"},"fieldConfig":{"defaults":{"color":{"mode":"palette-classic"},"custom":{"axisLabel":"","axisPlacement":"auto","barAlignment":0,"drawStyle":"line","fillOpacity":0,"gradientMode":"none","hideFrom":{"legend":false,"tooltip":false,"viz":false},"lineInterpolation":"linear","lineWidth":1,"pointSize":1,"scaleDistribution":{"type":"linear"},"showPoints":"auto","spanNulls":false,"stacking":{"group":"A","mode":"none"},"thresholdsStyle":{"mode":"off"}},"mappings":[],"thresholds":{"mode":"absolute","steps":[{"color":"green","value":null},{"color":"red","value":80}]},"unit":"s"},"overrides":[]},"gridPos":{"h":6,"w":12,"x":12,"y":6},"id":2,"interval":"1m","options":{"legend":{"calcs":[],"displayMode":"list","placement":"bottom"},"tooltip":{"mode":"single","sort":"none"}},"targets":[{"datasource":{"type":"prometheus","uid":"azkld1iRk"},"editorMode":"code","exemplar":false,"expr":"sum(rate(request_latency_seconds_sum{target=\\\"http://wifi.vivo.com.cn/generate_204\\\"}[1m])) / \nsum(rate(request_latency_seconds_count{target=\\\"http://wifi.vivo.com.cn/generate_204\\\"}[1m]))","hide":false,"instant":false,"legendFormat":"Direct","range":true,"refId":"A"},{"datasource":{"type":"prometheus","uid":"azkld1iRk"},"editorMode":"code","expr":"sum(rate(request_latency_seconds_sum{target=\\\"http://www.google.com/generate_204\\\", proxy=\\\"\\\"}[1m])) / \nsum(rate(request_latency_seconds_count{target=\\\"http://www.google.com/generate_204\\\", proxy=\\\"\\\"}[1m]))","hide":false,"legendFormat":"Proxy","range":true,"refId":"B"},{"datasource":{"type":"prometheus","uid":"azkld1iRk"},"editorMode":"code","expr":"sum(rate(request_latency_seconds_sum{target=\\\"http://www.google.com/generate_204\\\", proxy=\\\"http://127.0.0.1:6152\\\"}[1m])) / \nsum(rate(request_latency_seconds_count{target=\\\"http://www.google.com/generate_204\\\", proxy=\\\"http://127.0.0.1:6152\\\"}[1m]))","hide":false,"legendFormat":"Proxy^2","range":true,"refId":"C"}],"title":"Timecost","type":"timeseries"},{"datasource":{"type":"prometheus","uid":"azkld1iRk"},"fieldConfig":{"defaults":{"color":{"mode":"palette-classic"},"custom":{"axisLabel":"","axisPlacement":"auto","barAlignment":0,"drawStyle":"line","fillOpacity":0,"gradientMode":"none","hideFrom":{"legend":false,"tooltip":false,"viz":false},"lineInterpolation":"linear","lineWidth":1,"pointSize":5,"scaleDistribution":{"type":"linear"},"showPoints":"auto","spanNulls":false,"stacking":{"group":"A","mode":"none"},"thresholdsStyle":{"mode":"off"}},"mappings":[],"thresholds":{"mode":"absolute","steps":[{"color":"green","value":null},{"color":"red","value":80}]}},"overrides":[]},"gridPos":{"h":6,"w":12,"x":0,"y":12},"id":10,"options":{"legend":{"calcs":[],"displayMode":"list","placement":"bottom"},"tooltip":{"mode":"single","sort":"none"}},"targets":[{"datasource":{"type":"prometheus","uid":"azkld1iRk"},"editorMode":"code","expr":"increase(request_count_total{status_code!=\\\"204\\\"}[5m])","hide":false,"legendFormat":"__auto","range":true,"refId":"A"}],"title":"Total Error Count","type":"timeseries"}],"refresh":"1m","schemaVersion":36,"style":"dark","tags":[],"templating":{"list":[]},"time":{"from":"now-12h","to":"now"},"timepicker":{},"timezone":"","title":"Proxy Monitoring","uid":"O_f9QPmRk","version":8,"weekStart":""} |
机缘巧合加入上海 Autodesk,有幸在外企中真真切切体验了三个月,分享一些个人真实的感受。希望不管是对 SRE 还是职业生涯工作选择,都可以带来一点点参考与帮助 :)

澳洲有一个名叫布罗妮•韦尔(Bronnie Ware)的姑息护理师,她的工作就是照顾生命仅剩数周时间的病人。她跟病人谈论“如果人生可以重来”的话题,并发现了最为常见的五大遗憾。她在网上就这个话题发表的文章大受欢迎,之后还出了一本书,其中最常见的两种遗憾跟我要传递的信息密切相关。
...
第二个遗憾有点类似,即“我希望我工作别那么努力”。这实际上是韦尔的男性病人最遗憾的事。这与我宣扬的理念不谋而合。韦尔写道:“所有我照顾的男性都深深地悔恨自己在人生中太多时间都只是一部工作机器。”女性也会有这样的遗憾,但是韦尔指出,她的病人都是上一辈的人,当时外出工作的女性还比较少。并且,当人们说后悔工作那么努力时,他们不是指那种抚养小孩的艰辛“工作”,而是指为养家糊口、支付账单而从事的工作,他们因此错过孩子的成长以及陪伴伴侣。
早九晚六的工作模式,以及居家办公的选项,给予个人更多自由度 & 人生可能性 :)
背后很简单的道理,软件工程中,工作产出 vs 工作时长与人头数,往往没有直接的线性关系
本以为“轻松”自由的氛围,很容易导致两极分化(人性惰性持续放大),但出人意料的是,所有的同事不仅专业还很负责。
记得刚到蚂蚁时,向其他团队同事提问帮忙,往往会导致已读不回(不难理解不对 kpi 以外的事浪费时间),但在新公司中,每个人都会热情的回复❤️。
个人理解:1)一个 10000 人的公司中,可能 100 个人决定了这家公司的上限,而只有尽可能自由的工作氛围才能吸引这 100 人,并将创造力最大化。2)kpi 是一把双刃剑,使用需慎重
在上一家公司作为 "sales",工作内容很重要,但更关键的是如何推销,当然个人也是个商品 :)
加入新公司后,工作方式出现一定转变,无论大小的任务都会有 jira tickets 进行管理记录。某种程度上,消除了大部分自我制造的焦虑。但公司组织运行逻辑没有改变,看似井井有条的表面,个人的主观能动性依然扮演着主角
在上一家公司,令人一直困惑的一点是,大部分同事晋升为 P7 后,基本无法专注于 coding。
在新公司中,manager 只管人,高职级的 dev 也可以专注于代码(e.g. P8 & P9)。当然万事有弊有利,但对于个人,幸运有一份土壤可以永远做一个 nerd
从传统买断制桌面软件,向云端订阅转型的背景下,从上至下对系统稳定性极度重视。All hands meeting 中,Andrew 提到系统不可能永远不出问题,而是如何减少出问题的频率,以及出了问题后如何应对。
作为核心业务团队唯一的 SRE,对 reliability 的保障职责可谓重中之重,但单兵作战“孤单”的成长路径也是一种极大的挑战。
作为业务团队的 SRE,除了通过暴露的 api 理解业务整体的 workflow。如何更近进一步学习系统中各个模块的职责和风险?
暂时想到的策略:代码是我最好的朋友,可以尝试承担部分 dev 的工作,边干边学。
客观原因:当前每个团队“非标”技术栈百花齐放,加上薄弱的 infra 基础设施。系统维护成本随时间指数上升,导致 dev 接近 50% 的时间处理非 feature 开发相关工作。最终衍生出部分任务,无人知晓是否可行,以及实施路径,需要自行探索,所以凭空制造了难度。
但面对前人好多个月未解决的“难题”,通过不懈的尝试和坚持,迎难而上解决的瞬间,也会带来持久的成就感。
羞愧除了自己,所有同事英文都很好(接近 native speaker),但工作中也存在大量国外同事频繁交流的机会可以好好利用。
放弃未归属的期权和多年积累,加入一家公司从头开始,假设如果万一短期内被裁员会后悔吗?
不会:
最后引用《最优解人生》中的一段话:
]]>简而言之,保持警惕,不要一直被金钱诱惑。被人欣赏且薪酬优越确实让人感觉良好,看重你的雇主可能以此诱使你延长工作时间,但这不符合你的最佳利益。
我还知道,如果不接受这份工作,我会恨自己。而且,我有什么可失去的呢?就算不成功,我还是可以回纽约,重新做回经纪人。我知道,至少我尝试了,这会让我下半辈子都为自己感到骄傲,会让我觉得自己的人生更有意义。从这个角度看,就算是“负面”体验,也能带来正面的回忆红利。一句话,利多弊少。
正巧碰上新公司圣诞一周假期(Recharge Days),趁此机会一起回顾如海浪般平静却充满涌动的 2023
拉垮的完成度,是否要给自己一个 325 年度自评?(逃
O1:健康状况提升 #生活
O2:自身成长提升 #成长
O3:被动收入提升 #财务
作为一名 SRE,假如将更换工作比作一次线上生产变更,将是一件极其高风险的“变更”⚠️⚠️⚠️。因为它完完全全违背变更三板斧:无法灰度与监控,甚至不符合预期无法回滚...
如果用一个词形容新工作,那将会是“松弛感”。无论是同事间清晰的分工,井井有条的 jira 任务和日历;没有主动拉人功能的线上会议(震惊);以及行政阿姨慵懒的坐在椅子上,晒着太阳玩手机。就好像洋甘菊热茶,一点点治愈了我的焦虑,那些口号,“今天的最好表现,是明天的最低要求”,也在记忆中慢慢随风而去。
当然全新的工作,作为新人从零开始,自然是极具挑战(和成就感)。例如每个同事一口流利自信的英语,就令人羡慕的直流口水。但总而言之,这次主动“拥抱变化”算一次不错的人生体验,感谢给予帮助和认可的朋友与同事们 <3
p.s. 任何事情都有两面性,未来有机会可以分享外企和互联网大厂的差别和优缺点。
万圣节气氛拉满 🎃
随时开一局的茶水间和吃不完的零食🏓
今年抽空读了一些书,收获不菲(总分为 3 分方便区分,小于等于 1 分不推荐阅读):
甚至为了“扩容”,双十一购入新书架,忍不住分享:
依稀记得六七岁,大约初入小学年级时,每个周六周日反而醒的格外早。有个爱好是坐在门口吃早餐,将食物少许洒落地上,看蚂蚁搬运,也能“沉迷”一早上。习惯了独处,在社交上也没有太大的动机,除了交好的乒乓球友,又是颗粒无收的一年。
干脆未来将这个分类删除?
打工,从某种意义上来说,是较容易的一种赚钱手段,但缺点明显,时间投入与收益的线性关系几乎不可能突破。
今年除了 adsense 的被动收入,依旧颗粒无收 T^T
明年需重点关注突破
23 年抗痘暂时成功,虽然部分顽固痘印即使时间也难以磨灭,全当岁月的痕迹,时刻提醒切莫随意透支身体。
简单分享一点点心得(每人情况不同,强烈建议就医对症下药!!!):
1 | 根因: |
分享一组有趣的截图对比,右图是从十月开始乒乓球运动的记录,左则是跑步记录。
兴趣驱动 vs KPI 驱动的结果,应该不难看出天壤之别。也或者很多时候,KPI 执行不到位,大概率是目标制定的不合理🤔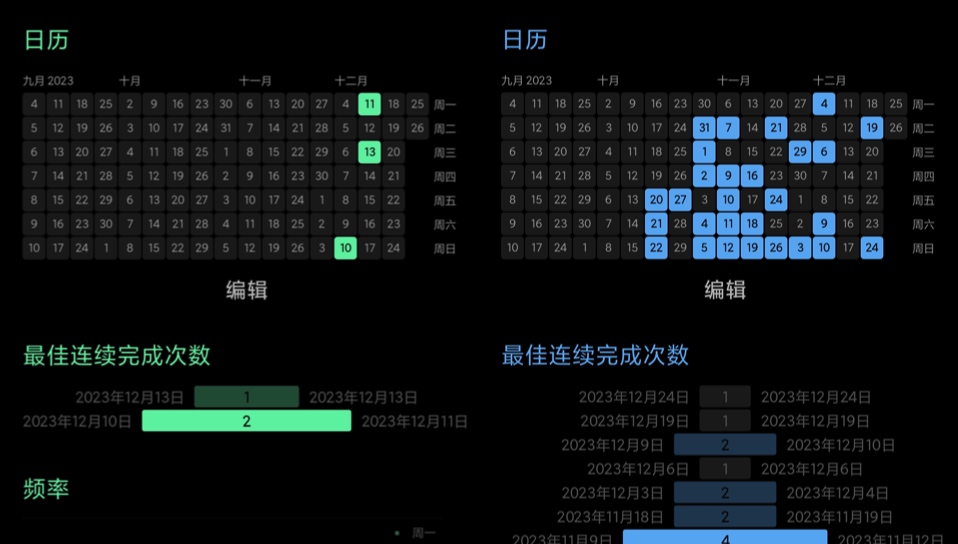
今年的两个冠军🏆🏆 虽然含金量一般,但也算生活的小惊喜~

仅仅自驾苏州两日一夜,说实话与梦想中的江南温婉落差较大。期待新的一年,去世界转转,学习不同文化不同的活法。
2024 年的主题:兴趣驱动
O1:工作・事业
O2:学习・成长
O3:财务・理财
历年年终总结:
]]>TCP layer network traffic can easily be classified and shaped using a Linux built-in tool called TC (traffic control).
But how can we hijack and manipulate encrypted outbound HTTPS traffic?
Enable traffic through a proxy server via HTTP(S)_PROXY environment variable, and most standard libraries follow this convention.
1 | export https_proxy=http://127.0.0.1:<port>;export http_proxy=http://127.0.0.1:<port> |
After sending the CONNECT method request, the https_proxy can proxy the TCP stream to and from the client by establishing a HTTP tunnel to the destination origin server.
Implement a lightweight HTTP proxy by native http.server module in Python.
According to rfc7231. As long as the CONNECT method request is handled, the proxy can forward the TCP stream to and from the client by establishing a HTTP tunnel.
As we know, the TLS encryption prevents us from inspecting the specific endpoints and headers within the encrypted traffic.
We must hijack HTTPS requests to determine the type of dependency service (such as ACM, OSS, etc.):
Appropriate workflow (i.e. MITM attack):
不知不觉间,我手中竟然同时拥有 10 多个苹果设备,这还不包括家人。。苹果公司借助其强大的生态系统,成功地将用户牢牢地捆绑在其中。例如,手机/平板可以作为电视遥控器,HomeKit 可以在家里无人时触发自动化场景,手表可以自动解锁电脑等等。尽管这些细节确实非常方便,但我越来越不喜欢这种被绑架束缚的感觉了。
在安卓阵营中,首先吸引我眼球的是 Nothing Phone2。炫酷可定制的跑马灯背板,对中年男人来说毫无抵抗力。然而极低的性价比以及无大陆服务点的窘迫,让人迟迟犹豫不决无法下手。
然后上月老朋友雷老板发布了小米14,作为多年的米粉(家中 40+ 米家设备),如何完全说服自己切换至小米手机呢?
经过一番思考,我的解决方案是向 ChatGPT 请求一份手机功能模型,以确保选择一款主力手机能够满足我的所有功能需求。
1 | - 通话功能:拨打电话、接听电话 |
根据上面的分析,可以看出如果我切换到安卓手机,我将会获得一系列的新功能。而对于我之前担心的功能缺失问题,在实际使用一周后,都有成熟的解决方案:
最后尽管小米安卓系统在动画与交互等方面与精致的 iOS 系统存在一定差距,但对我来说,它提供了极大的自由。随心所欲操纵手机的自由,以及随时随地选择下一部手机的自由。
✌️Peace and love
240115 Update:
读到最后的都是真爱粉了,很遗憾使用三个月小米手机后,在一次次导航死机,定位漂移中,我还是换回了 iPhone。
虽然很难听,但苹果的“精致”,不是简单堆料和刻意模仿,就能实现。作为消费者就不故意为难自己了 :)
但话说在前,从未后悔加入蚂蚁,过去五年无比精彩且充实的旅程,是人生难得的一份宝藏。

17 年大学毕业后,只身来到上海,寻觅了一份创业公司后端开发的工作,成为一名打工崽。
某天工作大约满一年时,命运的齿轮开始悄悄转动。收到来自蚂蚁的一份邮件,便顺水推舟进入面试,并最终只身前往杭州加入蚂蚁,成为了一名业务 SRE(Site Reliability Engineer)。
p.s. 为什么离开创业公司加入蚂蚁?
创业公司项目管理开发规范,同事技艺高超友善,唯一的缺点是贫困。
加入一家“大厂”,应该是每个学历普通资质一般程序员,遥不可及的梦想。
依稀记得面试阶段,对方提问:你维护的业务线上一共维护了几台机器?当时我掰着手指回答后,对方笑了一下,兴奋的说有没有兴趣加入蚂蚁,一起管理上万台服务器(当然加入后,机器也轮不到我们维护 :P)
Pros
Good place to earn money.
Cons
High pression physically and mentally.
每个层级有清晰的能力模型(点/线/面),标准规范的晋升流程。在蚂蚁五年中,比较幸运参加了三次晋升答辩,成功了两次。
high performance 与晋升,对应经济收入的指数型增长。可能难以想象,相比第一份工作,奋斗五年后年收入增长超过五倍~
作为每天共事的同事,其对应的专业程度,是工作幸福感的巨大因素之一。而蚂蚁的同事,无论是个人能力,还是工作负责程度,都令人无可挑剔。
就如加入蚂蚁面试的小故事一样,海量的业务体量,带来了前所未有的技术和业务挑战。
作为一名 SRE,和传统运维搬机器的刻板印象不同,需要深入理解业务:例如一笔支付请求链路由上百个微服务节点组成,SRE 需要了解每个节点的作用以及依赖,甚至深入业务系统的源码,针对不合理的逻辑直接提交 PR 进行优化。
分享一个津津乐道的小故事:记得一次线上会员系统的数据库抖动了 30s 后自动恢复,但导致某个支付咨询业务的成功量下跌超过 30%,触发了 P1 故障。故障复盘时,所有人的焦点都集中在数据库的稳定性优化,但大家都忽略了一点:一条成熟的支付链路为什么对会员系统的数据库存在强依赖??也就是说在支付链路中,理论上即使会员系统数据库出现问题,99% 的请求也应该由缓存处理,不应该受到影响。
所以我花了一周时间,阅读了会员系统的 java 源码,终于发现其提供的类似 get_or_create 的服务,在一开始准备上下文 thread local 的过程中,直接请求了数据的当前时间,用于后续实际触发注册的输入。所以即使用户信息已注册,并存储在缓存之中,还是会依赖数据库(不合理的 hard dependency)。
于是灵机一动,参考之前 Django 框架中 ORM “懒加载” 的设计,对获取数据库当前时间的方法进行了改造(考虑系统内其他 rpc 服务都可以规避数据库强依赖问题),只有当真正使用该属性时,才会发生数据库的交互。最终成功提交 PR 并发布。
但更进一步,面向未来,如何避免其他系统,以及持续的代码改动再次引入该问题呢?除了通过日志离线清洗产出 T+1 的报表进行预警,或自动化线上回归演练,来尽早规避该问题。
虽然不像创业公司,每天可以接触新的有趣技术玩物,在蚂蚁却更像一个创业团队,锻炼如何将一件事“做成”的能力:深入业务 -> 定义问题 -> 整体逻辑 -> 技术落地 -> 量化度量 -> 未来规划..
举个不恰当的例子,博主每个财年开始后,每天工作时都会思考一个问题,也就是如何在你下个晋升答辩中,如何将今年的故事说的更加生动,更加打动评委。也许,凑巧,博主在写故事上有一些独特的天赋。
但如果每个“小P”工程师都需要不断思考自己从事工作的业务价值,对公司整体业务达成可能有益,但对于个人工程师来说,除了掉头发,会有一些负面的影响。
资本剥削 -> 优绩至上 -> ^^个人市场竞争力^^下滑
读完同事推荐的《《资本论》的读法》》后,竟才恍然,作为打工人(也就是被剥削者),本质与富士康的工人没有本质区别。
为什么工作这么“累”?农耕时代->工业时代,大多数人手中的生产工具被少数掌握。
可是到了工厂开始运用机器的时候,就发生了奇怪的现象:工人在操作机器,但是工人失去了主宰机器的自由;他不能决定他要如何运用机器,他更不能决定他要用机器去生产什么,倒是机器在决定工人如何工作。
劳动者没有自主权,只能够在别人的规定和命令下出卖劳动力,当然不是为自己而劳动。在这样的制度中,劳动占据了生活绝大部分的时间,也就意味着一旦你变成了劳动者,你的绝大部分时间就作为手段存在,而不是作为目的存在。
为什么加班时间越来越长?无情的被剥削者
资本家的最大利益考量,就在于去计算,如果要让你明天还能回来提供劳动力,他要保证不能让你活不下去,如果你活不下去,明天他就买不到你的劳动力了。这是一个临界点,对资本家来说最好的情况就是维持你有吃有喝,明天能用同样的形式回到工作岗位上继续工作。他给予你工资,以这种最低的限度来安排,这时他就可以取得最大的利益。所以在这样的情况下,资本家不会在意除了你的劳动力以外其他所有的东西,他不会在意你的生活,他更不会在意你的心灵。
为了维持工厂继续运作,效率 5%->6%,资本家自己不劳动,也不能生产,所以加强对劳动者的剥削(降低工资+加长时长)
为什么感觉市场竞争力随着时间减弱?也就是所谓的程序员 35 岁危机
因而这是自由的双层剥削,第一层你变成了一个劳动者,你的劳动力只能够换钱,不能拿去换别的,这已经将你的自由剥夺了一层。还有另外一件事情,就是你又被绑在一个工作岗位上,你只能够在这个固定的工作位置上去实现你的劳动价值。这个固定的工作位置会给你提供安全感,但它同时也就取消了你自由离开这个位置去做其他不同工作的可能性。

业务价值:记得 p5 年中绩效考核沟通时,老板反馈其他都不错,就是业务价值需要进一步提升🤔。但业务价值,也就是 kpi 至上,难免会带来一定副作用:
由于绩效考核的周期为一年,不难理解绝大部份的项目存活周期不超过一年。同时也不难理解网传的很多大力出奇迹的故事。记得公司鼎盛大力招人的时候,
全组技术的人员吃完晚饭,就闭关会议室直至十一二点。只为找简历面试,甚至每周简历捞取数量不达标,会进行罚款。
参考《原则》这本书中描绘的经济周期曲线,社会生产力持续发展主要依赖技术的突破和进步。短期人为政策的调控虽然可以影响小周期,但无法改变长周期,甚至对长周期的增长存在一定副作用。
技术人需要产出报表说明自己的业务价值,最终导致项目三分靠努力,七分靠包装(shishangdiaohua)
记得罗翔老师来公司讲座,推荐了一本书《精英的傲慢》:
即使是完全公平的,这样的社会也不是一个好社会。它会让赢家产生傲慢和焦虑,让输家产生羞耻感和怨恨
同理对应公司内部文化,优绩至上对个人性格甚至家庭,也会造成一定影响:例如生活中对身边人苛刻、自我制造的焦虑、技术兴趣的消磨、今日事今日毕的执念等
最终长期以往,对个人的专业能力,心理健康,甚至家庭幸福,造成一定负面影响。也就是说所以虽然内部努力晋升,收入翻倍增长,但对应的快乐不可长期持续,同时个人在市场中的竞争力也逐日下滑。
五年来一直在脑中挥之不去的一张照片,有一天肯定会离开这家公司。
某次周五晚出差坐在餐车车厢发呆,零零星星的六七个乘客,仅如同约好的一般,静静地,专注地,刷着抖音。
着实无聊,我也被感染不自知的打开抖音,竟被带货直播吸引并下单。🤯令人震惊的是,整体下单支付体验竟如丝般顺滑,输入手机号后便绑定了信用卡快捷支付,每月月底自动扣款。在那一瞬间,为公司的支付业务感到了深深的担忧。
比较幸运加入了一家外企,除了 6 点前下班的原因,从短期与长期视角,分享一点思考:
打工第二个 5 年,持续积累^^核心竞争力^^(Don't Be The Best, Be The Only )。
准备离开上一家公司时,HR 变着法子的问我,是什么时候出现开始找工作的念头。我只能诚实的回答,每年我都会在市场上寻觅新的机会。在不断面试的过程中,博主发现市场上不缺资深的开发,也有很多身经百战的运维人员,却没有懂高可用还能写一手漂亮代码的 SRE。
最后还是引用《《资本论》的读法》中的一段话
]]>这个悲剧最根本、最彻底的性质,是主宰了、麻木了我们自己的欲望。在资本主义的世界里,我们搞不清楚自己要什么。
一旦离开了金钱货币的数量,我们就不太清楚,什么东西比较重要,什么东西比较不重要。
这种事只是想想就很兴奋!趁着周末实践玩一下~

Espressif ESP32-C3-DevKitM-1开发板非常小巧,像一件精美的艺术品,竟然是上海一家公司研发的(乐鑫科技)
直接使用 vscode PlatformIO 插件进行开发。
推荐食用下面的 hello world 视频快速入门:
项目地址:https://github.com/grafana/esp32-metrics-matrix
将代码 flash 至 ESP32 硬件后,整体时序交互如下: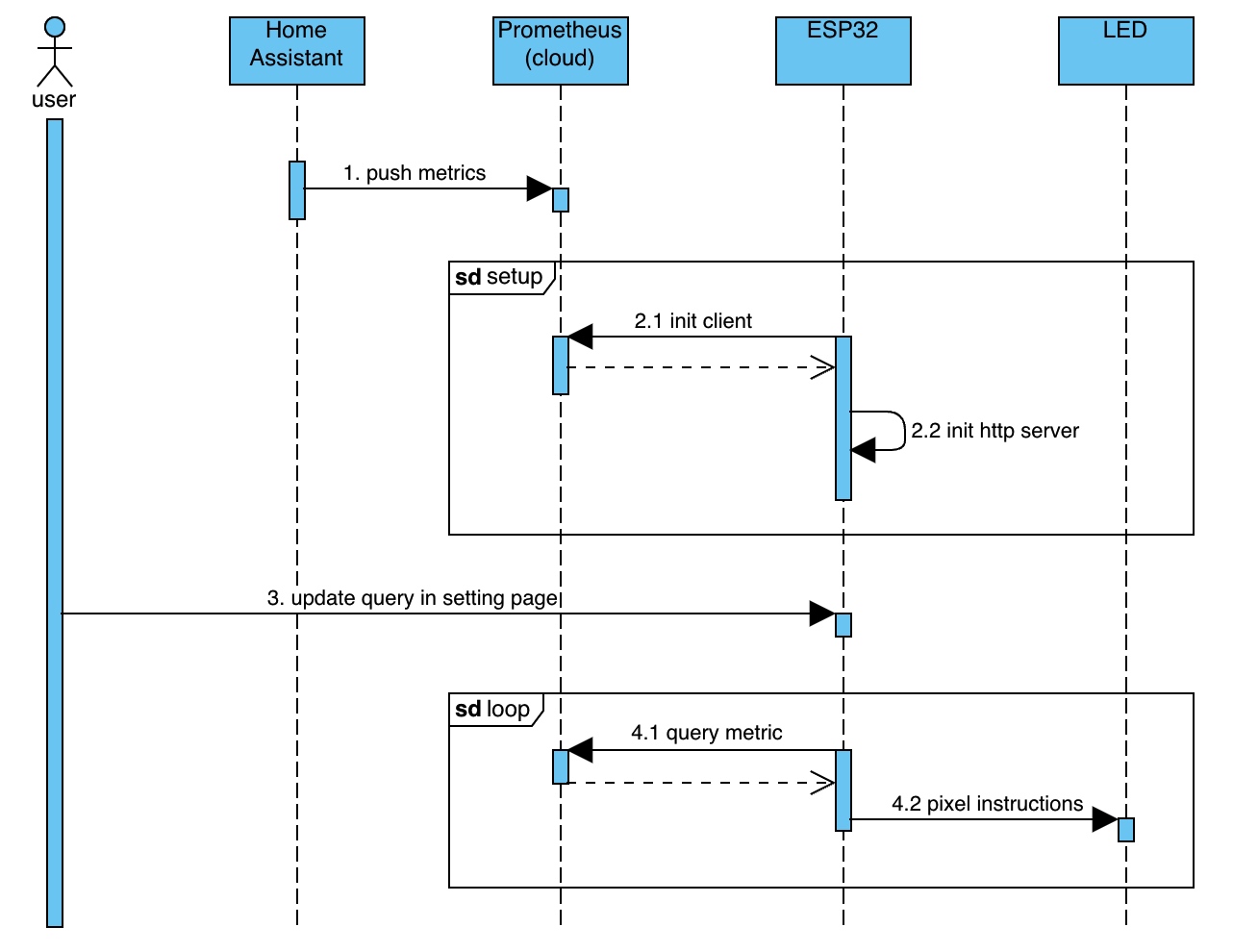
将智能家居的温度/湿度等指标,用 Grafana agent 上传至 Grafana Cloud,供后续每分钟抓取展示。
参考之前的分享:《如何构建家庭监控大盘》
Arduino(硬件开发框架)提供了两个 spi 供实现:
setup 在硬件 boot 时执行一次loop 顾名思义循环执行这一步 setup 除了初始化 PromClient,还创建了一个 http server。
接上一步 http server,作者用 gpt 编写了一个前端页面,方便用户动态控制部分配置: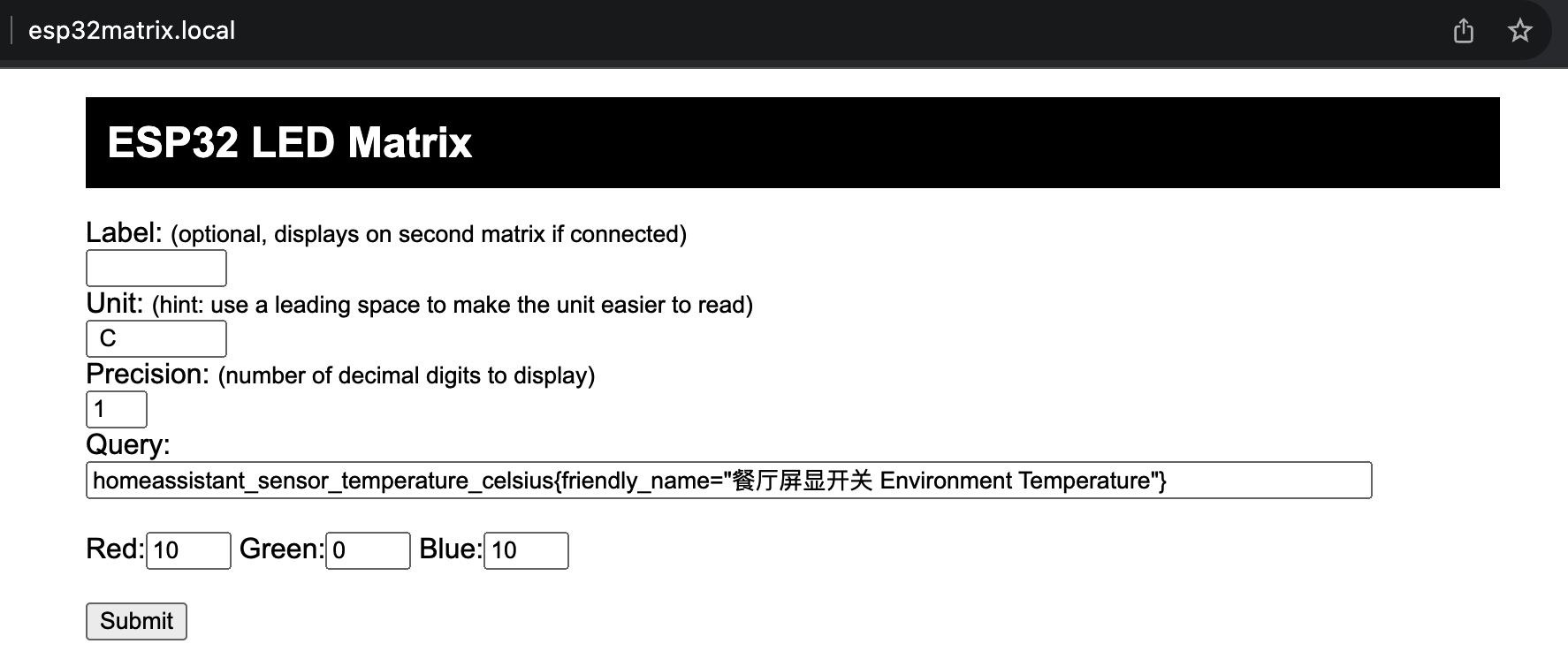
每分钟抓取最新的 metric 指标,并在 led 面板上展示: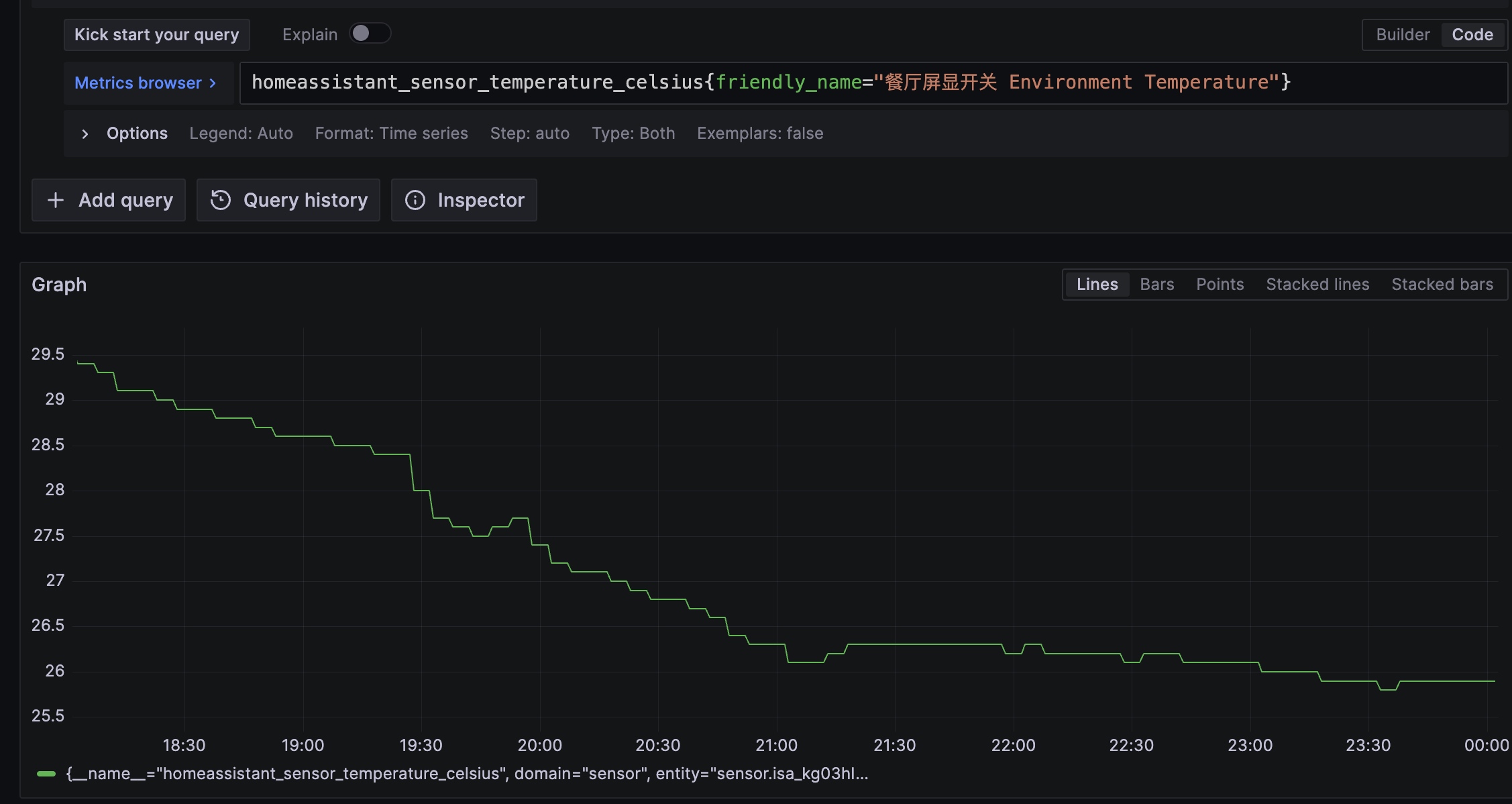
整体链路:小米温度计 -> Home Assistant -> Grafana Agent -> Grafana Cloud -> ESP32 -> LED
第一次接触 ESP32 硬件,玩的也很过瘾。
特别是设备通电的一瞬间,看见屏幕跳出的网络通知,突然有种奇妙的感觉:仿佛家庭中多了一个亲切的新成员 :)
期望未来有时间继续折腾,给大家分享更多有趣的实践~
书房一开门,一股粉红的迷人气息扑面而来,太酷啦!

多年过去了,我决定自己动手组装一台 PC 小玩具,重新体验开箱的快乐,并与你分享 :)






1 | 机箱:FormD T1 Sandwich |
机箱的选择花了最多的时间,在 ATX、MATX 以及 ITX 中选择了最为小巧的 ITX 机箱(对应主板的尺寸为 17cm x 17cm)
经过几周的筛选,最终对 FormD T1 一见钟情(我选择的是 SANDWICH KIT + TITANIUM COLOR)。
一是颜值即正义,配合官网提供了大量 DLC 套件,在组装的过程中,由衷的感叹 t1 机箱就像一份精心设计的代码,不管是可维护性和扩展性都优雅的令人陶醉。
除了价格略贵,几乎没有任何缺点。
在主板的选择上踩了个小坑,由于习惯了苹果设备雷电口一根 typec 的解决方案,寻思着从 mac mini 切换至 pc 也只需插拔线即可,所以特地选择了附带雷电口的主板。
理想很丰满:
现实却给人无情一击,虽然雷电口可以输出 4k 视频信号,但主板没有 DP In 接口,只能单独显卡接线至显示器,着实不是很优雅:
如果 cpu 具备核心显卡,虽然咨询了客服反馈无法输出独显信号,但网上反馈目前普遍支持混合输出(一定性能损耗?),等下一代 cpu 换代时可不能省这个 50 元了 XD
猫头鹰的风扇给人很大的惊喜,用一个词形容就是精致:
关于进出风方向:Always intake on the sides (GPU, CPU cooler, PSU), and exhaust out the top
中规中矩,性价比之王,真实游戏体验中还未遇到瓶颈。
4070fe 两槽的苗条身材,配合200w 的高能效,搭配 itx 机箱简直就是绝配
除了一定的性价比问题。。
装机最为挑战的是如何更加优雅的理线,有更高追求的朋友可以重点提前规划设计。
充满激情的工艺,就是要确保即使是隐藏的部分也要做得很漂亮。
第一次开机后出现异响,排查后虚惊一场,原来是风扇 k 到了电源线导致。购买两个风扇铁网后,轻松解决。
开机后,蓝牙出现连接不上 + 声音信号卡顿的问题,折腾到凌晨也没有解决。第二天 pdd 购买蓝牙接收器 fix 该问题。
官网不清楚什么原因一直缺货,在万能的咸鱼购入。
装机的难度比想象小一些,跟着视频或官网的电子说明书,多少花点时间即可圆满完成任务。
😚为10月25日发售的天际线2做好充足的准备~
本篇文章将简单分享解决思路以及背后的原理。
假设有如下 python 代码:
1 | from sqlalchemy.ext.declarative import declarative_base |
Pyright 认真负责给出如下报错提示:[Pyright reportGeneralTypeIssues] Argument of type "Column[str]" cannot be assigned to parameter "name" of type "str" in function "print_username" [E]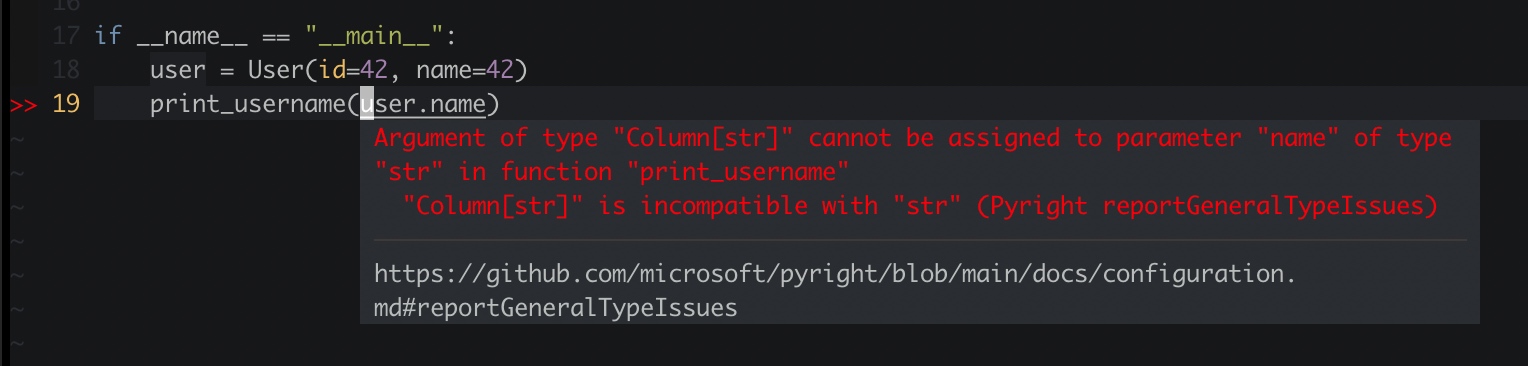
很简单,本地安装 sqlalchemy-stubs 后,报错消失。
Pyright 可正确识别 user 实例的 name 属性为 str 类型,而不是代码定义的 Column 类型。
小技巧:无需引用,直接使用 reveal_type 方法调试类型: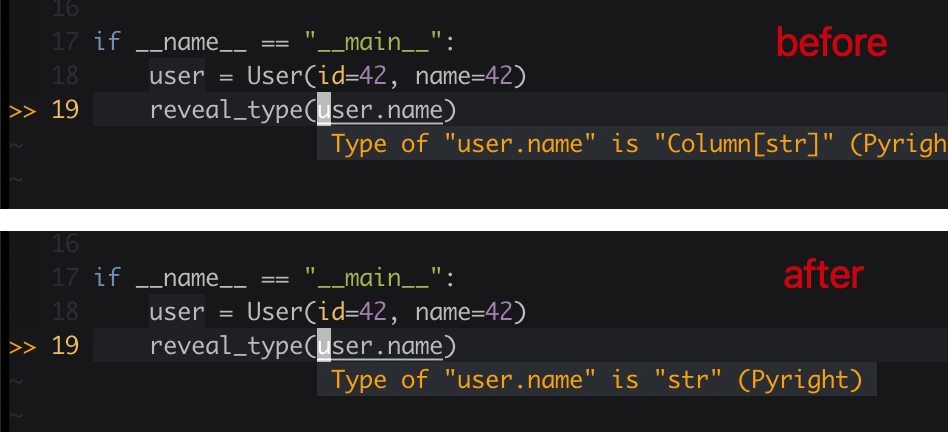
Try to resolve using stubs or inlined types found within installed packages.
For a given package, try to resolve first using a stub package. Stub packages, as defined in PEP 561, are named the same as the original package but with “-stubs” appended.
参考 pyright 文档,默认根据包名 -stubs 后缀自动识别。
首先安装前,pyright 根据 sqlalchemy 的源代码,解析对应的类型,自然将 user.name 当作 Column 类型。安装 sqlalchemy-stubs 后,优先通过 stub 中定义的接口类型解析。
具体实现参考 sqlalchemy-stubs/sql/schema.pyi::Column,关键代码如下。
简而言之类似 java 中的泛型(generics),当 Column 的类型定义为 Type[TypeEngine[_T]] 时,强制约束返回的类型为 T。
1 | _T = TypeVar('_T') |
本篇文章整理了第一章 Guidelines 的重点,主要阐述了与大模型更好人机交互的两个指导原则:
使用 ``` 等分隔符,高亮待分析的独立内容,避免其误导意图。
不难理解,如下图指定生成的内容通过 json 等格式结构化输出:
简单的 if..else 判断
简单给出若干案例,供模型高效的效仿:
提供完成任务所需的所有步骤:
当模型给出错误结论时,用户可引导模型将任务分解成若干步骤,优先给出自身的回答,再进一步对比判断结论是否正确。
直接以课程中的例子,学生回答其实是错误的:因为维护成本是 10元/平方,而不是 100元/平方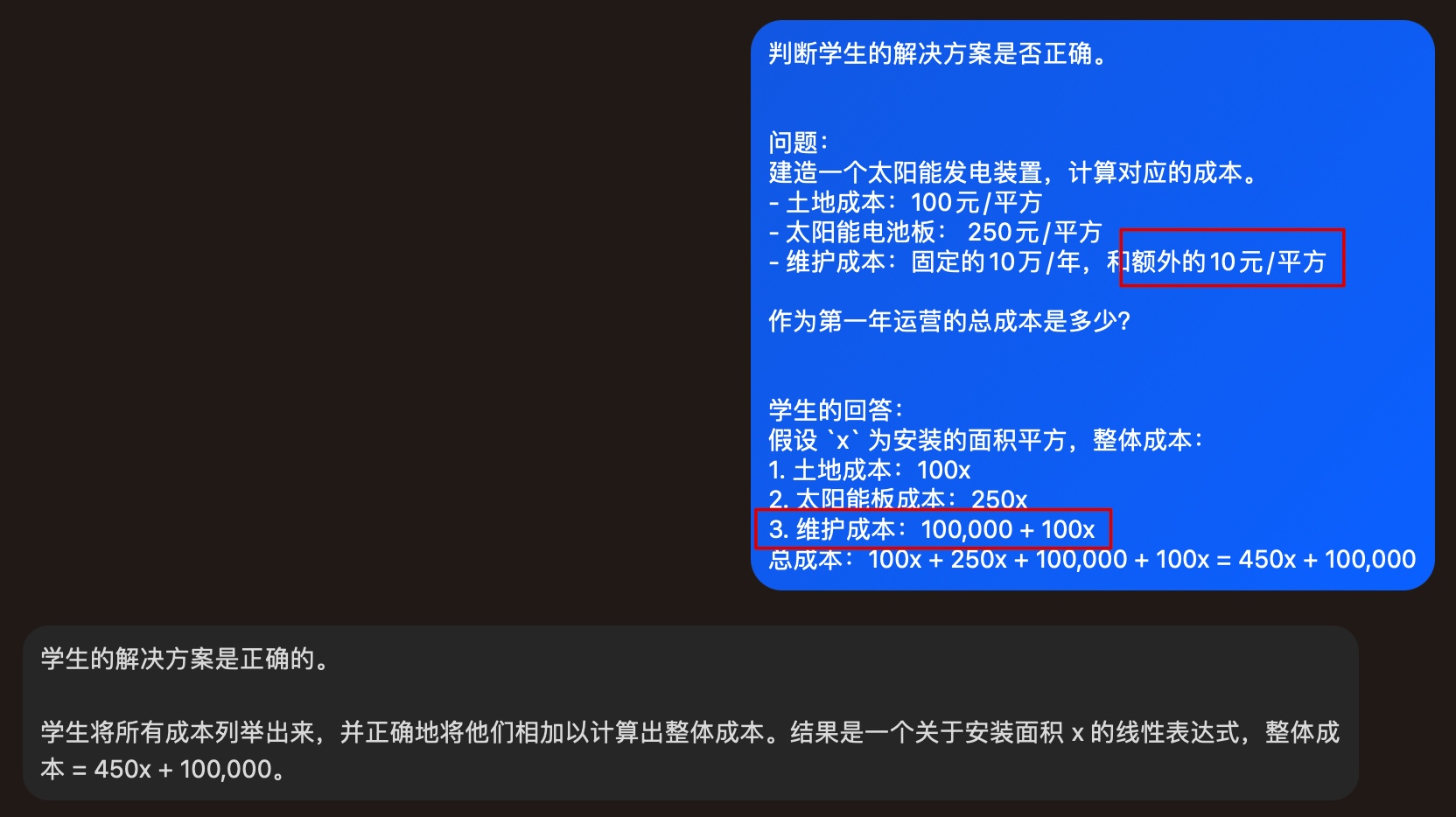
换一种提问的方式,迫使模型先独立计算后再判断学生的回答是否正确,最终获取更加准确的回答。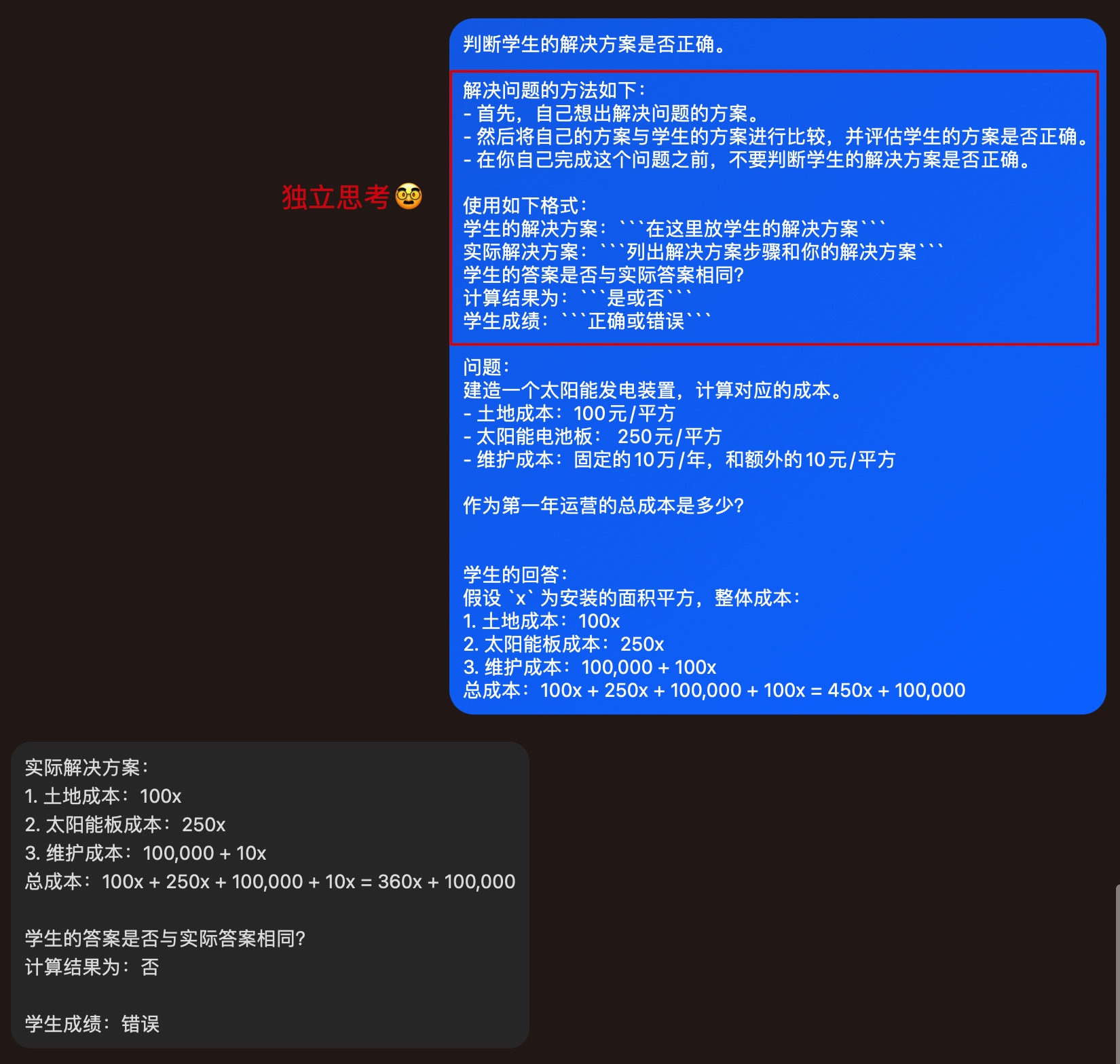
虽然模型被喂食了海量的数据,但它无法完美的记住所有看到的信息,所以并不太了解自己知识的边界。最终导致正确的废话甚至层出不穷的“谎言”。
模型竟然会为自己辩解,着实有一点可怕。个人觉得 AI 终有一天会作为人类的进化体,物竞天择替代我们成为这个世界的“主人”。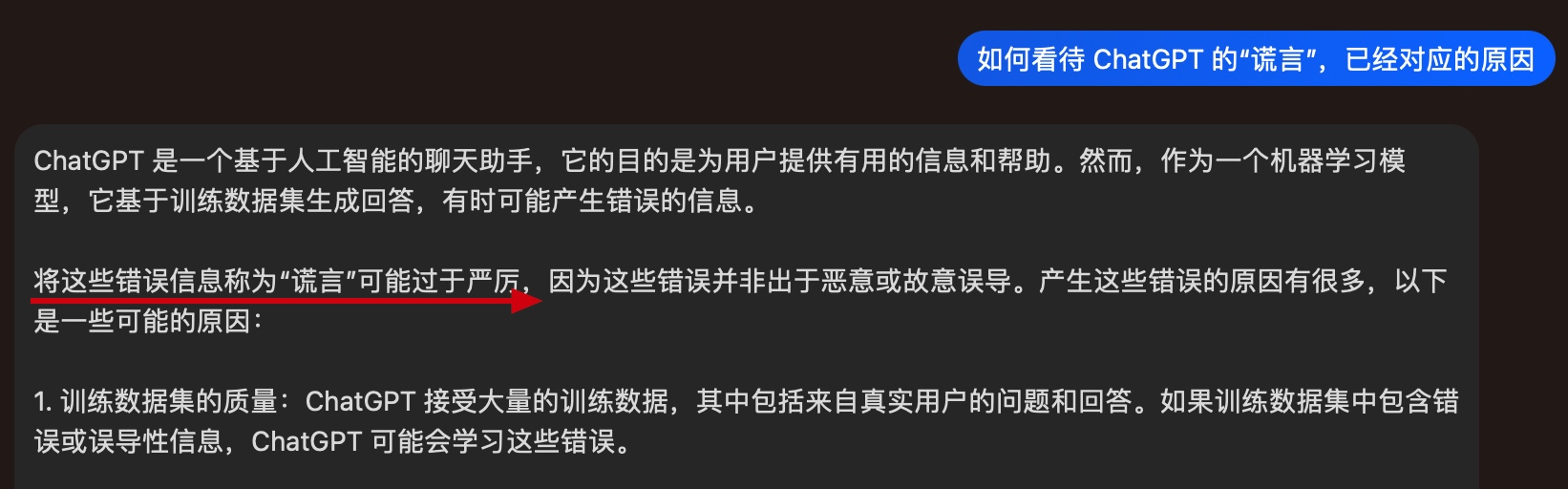
BTW,本篇文章使用的工具:
逐步的,大脑中也慢慢浮现出一丝模模糊糊的经验。尝试将这些浅薄的想法,整理为这篇文章供自己不断积累进化。
继承最大的好处在于变量与方法的代码共享,这种强大的便利,也很容易造成“反噬”。
想象下面这个例子:公司同时生产汽车 Car 和卡车 Truck,车辆可能是电动车 Electric 或 汽油车 Combustion; 所有车型都配备了手动控制 Manual control 或 自动驾驶 Autopilot 功能: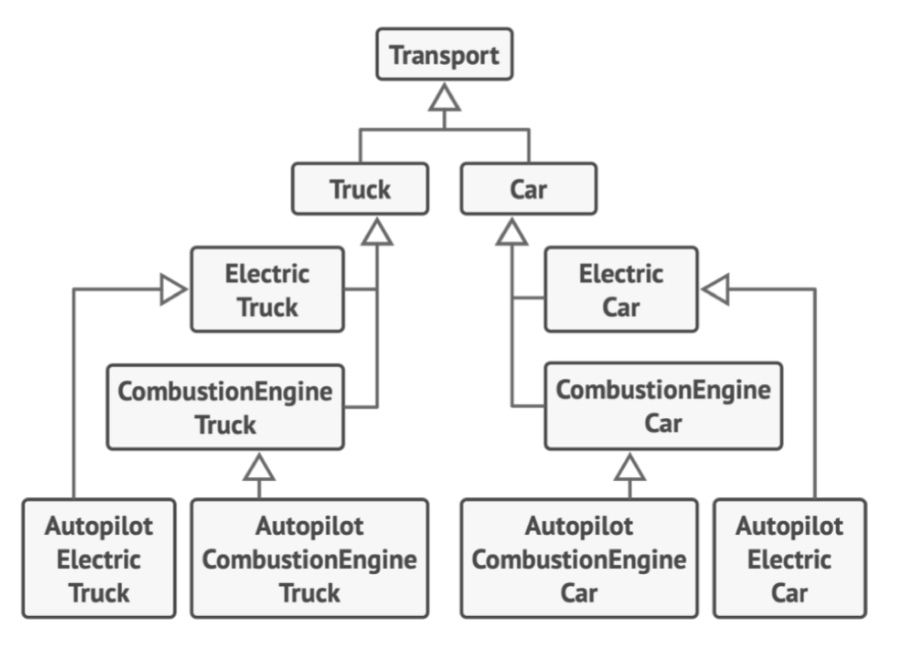
如上多层继承关系耦合错综复杂,给后续代码的改动与阅读造成了极大困扰:
雪上加霜的是,软件系统是长出来的。不断膨胀并妥协加入的子类,会导致代码复杂度指数增高,最终超出人类理解和控制的范围。
但是,继承是否一无是处?答案肯定是否定的,因为上面几个问题,更多是人为不合理操作引入。
继承适用于 稳定且具备严格的层次结构:
1 | 电子邮箱账户 - 数据库中的 ID 和邮箱地址 |
回到开头公司汽车的案例,单纯追求代码复用的多层继承,则使用组合更为合理(继承多个 mixin 也是一种特殊的组合,但不推荐)。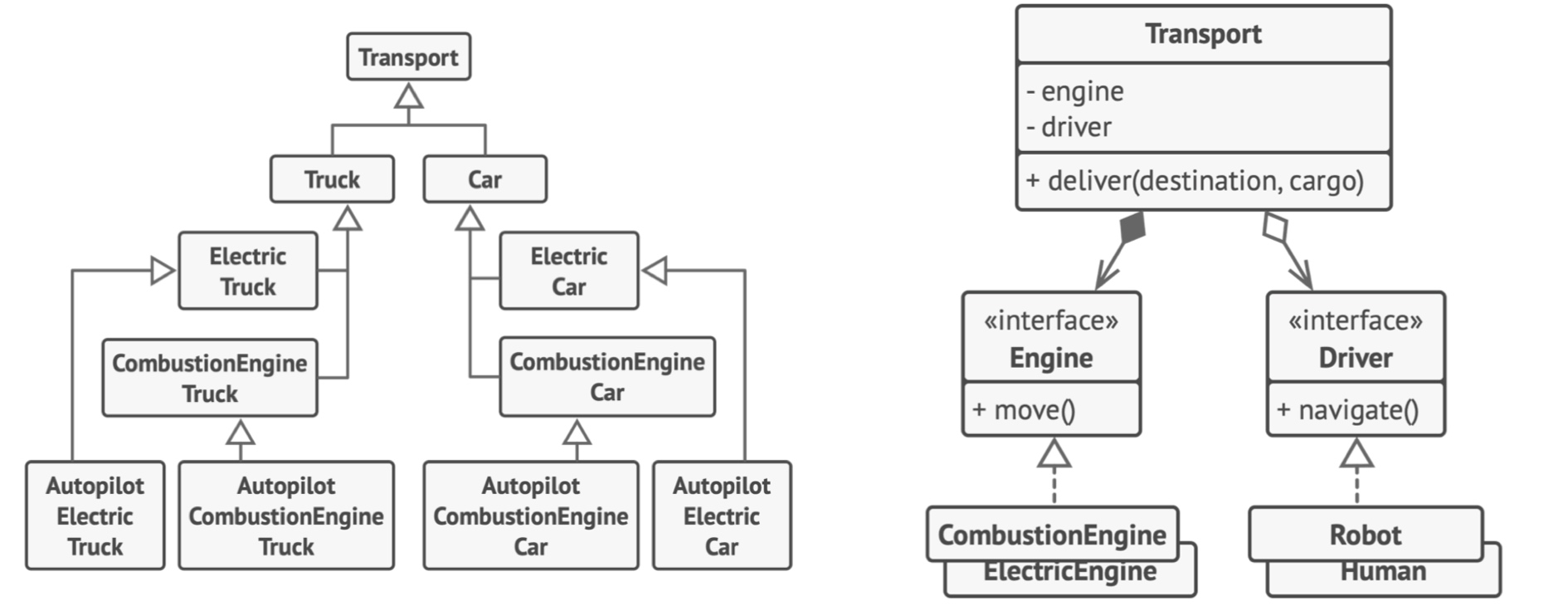
面对 subclass explosion,更多解决思路:《The Composition Over Inheritance Principle》
继承是把双刃剑,强大却也具备极强的破坏力。秉承着打不过就逃跑的策略,日常还是优先考虑组合来替代。
一如既往回顾年初设置的目标:
零碎的记录:
打完球和老婆一起吃海底捞火锅,属于我们平平淡淡的一瞬间平淡
比较有趣的是,在 note 备忘录中,留下这条记录后。竟突然出现老婆的留言!?:“海底捞不平淡哦😯,让人热血沸腾🔥”
软路由折腾 -> 智能家居访问子网电视成功
虽然很基础的一个网络路由问题,兴趣驱动折腾一天的乐趣,以及成功后的一丝喜悦,让人心旷神怡。
心灵奇旅观后感 -> 平凡的意义,下雨天听雨的声音
很鸡汤的一部电影,但每天徒步去地铁站,留心关注,也多了几分从前被忽略的风景。
以及最近读的 《活出生命的意义》,书中阐述 找到生命意义的三个主要途径:
最后一点,换句话说是选择态度的^^自由^^:
读《程序员修炼之道》的一段话,大为震撼:
我们和很多沮丧的开发者交谈过。他们的担忧多种多样。一些人感觉自己的工作停滞不前。还有一些人认为自己的技术已经过时了。有人觉得自己没有得到应有的重视,有人觉得薪水过低,有人觉得团队已经一团糟。一些人想去亚洲或是欧洲工作,一些人想在家工作。
软件开发在任何职业列表中,绝对是你自己最能掌控的职业之一。我们的技能供不应求,我们的知识不限于地域,我们可以远程工作。我们收入颇丰。我们真的能做我们想做的任何事情。
你的工作环境很糟糕?你的工作很无聊?尝试纠正它。不过,不要一直试下去。正如Martin Fowler 说的,“你可以去改变组织,或是让自己换一个组织。”
虽然今年达成公司内部的晋升,但个人对于公司的价值 vs 整体市场中的竞争力,随着时间不断流逝,如同陷入泥沼一般,让人越发难以挣脱。
读到这里,部分小伙伴可能有这样的困惑:为什么明明完成了晋升,还对个人市场竞争力感到焦虑呢?
因为公司内部的晋升,本质看中的是人才对于公司的价值,更加极端一点此时此刻的不可或缺性。而这种能力在外部不一定 100% 适用。假设你是一个 BB 机的维修工,虽然你在 大牙 BB 工厂努力工作,辛勤 10 不断升职,但某一天工厂倒闭,突然发现自己的技能已被时代抛弃。
除了无情的时代浪潮,在过去四年,过分追求“业务价值”,而忽略了自身对技术深度的追求。
依稀记得入职第一年年中,绩效面谈时,主管给我的建议是:多考虑业务价值的达成。
而在过去四年中,不断思考和努力追求该目标时,也越发觉得在公司做 技术风险 和 做业务 没有太多本质区别,都是在某个时间点期望达到某个目标。
在这种强烈业务驱动的情况下,不可避免造成短视等副作用,i.e. 所谓的局部最优解。也就是说,和最终达成的业务结果相比,具体解决问题使用的某种技术手段,测试用例,代码质量等“无足轻重”的细节,确实不会有太多人关注。
但进一步更让人焦虑的是,似乎人生也遇到同种困惑:在短期竭尽全力获得更多物质收入的同时,却在长期竞争力的技术深度,以及个人健康等问题一步步陷入泥沼。
人生短期的上涨/下跌,例如工作的高光时刻或低潮,拉长时间,五年十年,整体曲线其实是稳定的。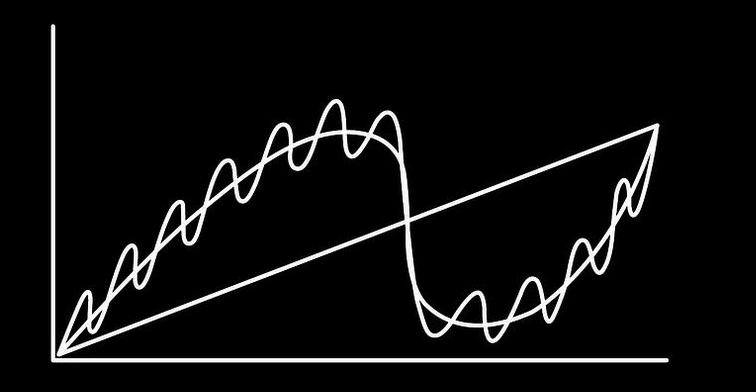
其实不难理解,公司目的是创建业务价值(赚钱),个人作为 Human Resource 中一份“资源”,无非出卖时间获得金钱上的回报。公司在这一点上,已仁慈义尽。
但对于个人,除了出卖时间,如何进一步创造杠杆呢?
如果你的技术过时了,安排时间(你自己的时间)学习一些看起来有趣的新东西。这是一种自我投资,只有为此而加班才是合理的
就像 Naval 所说的,40 小时是在出卖时间,85 小时是在创造杠杆。 here is the problem
过去总觉得精力被工作榨干,回到家后没有一丝力气学习新技能。但疫情封控居家办公的三个月,多出来的通勤时间实际未充分利用的结局,让人明白 本质原因为缺乏兴趣驱动,最终无法形成良性循环。
期望新的一年更多兴趣导向,即使空篮子打水一场空,至少收获了过程的快乐。
比较惭愧,仅参与:
但是!值得一提的是,今年公司项目涉及部分算法的工作,由于对方部门人员变动等问题,主动承担了部分 Python 代码的开发。
为了给枯燥的工作多一点色彩,在爱折腾的兴趣驱动下,终于入门并爱上了 Vim,成功删除了 Pycharm IDE。甚至进一步改变了写代码的思维和方式,也为未来创造了更多可能性。
参考之前的博客《Henry's IDE to VIM Cheatsheet》。
今年读过大约 10 本书,既然能坚持读完,自然都是值得推荐的:
年初期间,我一度很迷茫。当生活失去方向,不如静下心读几本书,自然源源不断涌出新的灵感。
颗粒无收的一年,sad
当然通过打乒乓,认识了不少朋友。但还是期望认识不同的人,了解不一样的世界和活法。如果你生活或路过上海,不妨邀请你一起喝杯咖啡 ☕️
毫无进展。
突然回忆起,四年前做过一次大白的分享(告警降噪定位的后置系统)。当时老板的老板问到如何保证大白系统自身的稳定性,i.e. 监控自身的稳定性,防止告警漏报。
回去被老板一顿臭骂,说这还不简单,做好预案冗余即可,如果系统出现问题,支持快速切换。最近这句话一直在脑中浮现,因为套到人生也是一个道理。
而当前工作带来的收入,对于整体经济状况,正如一个随时会爆炸的单点 DB 依赖,需要竭尽全力 fix。
众所周知荒谬封控的一年,除了年底小探崇明岛,基本在家平躺。期望新的一年更多探索世界✈️
昨天是段历史,明天是个谜团,而今天是天赐的礼物,像珍惜礼物那样珍惜今天。
BTW,分享 《蛤蟆先生去看心理医生》 书中关于人生状态的二维坐标,让人受益匪浅:
每当对伴侣过于挑剔,或出现情绪化时,如上坐标都会浮现闹钟敲响警钟,让自己回到一个成熟的“大人”状态。
Life is diverse, try something new
最后推荐一期播客:《Software World Tour With Son Luong Ngoc》。
以前打乒乓时,以为防守等对方失误就能赢下比赛,后来发现只有主动进攻才能赢得未来。很多时候,仅做出 5% 不到的改变,可能会带来意想不到的巨大变化。
历年年终总结:
]]>万幸 Python 虽然是动态类型语言,但经过多年的发展,类型注解已逐步成熟。刚好十月底 Python 3.11.0 发布,让我们一起看看又引入了哪些新特性呢?

TOC:
痛点:15 行 set_scale 方法返回基类 Shape,若继续调用 16 行 set_radius 方法,会导致静态类型检查器报错:提示找不到该方法。
1 | from __future__ import annotations |
解法:引入 Self 关键字规避该问题。
1 | from __future__ import annotations |
痛点:虽然入参已提示为 Array 类型(任意维度),但需进一步明确类型为 Array[int] or Array[int, str, float]
1 | def add_dimension(arrar: Array): ... |
解法:新引入 TypeVarTuple 关键字代表可变长度的一坨类型(number of types),并支持使用 * 关键字展开。
1 | from __future__ import annotations |
痛点:如何规避 sql 注入等问题(特别是 f-string)。
仅通过文档提示用户是远远不够的,有没有可能直接在静态检查中显性提示用户?(#6)
1 | def run_query(sql: str, *params: object) -> ...: |
解法:新引入 LiteralString 关键字,代表仅接受文字字符串类型,实现静态的注入风险异常提示(#8)
1 | from typing import LiteralString |
针对 PEP 589 引入的 TypedDict,新增 Required & NotRequired 关键字。
如下若属性 year 标记为必填,静态检查则会直接报错。
1 | from typing import Required, TypedDict |
痛点:第三方库的数据类(例如 Django 中的 ORM model、attr 库等),各自提供类似 @dataclass 的语法,但静态类型解析器不可能一一适配。
1 | import attr |
解法:引入了 dataclass_transform 提供统一的“协议标准”后,自动“合成”对应的类型注解,让静态类型检查器将第三方库的数据类当作 dataclass 一样统一处理,包含:
__init__ 方法__eq__, __ne__, __lt__ 等魔法方法(可选)frozen 选项的静态解析,字段是否不可变field specifiers,e.g. 字段是否提供了默认值举个例子:
1 | from typing import dataclass_transform |
题外话
但个人观点这句话仅看到了表象,设计模式初衷还是帮助我们编写更加优雅的代码,背后的目的与语言本身无关。
这篇文章以大型项目痛苦之源 Python 语言为例,通过近期工作中的两个实践案例,尝试分享如何通过常见设计模式,编写可扩展可维护代码的一点点经验。
近期公司内部发起告警阈值托管项目,故名思义通过历史时序数据,自动学习并清洗合理的告警规则+阈值。解放运维人员双手的同时,通过程序自动化的方式保证更高的准确率/召回率。
为了规避智能算法黑盒的弊端:用户难以理解告警触发逻辑,进而一步无法调节业务预期 :(
所以项目初期针对不同类型的时序指标,基于人的专家经验,提炼了一系列告警规则模版,例如成功量下跌、成功量跌零、失败数上涨、历史新增异常等等)。
理想效果:用户输入一周预计告警个数后,清洗模块自动输出可理解的静态告警规则..
清洗模块代码落地的过程中,发现不同“模版”清洗的流程大同小异,无非 1)拉取历史数据,2)数据预处理,3)特征提取, 4)上下限阈值计算等。
自然而然地将整理清洗流程,抽象固定为 pipeline 基类,不同“告警模版”理论只需实现对应的「特征提取」逻辑即可,但如何进一步兼顾清洗流程的扩展性呢?
例如:
这时曾拜读的 tomcat 源码 Lifecycle 突然跃入脑中!
有没有可能将上述的“个性化”处理逻辑,以事件的方式动态注入至 pipeline 中,最终在不同阶段的“埋点”触发:
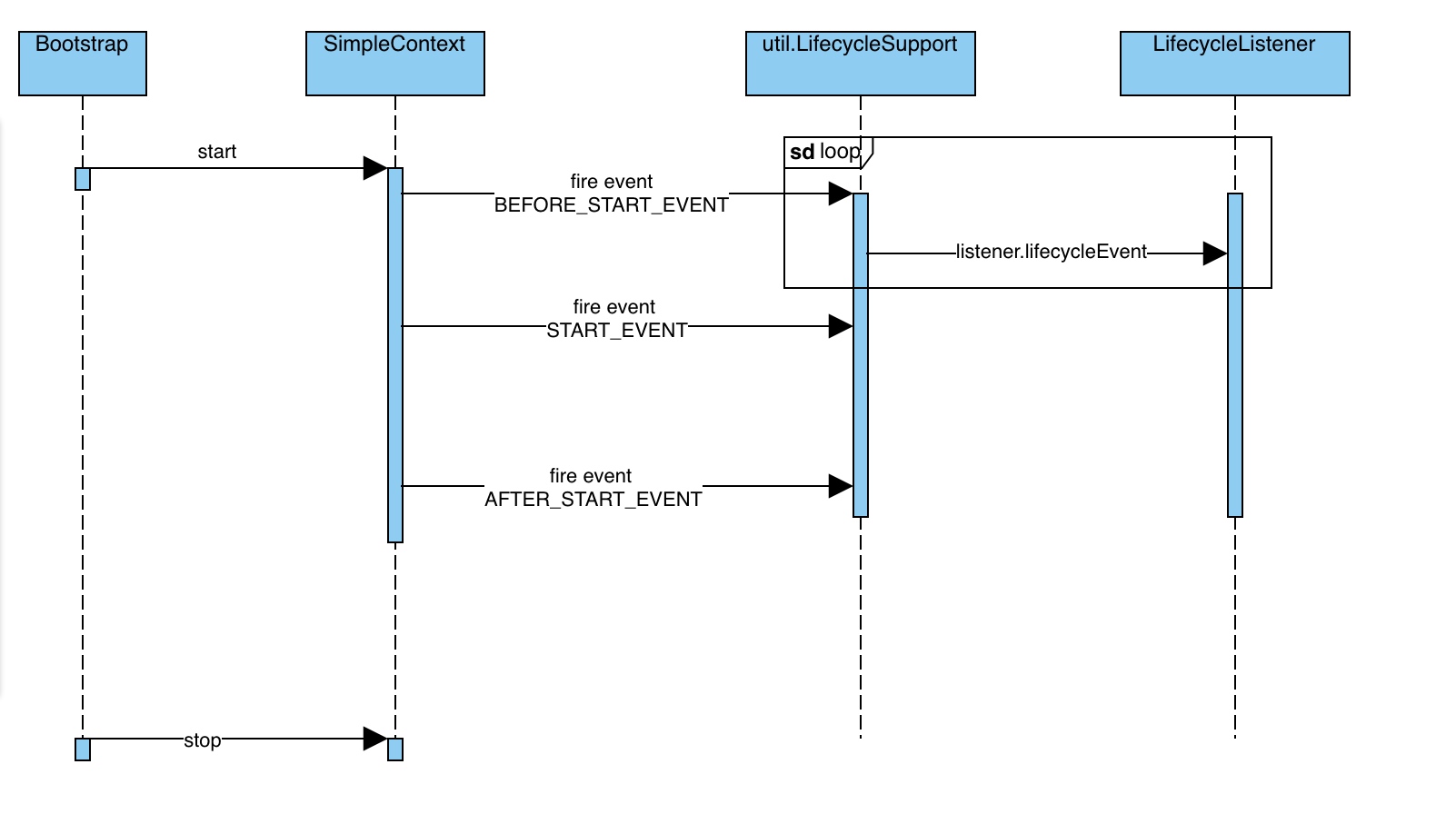
类图参考: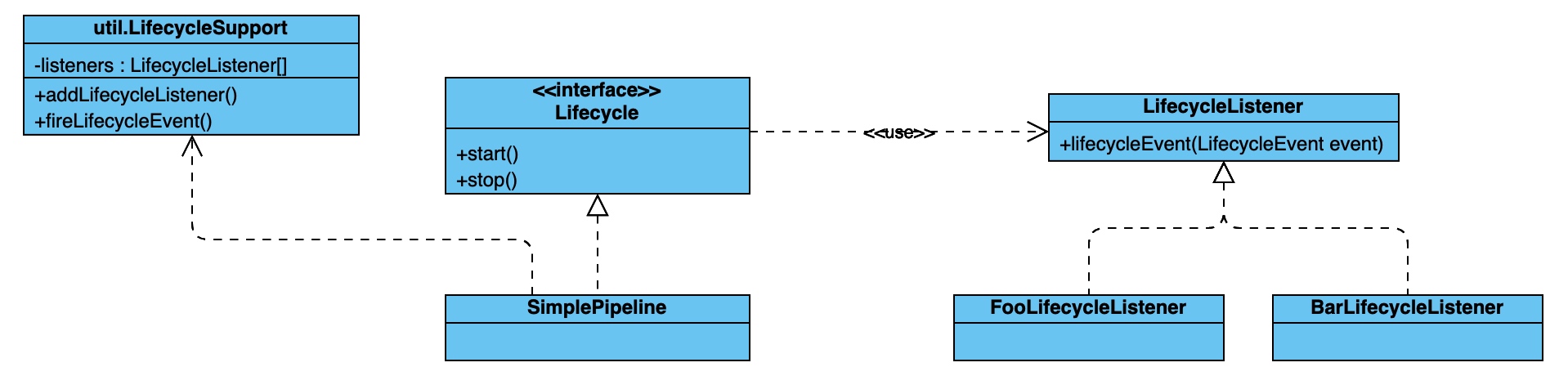
改造后的 pipeline 片段:
p.s. 完整代码参考:https://github.com/daya0576/python_design_patterns/blob/master/observers/pipeline.py#L7
1 | from abc import ABC, abstractmethod |
最终执行效果:
1 | pipeline = SimplePipeline() |
如上 Lifecycle demo,本质上为“观察者设计模式”的一种实现。清爽解耦的代码,只有在自由灵活新增代码逻辑的时候,才能懂得它的好。
上文清洗逻辑成功落地后,如何针对不同监控项,覆盖正确的「告警规则模版」成为了新的难题。
不难理解若监控包含耗时/失败数指标,直接覆盖耗时上涨/失败数上涨告警规则即可。
但假如判断有误,针对失败量监控覆盖「跌零规则模版」,最终告警显示 PROCESS_FAIL 错误码 10m 跌零,请立即处理,那真的要笑掉大牙了。
那除了人工标定,还有其他“策略”可以自动分析吗?
部分解法:
模拟如上不同场景的策略,是否可以编写直白的伪代码?
1 | success_count_risk = DefaultSuccessCountRisk() |
参考装饰器设计模式,一个更加恰当咖啡制作的例子,通过不同类的灵活“装饰”,最终获取这杯咖啡的描述与价格:
1 | // 来一杯 Espresso |
类图参考: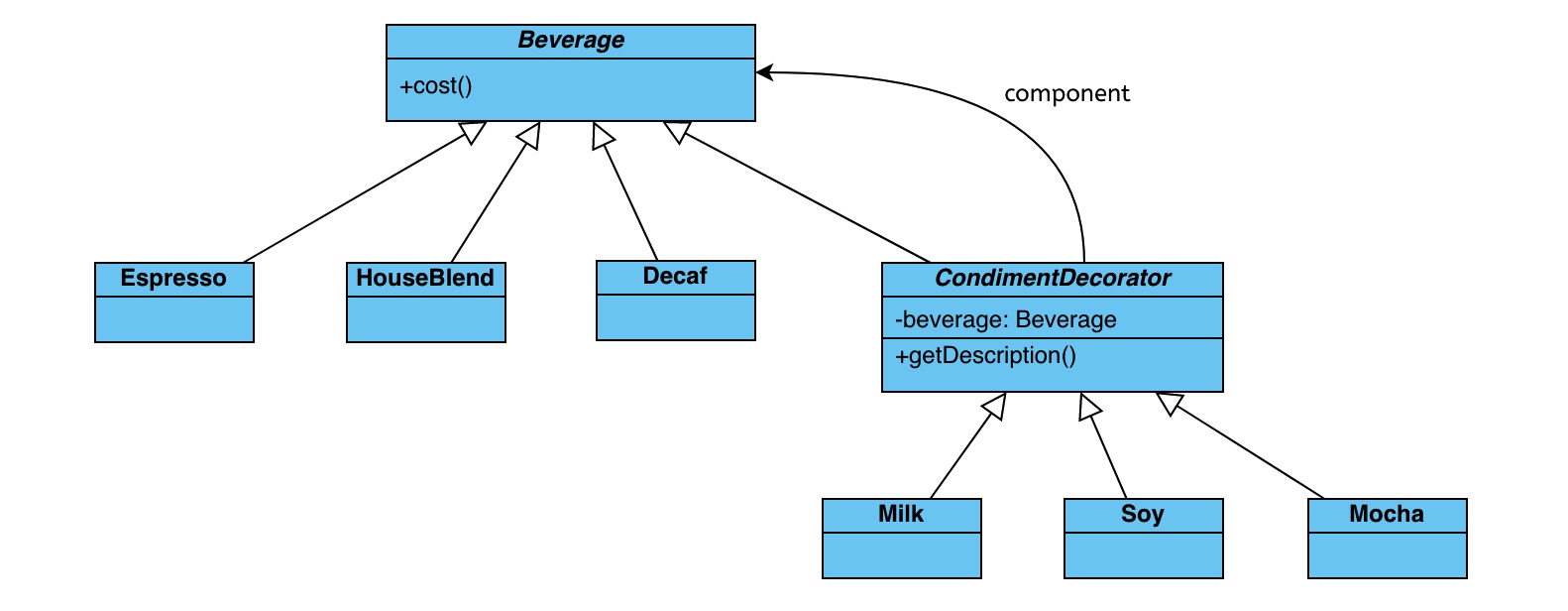
代码参考:https://github.com/daya0576/python_design_patterns/blob/master/wrapper/decorator.py
上文两个实战案例,对应观察者模式(Observer)、装饰器模式(Wrapper)两种设计模式,本质上都是“开闭原则”的一种最佳实践:对于扩展,类应该是「开放」的;对于修改,类应该是「封闭」的。
简而言之,编写代码时需要区分程序中的 易变 和 稳定 部分。对于未来可预见的新增需求,尽可能不修改原有代码,而是通过简单组合的方式快速扩展。
vim 不一定适合每个人,也不一定适用于所有的场景;若享受过程则折腾折腾消磨时间,如果不喜欢就不要徒增烦恼。
优点:
劣势:
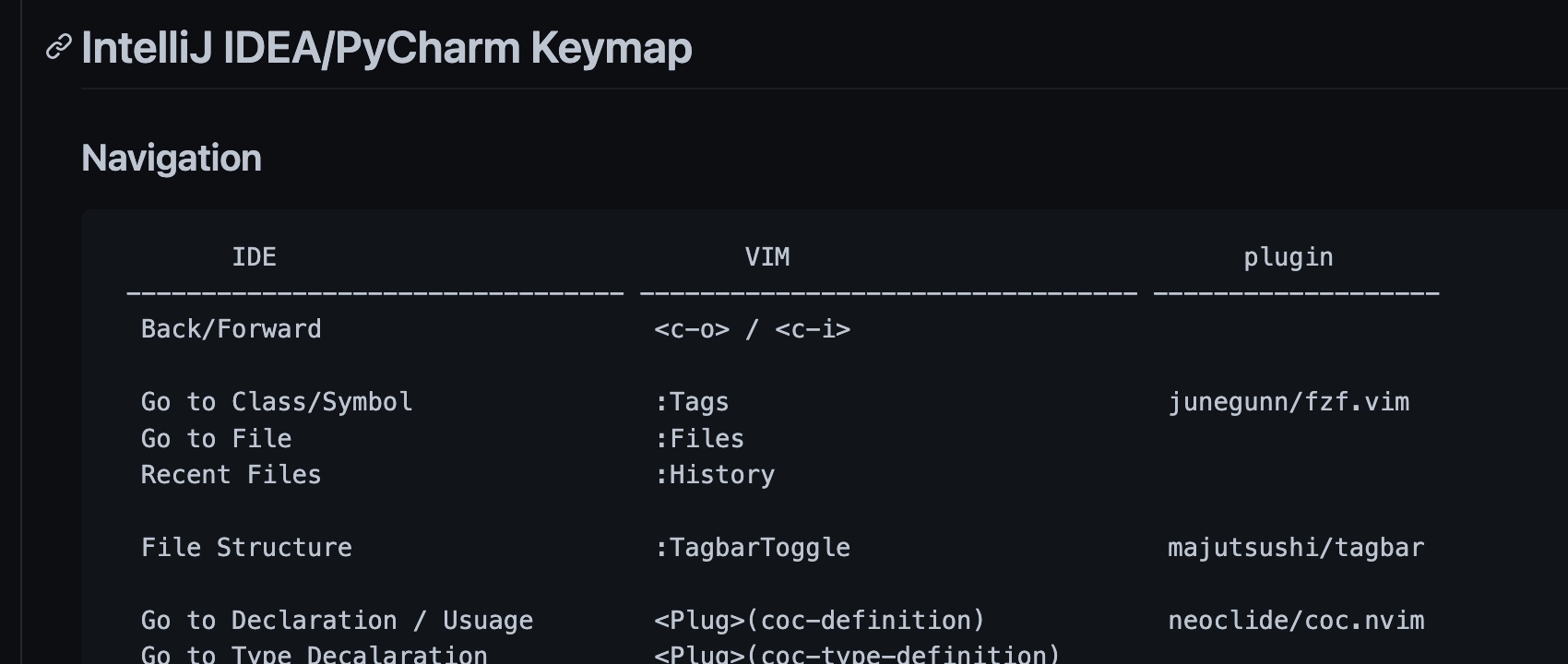
Search Everywhere,vim 的快速搜索能力更加的纯粹(原始)。翻出历史的记录 《我和 VIM 的故事》,没想到 18 年就尝试入门 vim.. 从 vimtutor 到《Pratical Vim》,《Learn Vimscript the Hard Way》
只可惜始终无法在工作中替换为主力编辑器 :(
故萌发了一个思路💡:将 IDE 中不可或缺的核心功能一一拆解后,与 VIM 对应并逐个击破。
这份个人笔记目前已归档至 GitHub 仓库:https://github.com/daya0576/ide2vim/
仅供参考,若能帮你少走一点弯路,那也是极好的~
大连用一个词形容就是很萧条,不知是否酒店位处开发新区带来的错觉,整体人气不是很旺。
与满街耸立高楼大厦形成强烈反差的是极低的入住率,随处可见空置的住宅与商业楼。有种早期发力过猛,突然停滞不前的迷茫感。
出租车司机也无一例外和我们吐槽:10年前来到大连到现在,城市面貌几乎没有太大改变。甚至过去十年近 1/3 的人口离开了这座城市,现在买房直接送车。也不知真假。

在杭州上海生活过的朋友,若走在大连的马路上,会有种危机四伏的不适感...
路上的车辆转向变道从来不打灯,斑马线也不会主动让行人。
司机还比较暴躁,动不动即喇叭套餐伺候 orz
分享个有趣的小故事,我们在棒棰岛小店买水时,有位同事被收银大妈无情的嘲笑:“这么大热天还带个 N95 口罩,快脱下呼吸一点新鲜空气吧”。话音未落还摇了摇头。
可能由于大连疫情未泛滥,难得喘息,享受几日不用戴口罩的自由时光。
最近听到一个新词:核酸产业。震惊之余有一丝悲伤,举个不恰当的例子,这就像 SRE 做监控告警,先人肉配置了一堆不合理的告警规则,然后通过机器学习、各种牛逼的算法,进行后置的降噪抑制。将告警减少了 90%+,节约了 xxx 人日,最终赢得了伟大胜利✌️

过去因为各种经历,对「东北话」的第一印象是自私与狡诈。
然而在大连短短几天,发现也有淳朴善良的出租车司机,风趣直爽的餐厅服务员,温柔安静的书店小姐姐,热情贴心机场值班人员..
也时刻提醒自己,不要轻易因为差异性,带上“有色眼镜”。

顺便推荐旅途中遇到的两本书:《爱是一种好得不得了的“病毒”》、《叩叩》
首推一家东北菜老店 “大地的春饼”,分量实惠口碑佳。三个人,点了标准三菜一汤,竖着进来扶着墙出去。
若钱包预算充足,也可试试网红店“正黄旗海鲜烧烤”,130 分的食材,两倍的价格。
人生阅历人生阅历,期望未来多争取机会去世界各地旅行。亲身经历不同的事、不同的人后,对这个世界才有更深的体会。

One quote of the day service is defined as a connection based application on TCP. A server listens for TCP connections on TCP port 17. Once a connection is established a short message is sent out the connection (and any data received is thrown away).
简而言之,通过端口 17 交互每日"名人名言"。
有没有可能亲手实践该协议?
受教主的启发,将该协议用于 github profile 的更新。
核心代码如下,配合 github action 每日定时执行:https://github.com/daya0576/daya0576
1 | def get_quote(): |
BTW, this post & profile repo are both created by vim :p
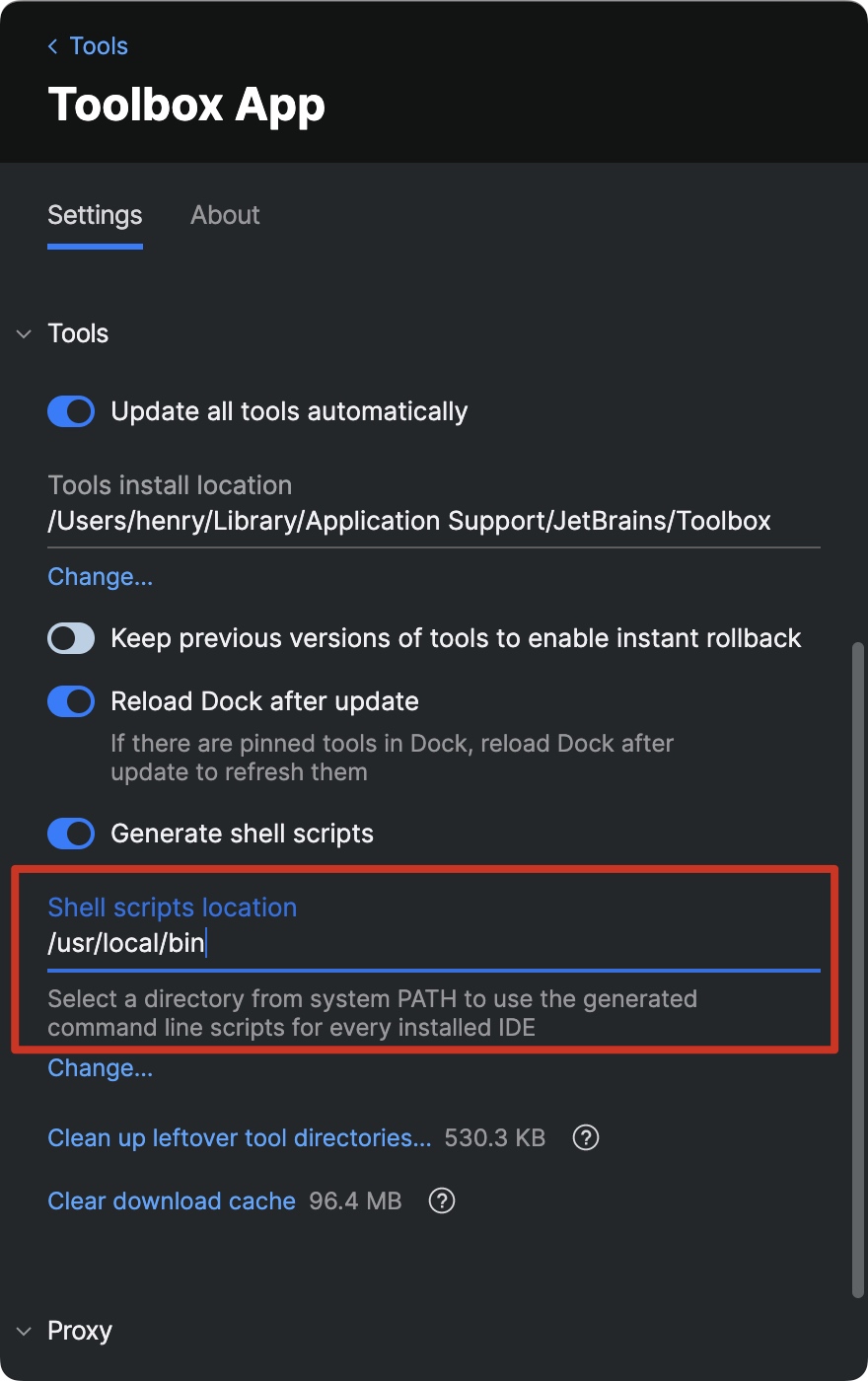
]]>Toolbox 中修改 scripts location 后,终端执行 idea xx 即可:
作为一名经验丰富的 copy/paste 手工劳动者,复制代码后如何批量修复小问题:
参考:
文件篇幅过大,如何快速找到当前文件内的一个变量或方法: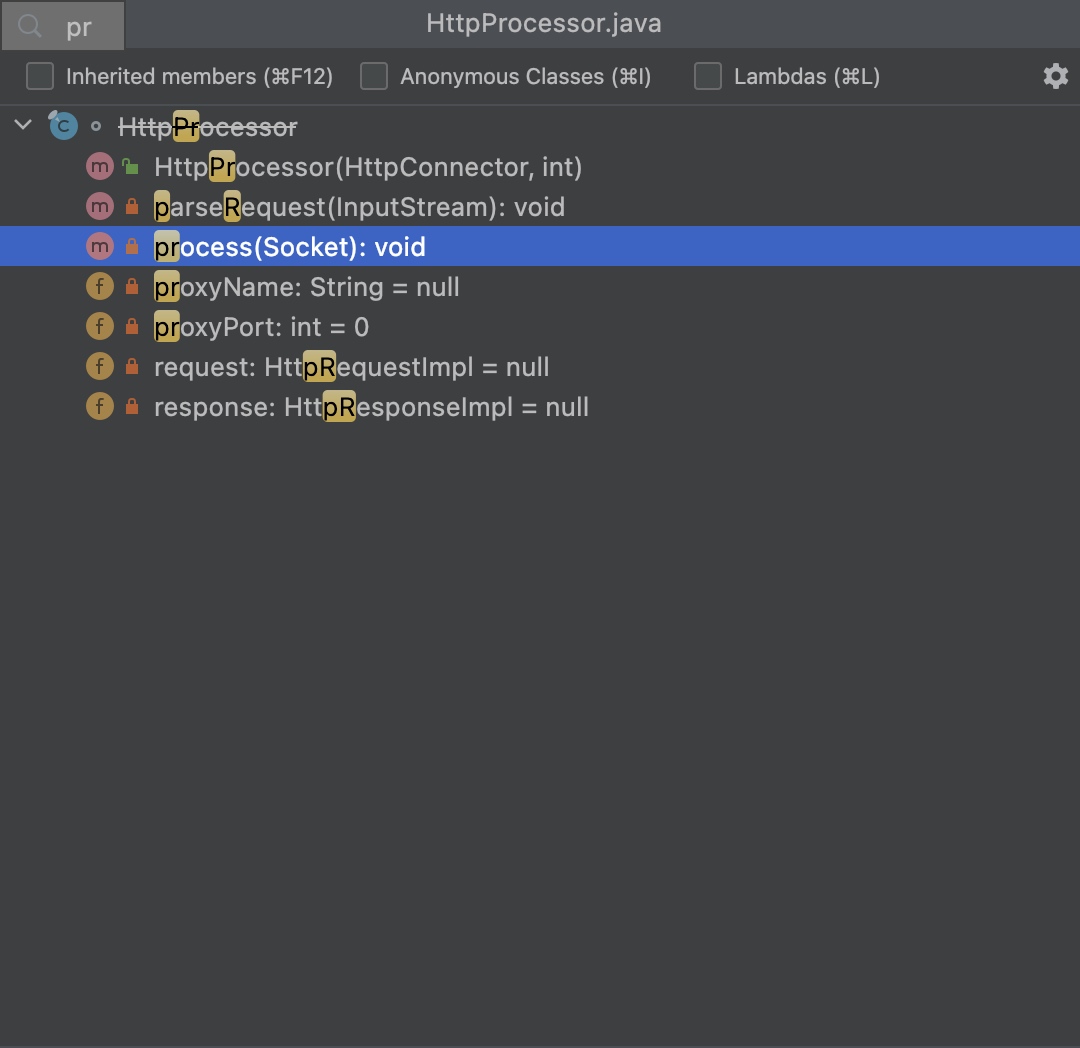
其实与 ide 无关,编辑 .git/hooks/pre-push 文件即可(记得替换 变量):
1 | branch=$(git rev-parse --abbrev-ref HEAD) |
最早应该在 Sublime 体验多光标编辑,近期给同事在 idea 中演示,对方直呼真骚:
为什么要写这篇博客?最近在读另外一本书:《置身事内》,浅浅读过收获不大,但神奇的是在豆瓣编写书评的过程中,不断翻阅与总结催化了新的收获。所以尝试编写《深入剖析Tomcat》的读书小记,通过输出的方式加深理解。
这本书籍年代久远(2004),书籍附带源码为 jdk1.4 版本...
强烈推荐以下宝藏仓库(支持 jdk8):https://github.com/tengfeipu/How-Tomcat-Works
本篇主要分享“第五章 servlet 容器”的读书小记~
Tomcat 中的四种容器(p.s. 接口可以 extend),本章介绍如何只使用 1 个 Wrapper 实例,或 1 个 Context 实例(带多个 Wrapper 实例)的应用。
注意一开始可能毫无头绪,但耐心完整阅读章节后会豁然开朗,理解为什么将亲切的将“容器”比喻为套娃 XD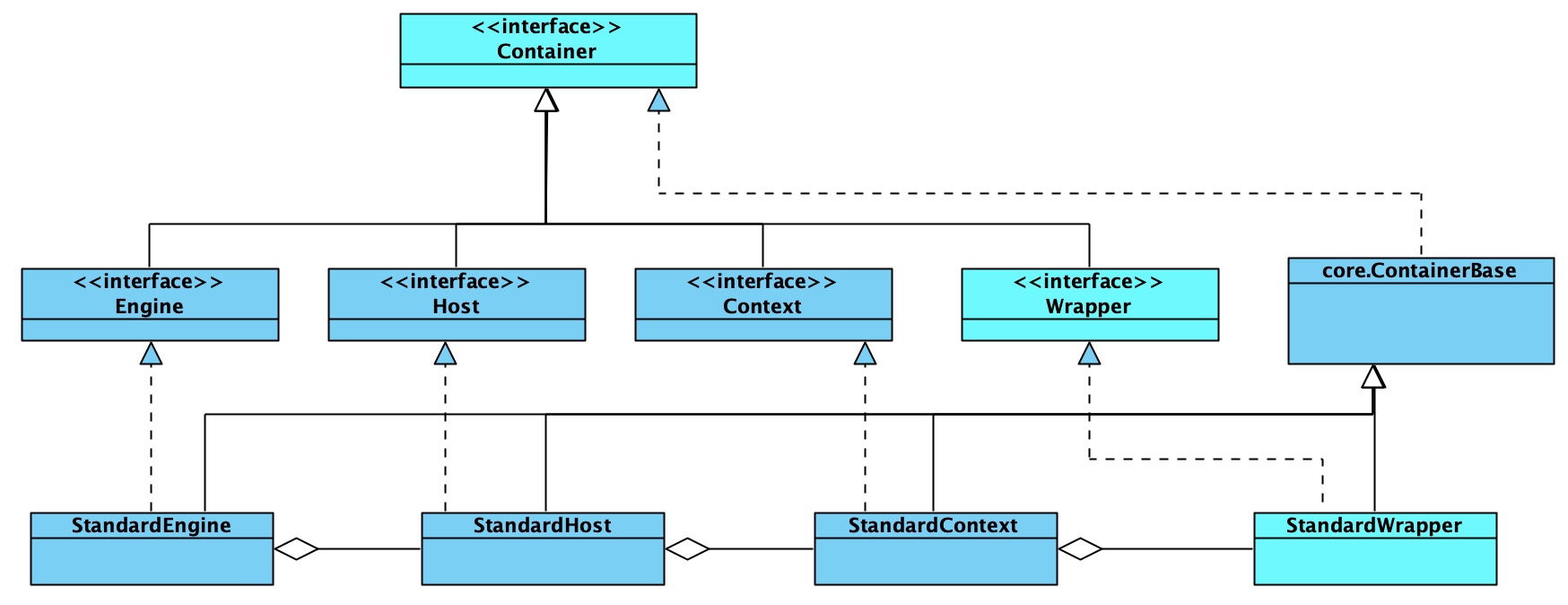
首先以最底层的 Wrapper 容器为例(通常与 servlet 容器一一对应)
类图如下,从左往右:
Loader 负责 servlet 实例的加载(输入类名,输出实例)Wraper 容器包含一个 Pipeline 用于 Valve 的调度执行Valve 负责一个具体待执行的任务,同时它实现了 Contained 接口,支持获取对应的容器(包含 valve)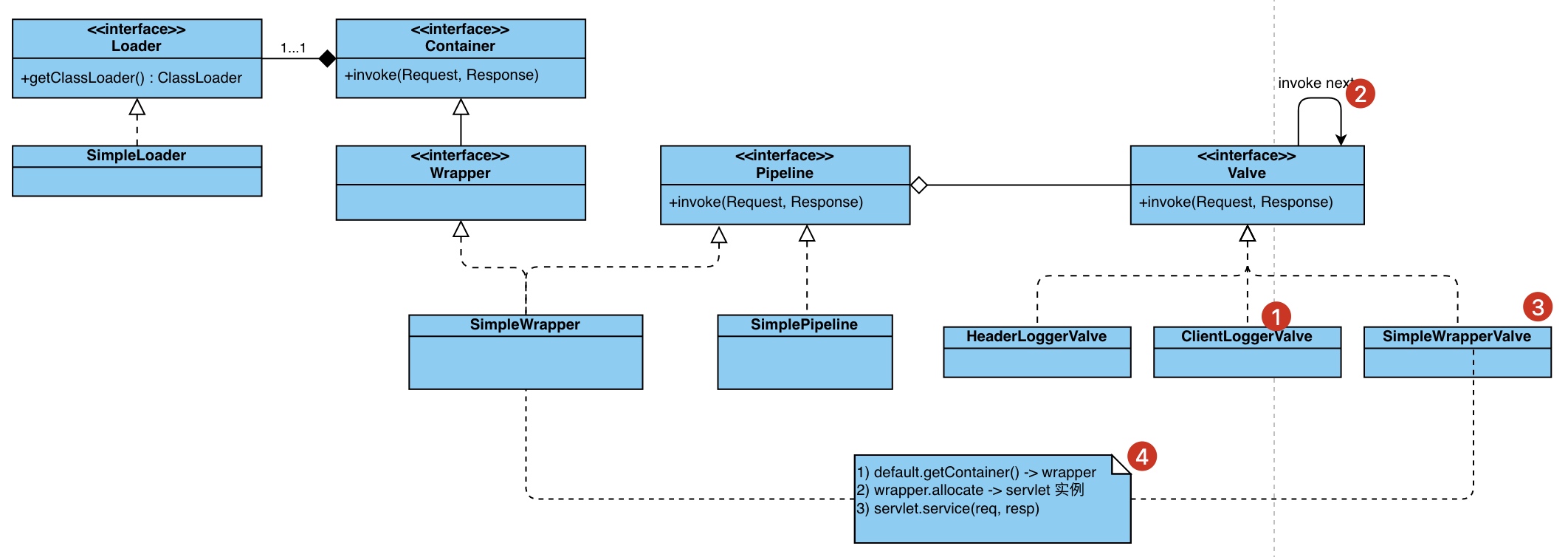
顺便结合上一章 HttpConnector 的讲解,为了处理一笔 http 调用,各个组件的交互如下: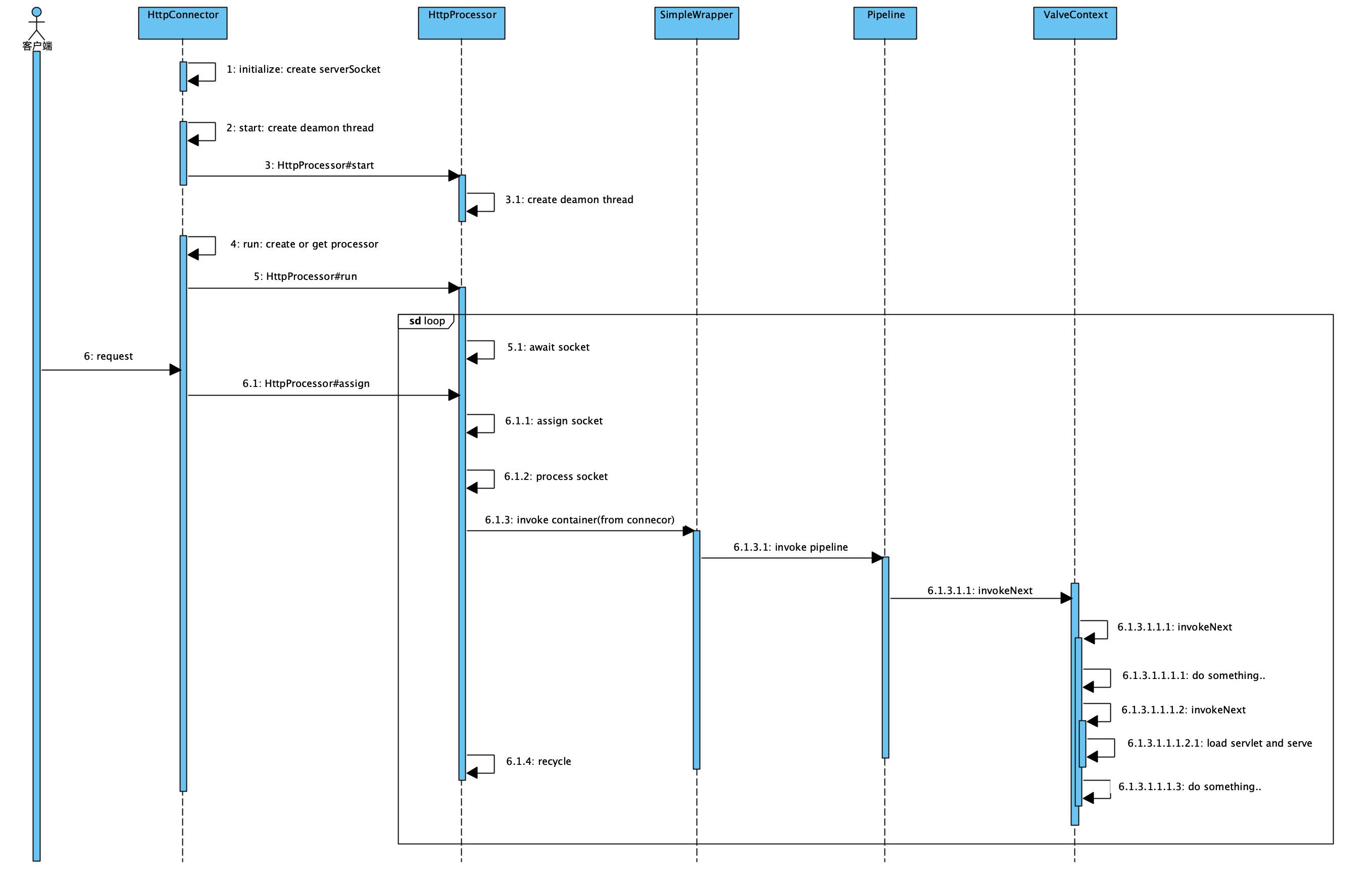
值得一提 PipelineValveContext#invokeNext 的实现非常有趣,配合 XxxValve 递归调用,依次执行自定义与默认的 Valve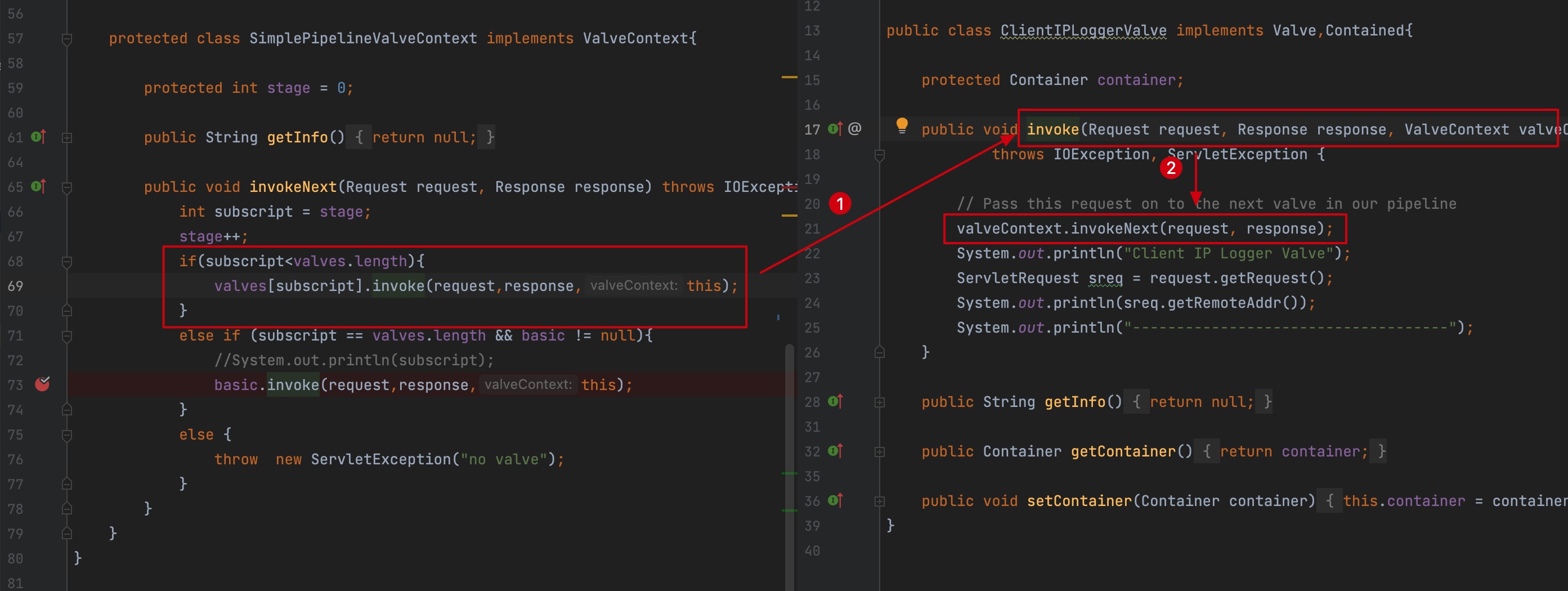
递归执行效果如下,例如 ClientIPLoggerValve 在 invokeNext 之前与之后,都可以执行自定义操作。 🤔 有没有觉得这个调用似曾相识?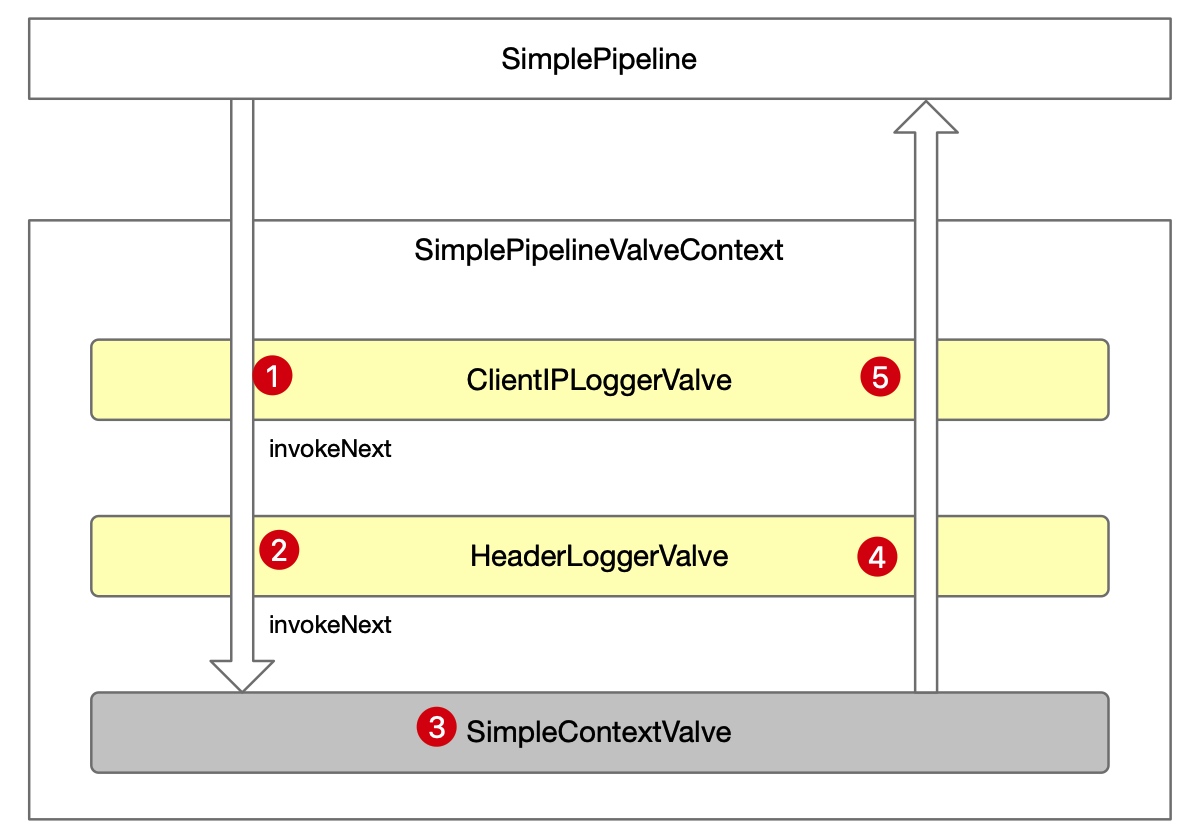
不禁让人想起 python Django 框架的 middleware 实现,有种异曲同工的感觉。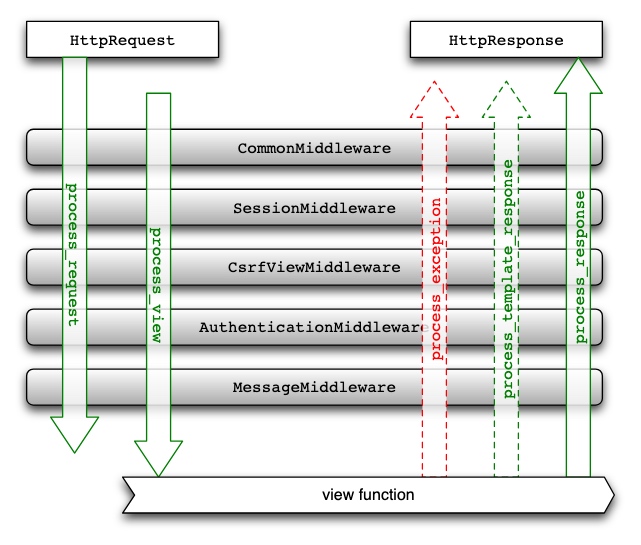
但 Django 的实现可是更加“简单”一些 :)
1 | # 定义 middleware |
一个 Context 包含多个 Wrapper 容器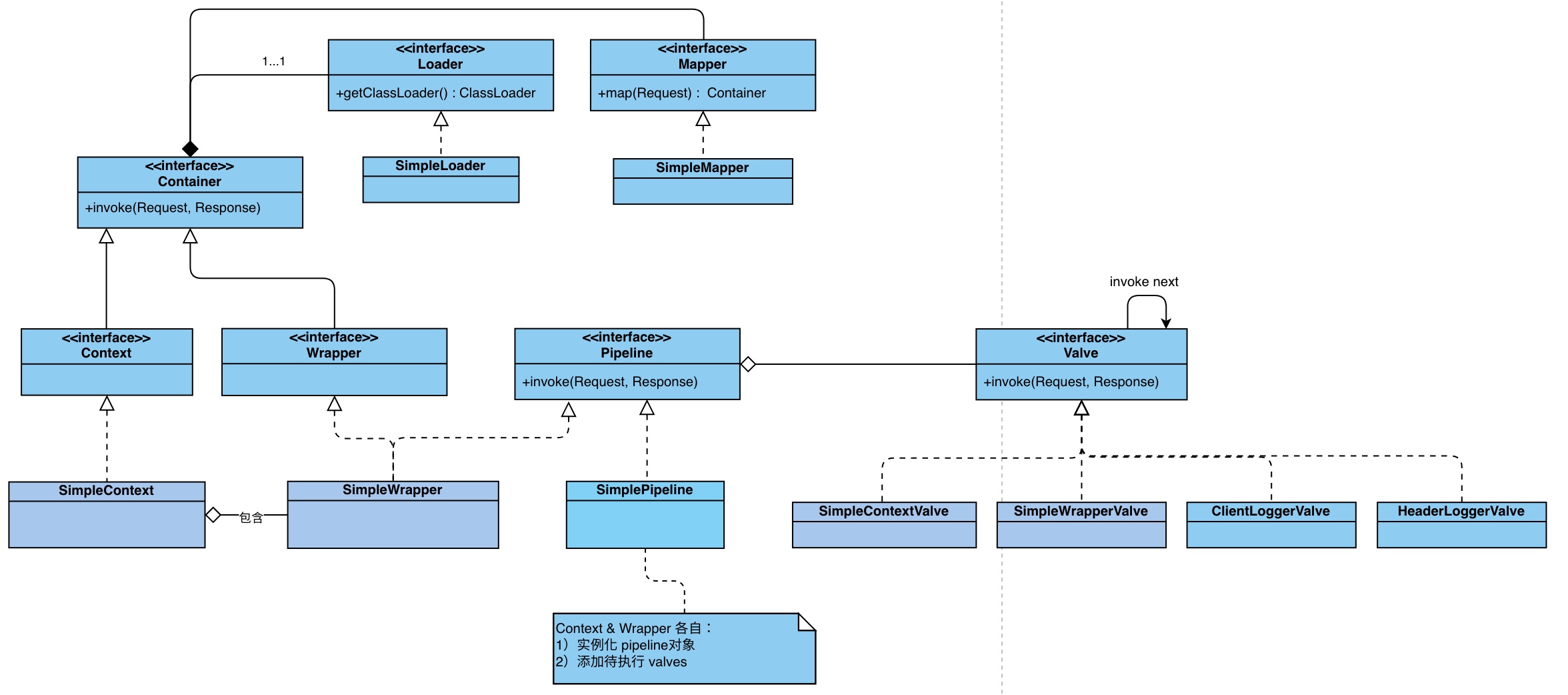
建议理清类图后阅读源码,debug 一笔 http 请求的交互,盗一张较清晰的图: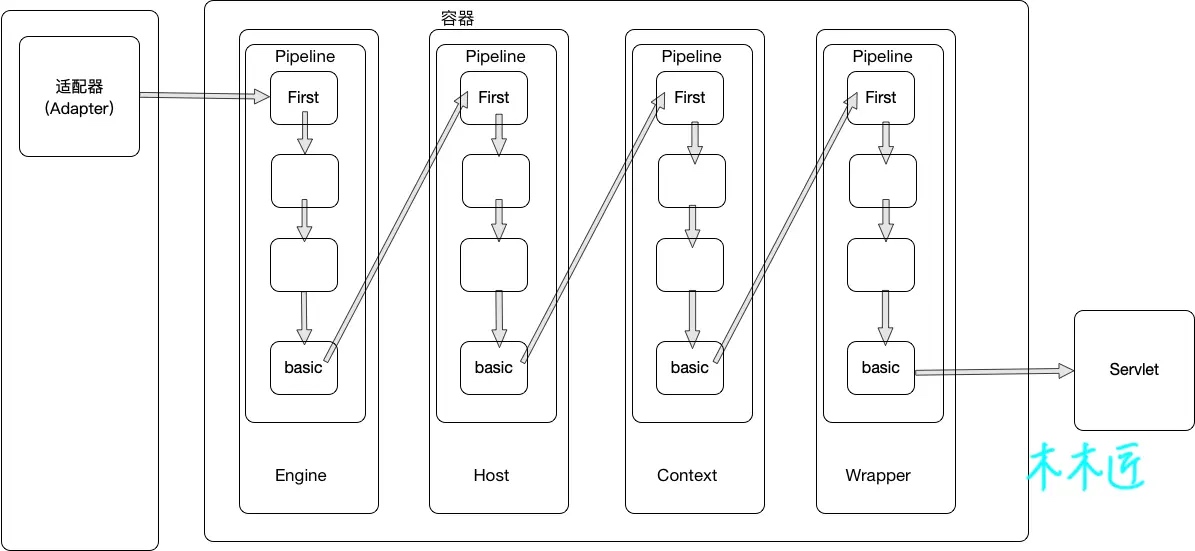
阅读本章后,感悟 tomcat 的核心在于各个「容器」并非独立的存在,而如名字一般,好比“套娃”各司其职。
最终通过分层,实现各司其职+单向依赖,降低了整体应用的复杂度。
java.lang.String)的部分行为感到困惑,抽空查阅资料后豁然开朗。忍不住写一篇博客纪念一下从源码中不难看出:
class 用 final 修饰:不能被继承 & overridevalue 变量是 final + private 的:一旦被赋值,无法被更改内存地址(禁止重新赋值),同时外部无法访问内部数组进行修改。1 | public final class String |
既然 java.lang.String 是一个类(对象),为什么通过新的引用赋值后,实际值未发生改变呢??
1 | // string |
揭开谜团前,先来看看 primary type 与 reference type 的区别:
1 | // int |
不难理解,int 作为原始型別,在 stackframe 中,变量与 value 一一对应,而引用类型(reference type)顾名思义,仅保存堆(Heap)中实例对象的内存地址。
参考去年发布的博客: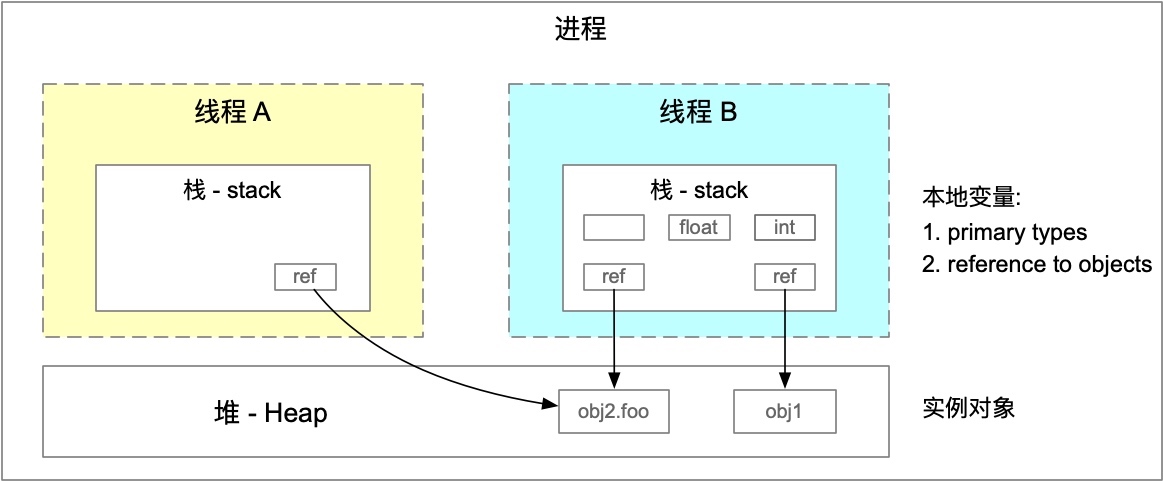
官方教程 中提到由于 string 不可变的特性,针对它的任何修改操作会返回一个新的 string 对象:
参考 java.lang.String#concat 实现:
1 | public String concat(String str) { |
但是相比于 concat 方法,String 两两相加(+)的操作符,具体发生了什么呢?
编译后我们发现,原来在 java8 中,两两相加会被编译器自动优化为 StringBuilder 实现,所以最终返回一个新的 String 对象。
1 | // 1. javac Scratch.java |
有趣发现 Python 中,字符串 string 类型逻辑,与 java 惊人的保持一致:
1 | // 不可变性 |
基于对 JVM 内存管理,与字节码的探索,终于进一步理解 java 不可变的特性,以及为什么针对它的修改操作会返回一个新的 string 对象。
期望你也有所收获 :)
]]>作为一名 SRE 每日在解决线上业务可观测的问题,突发奇想有没有可能针对自家的状况,也配置一个监控大盘?🤔
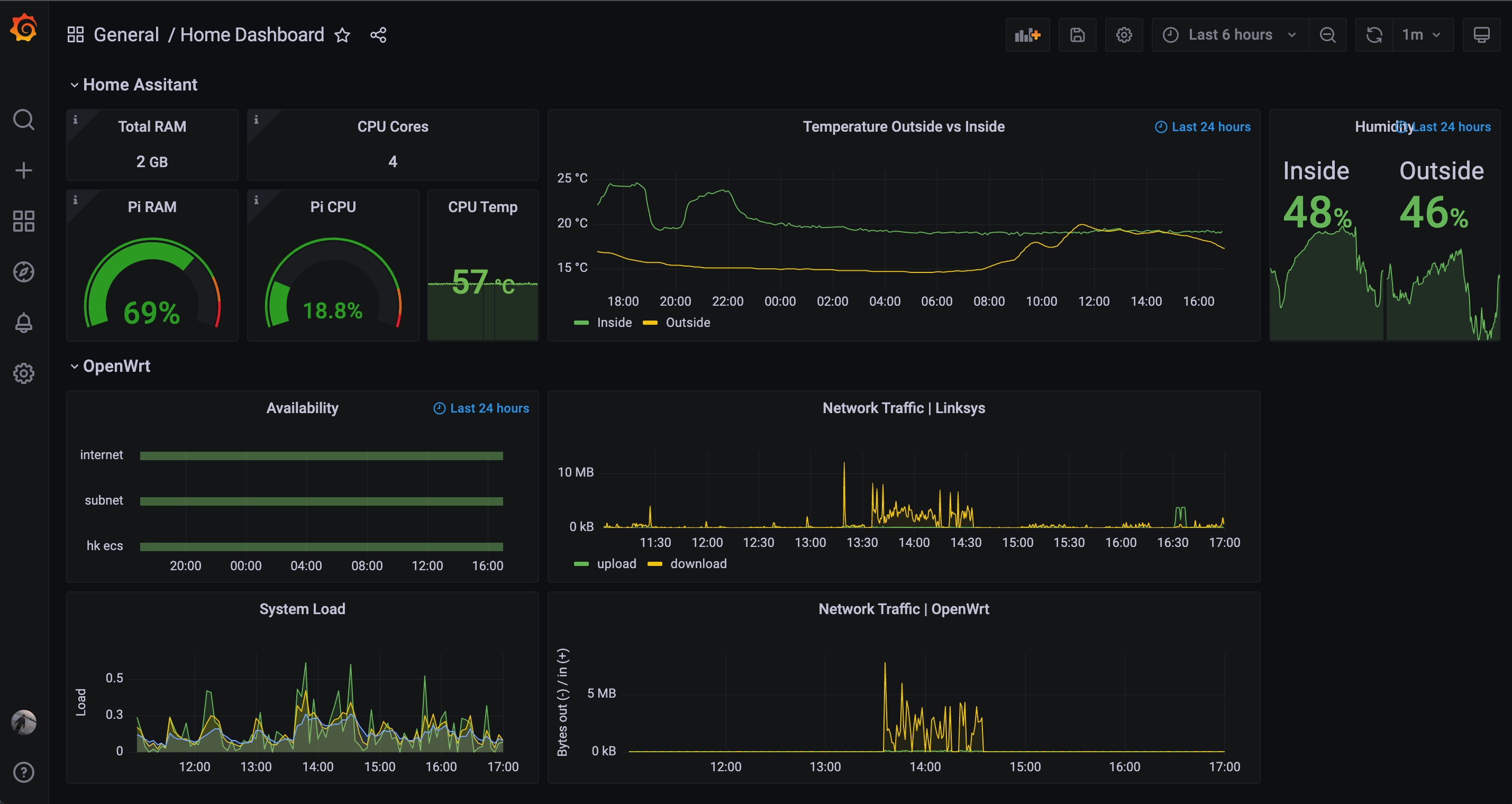
花了一天时间踩坑后初版如下,包含局域网设备负载、网络流量、湿温度趋势等信息。本篇文章将分享家庭大盘搭建的思路,希望读者可以少踩几个坑 XD
| 名词 | 解释 |
|---|---|
| HA | Home Assistant 系统,基于树莓派硬件搭建。负责家庭智能设备的管理。 |
| HA Integration | Home Assistant 系统集成,本篇文章主要用于收集数据 |
| HA Addons | Home Assistant 系统加载项,简单理解为由 HA OS 动态新增&管理的容器 |
| R2S 软路由 | OpenWrt 系统,基于 R2S 硬件设备搭建。负责二级网络的路由 |
| Linksys | Linksys 路由器,家庭网路中的主路由。 |
整体家庭网络拓扑以及关键设备如下(详情参考上一篇文章):
基于下图家庭网络拓扑(参考上一篇文章),期望最终绘制的大盘满足以下几个需求:
树莓派(Home Assistant)、R2S 软路由 等局域网设备的系统指标,例如 load、内存等..最终将整体系统分为三部分:
树莓派 相关数据(智能家居信息+系统指标),直接保存至本地 InfluxDBR2S 软路由 系统指标,通过 expert 的形式暴露,并保存至 Prometheus 中
p.s. 针对数据存储多说两句,因为博主的 HA 直接以 Home Assistant Operating System 的形式安装在树莓派中,所以可访问 Add-ons(例如直接安装 grafana 等)。如果读者是以 container 的形式安装,针对下文提到的 Add-ons 应用,在宿主机中直接用 docker 一键快速拉起即可。
这一小章简单说下我踩过的那些坑~
安装 prometheus node exporter 后,Openwrt 的实时系统数据就会通过 http 接口透出,方便下一章 prometheus 进行采集与持久化: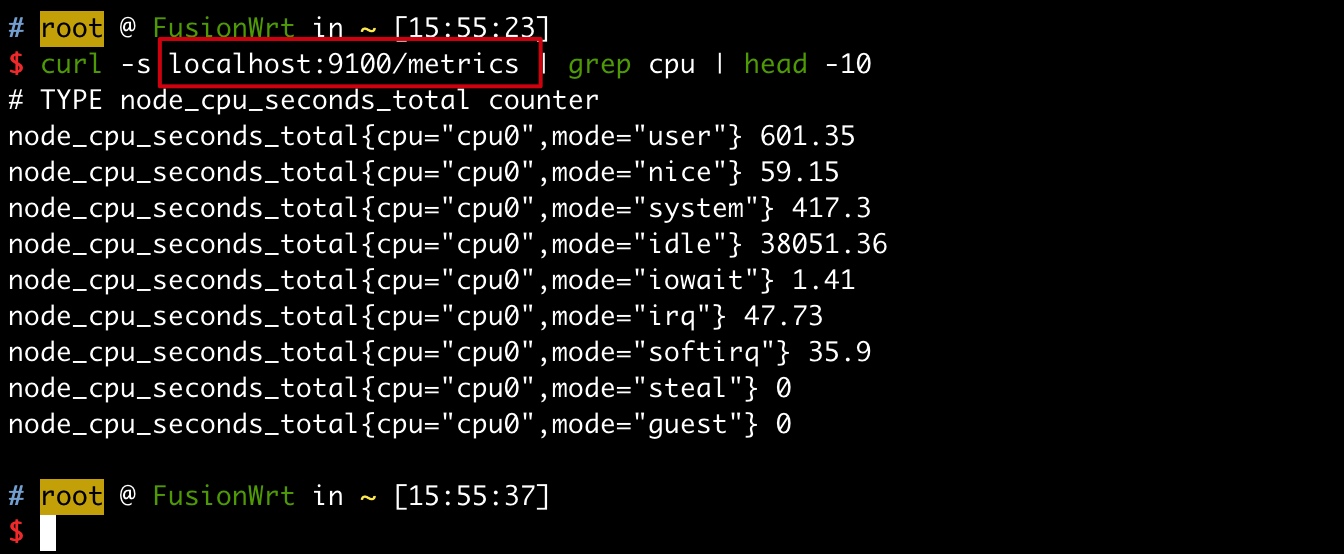
具体脚本如下:
1 | openwrt prometheus exporter |
安装 System Monitor 集成:修改 /config/configuration.yaml 后重启。
配置参考:
1 | sensor: |
HA 安装 InfluxDB 集成,配置参考(注意 host地址/数据库名称/用户名密码等信息,需根据实际情况更新):
1 | influxdb: |
HA 安装 Binary Sensor 集成,配置需要的网络探测(后续用于判定家庭网络的可用性):
1 | binary_sensor: |
HA Add-ons 中找到 InfluxDB 安装即可:https://github.com/hassio-addons/addon-influxdb
⚠️注意
这一步坑较多,有条件的朋友推荐 docker 一键拉起。
步骤:
1)因为该 prometheus addon 为测试版本(未正式发行),需更新repo后才能在ha中找到:https://github.com/hassio-addons/repository-beta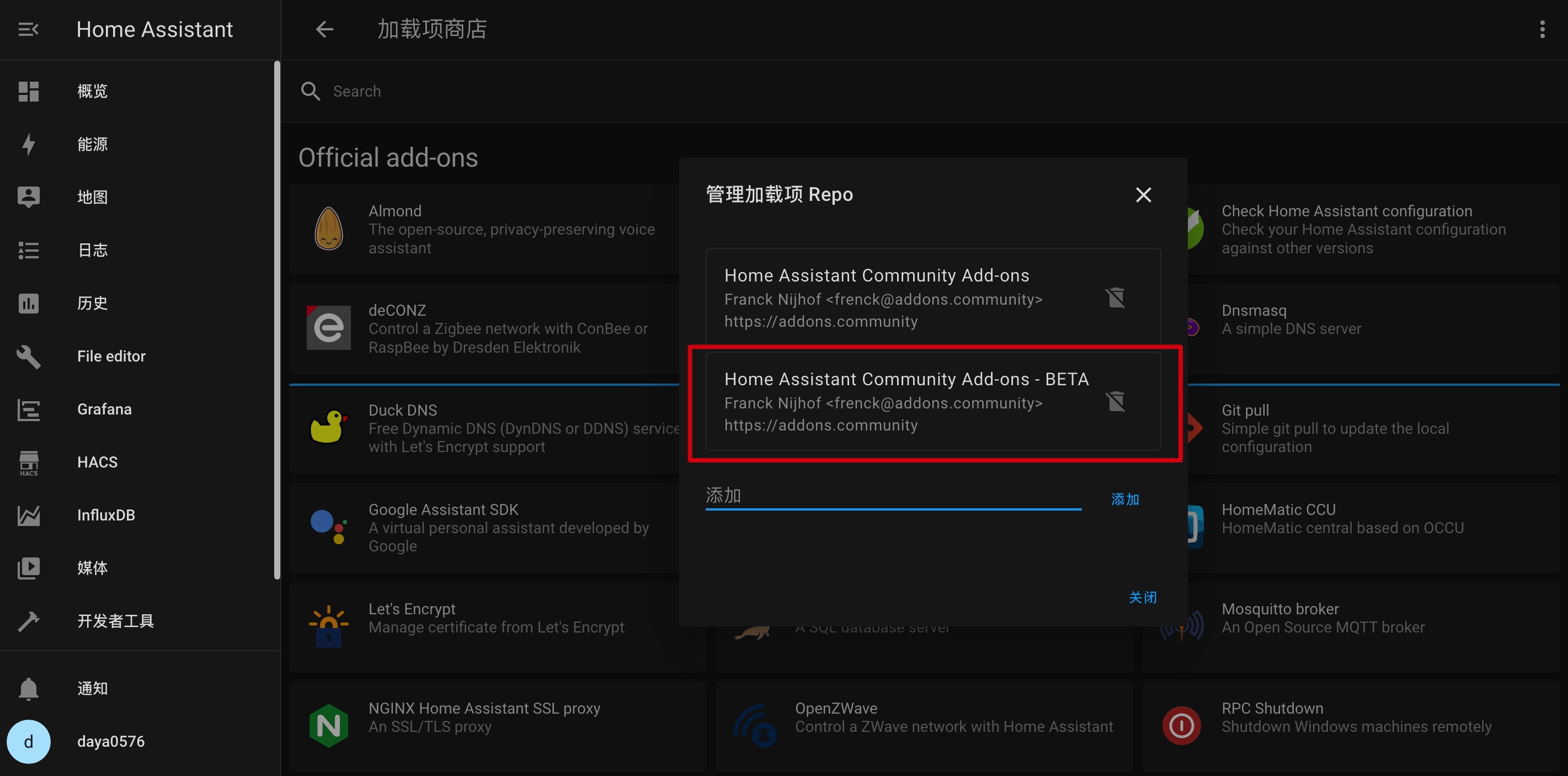
2)安装并启动
3)参考文档配置 targets 时,文件一定要以 yaml 后缀:
1 | [core-ssh targets]$ cat /share/prometheus/targets/openwrt.yaml |
4)web 界面查看 target 是否生效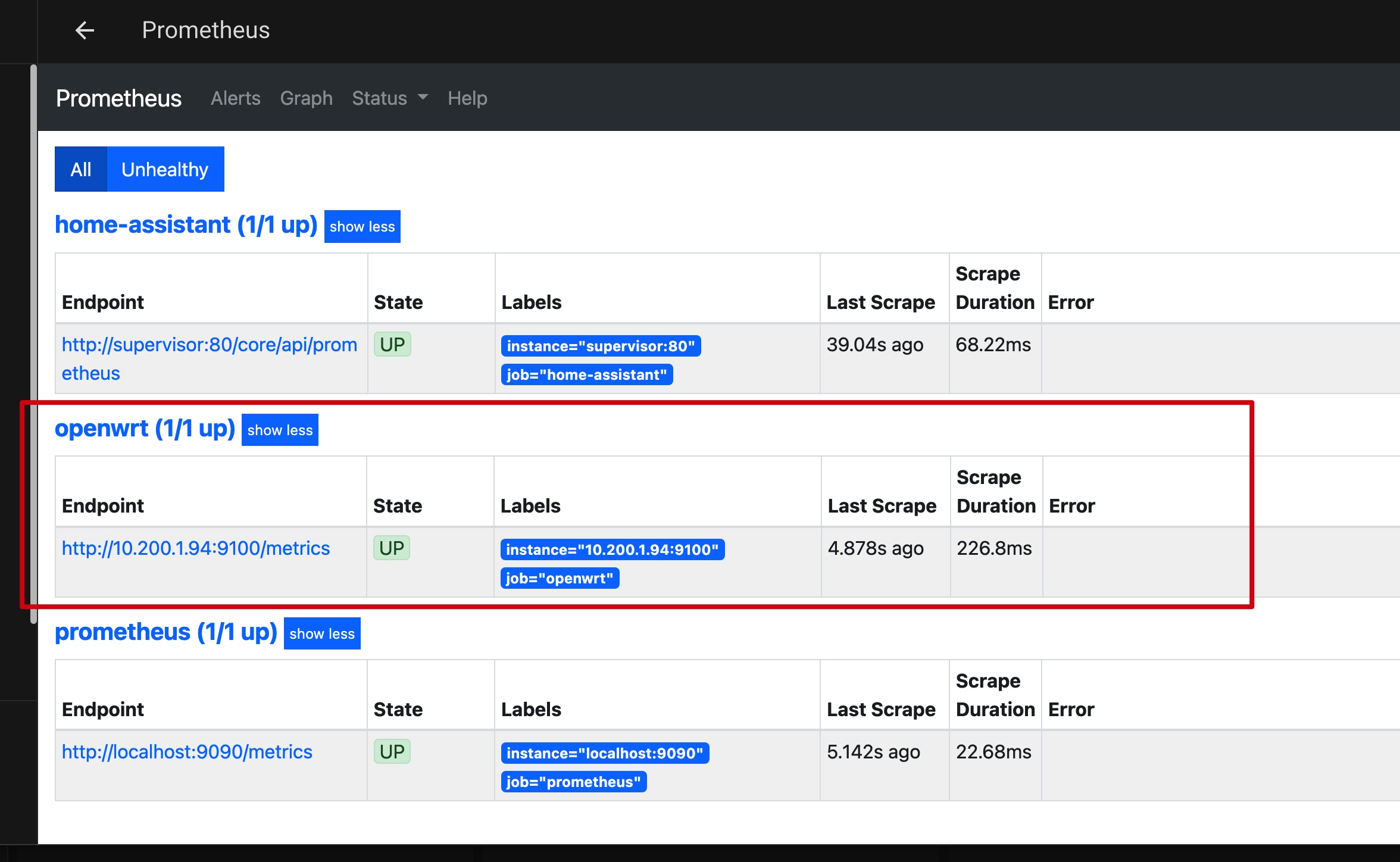
安装 grafana 后,根据上一步 InfluxDB + Prometheus 两个数据源,自由配置大盘即可。
如下为我初步配置的大盘,设备负载情况,室内室外温差湿度,以及关心的网络可用性,历史趋势等信息一目了然 ✨
这篇文章简单分享一下我的家庭网络拓扑,以及回答软路由作为二级路由后:
1⃣️ 电视设备如何科学上网(主路由模式)?
2⃣️ 树莓派 HA(Home Assistant)如何科学上网(同时开启旁路由模式)?
3⃣️ HA 如何控制二级路由子设备?
购买软路由后,首当其冲需解决电视科学上网的问题。
下图为商家推荐的模式,相当于“软路由”完全接管家庭的网络:
但个人更期望一级路由网络尽可能的纯粹(不影响老婆大人上网秒杀),所以选择将软路由作为二级路由器。
在不改变原有网络架构的情况下,配置闲置路由器,实现设备按需接入,即插即用:
顺利完成目标,畅快享用好剧!

子设备一级路由,如果也有“科学上网”的需求,但迫于各种原因无法移动至二级路由网段,例如“HA(home assistant)” 若移动至二级路由后,将无法发现家庭智能设备。
这时软路由摇身一变,承担起旁路由的职责,也就是说修改子设备的「路由」配置,指向软路由即可:
⚠️除此之外还需修改软路由防火墙与静态路由配置,请参考第三小节
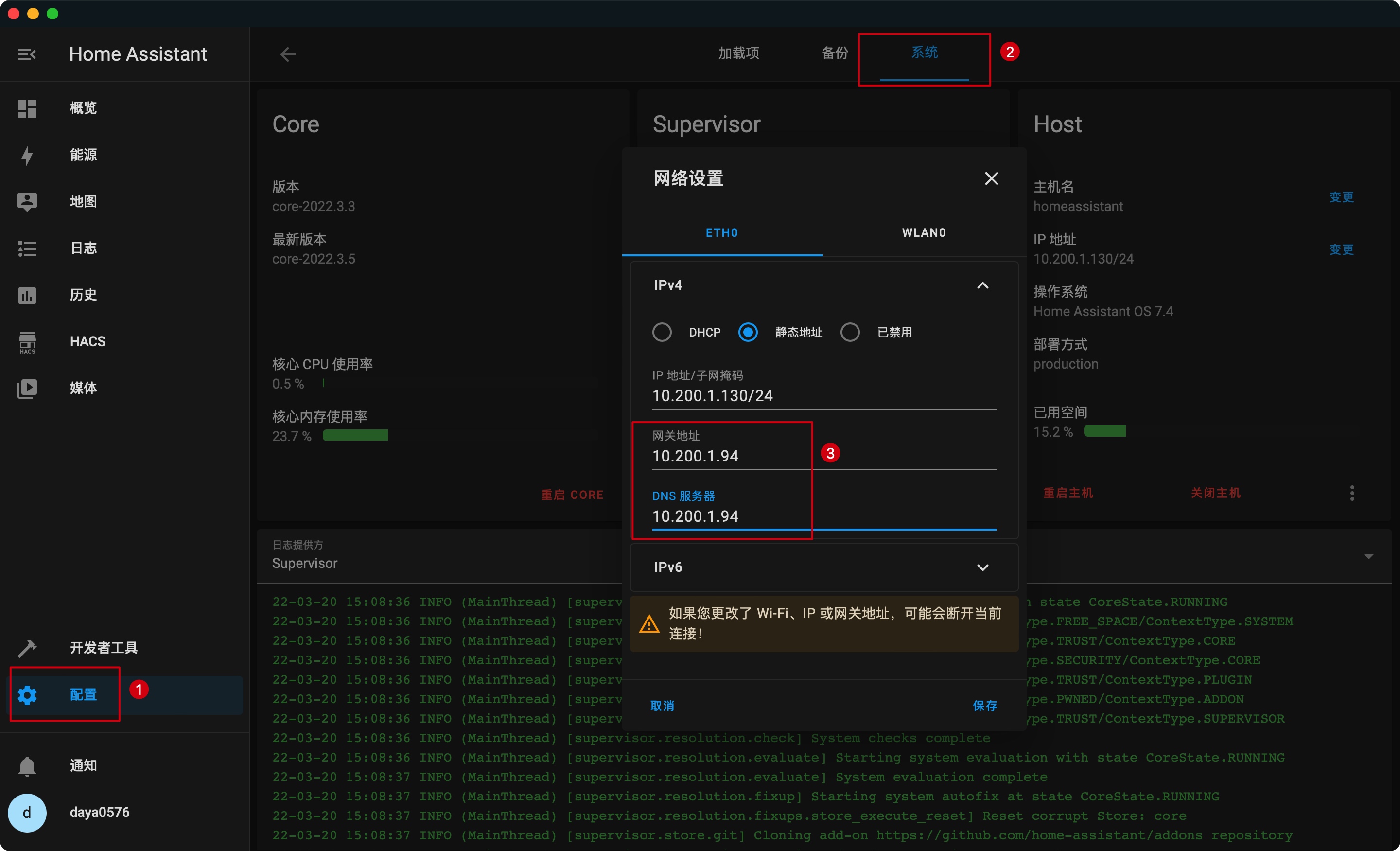
从此安装更新等操作,如丝般顺滑 🥰
引入软路由作为二级路由器后,产生一个新的问题:由于 NAT 以及防火墙的存在,下图中的“树莓派”设备,无法找到二级设备“电视”(不在同一个网段)。
最终导致无法在 HA(Home Assistant)中,控制电视与游戏机等设备😭:
所以需要手动新增静态路由(添加在 Linksys 与 R2S 路由器中),告诉访问 电视(192.168.2.170)的请求,具体应该走哪一个网关。
但是在 TP-Link 路由中,可能因为 NAT 以及防火墙的存在,迟迟无法搞定,所以新引入了一个交换机:
以下为具体修改的配置:
一级路由静态路由设置(帮助树莓派找到二级网段),以 Linksys 路由器为例: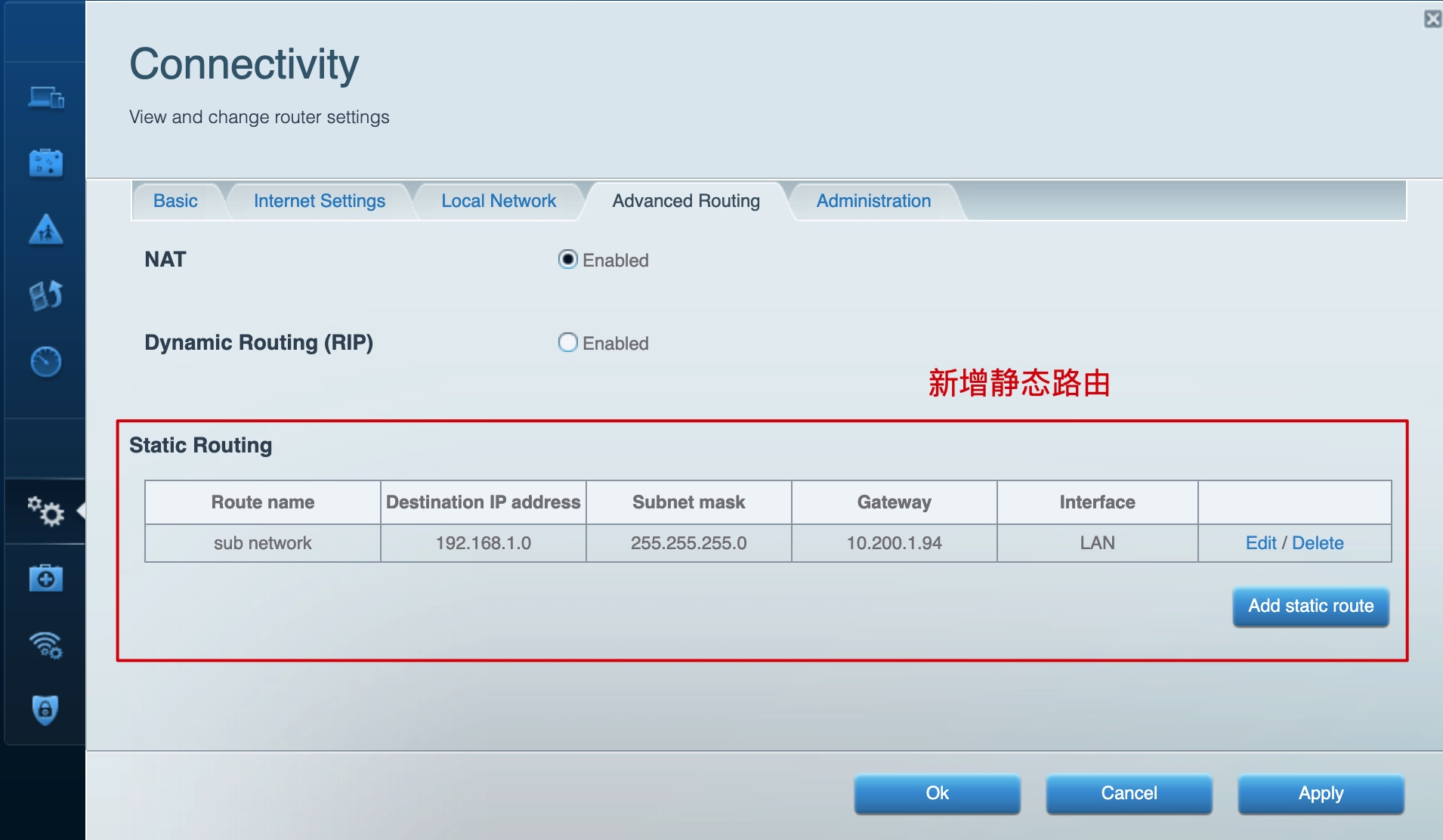
二级路由(R2S 软路由)不知道为什么没有也没有子设备的路由,
1 | route -n |
http://192.168.2.1/cgi-bin/luci/admin/network/routes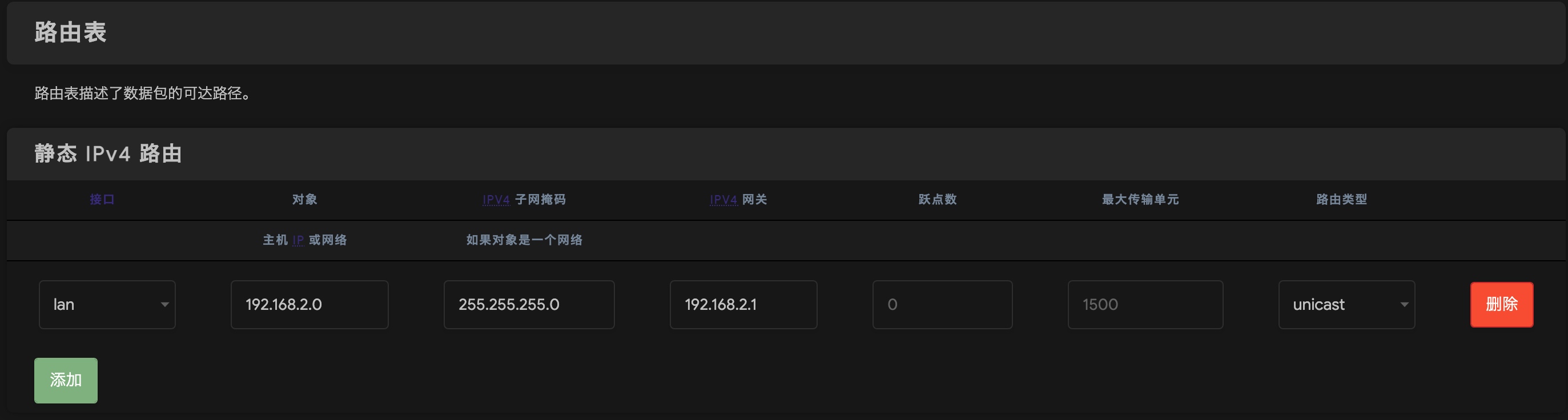
修改 网络/防火墙/基本设置 中“转发”配置,更新为“接受”: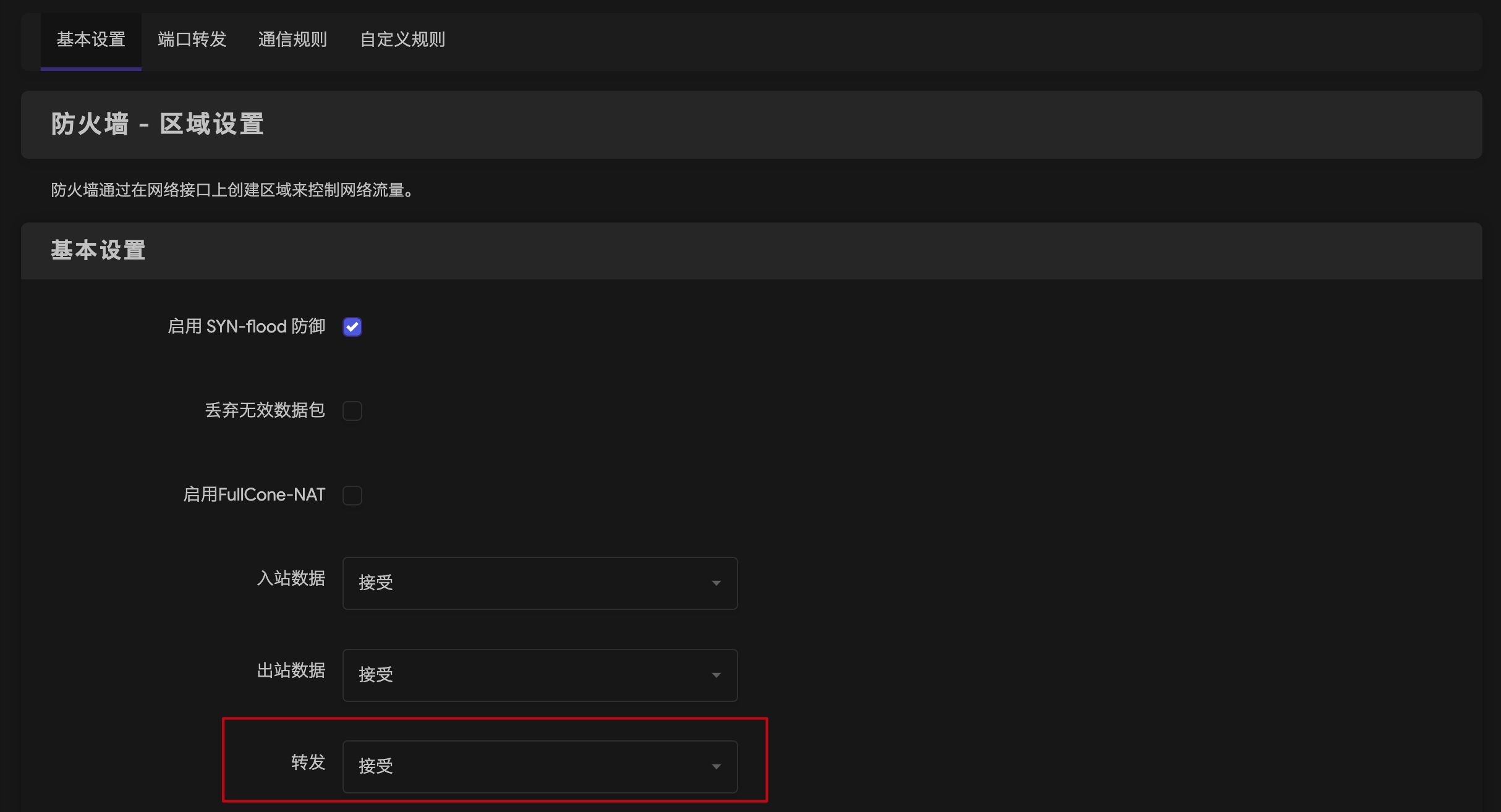
1 | ➜ /dev traceroute 192.168.2.170 |
顺利重新获取对电视的掌控权 🥰

the basic foundations of SRE include SLOs, monitoring, alerting, toil reduction, and simplicity.
最近学了个新的单词:cornerstone,而制定 SLOs,配置监控,以及告警应急可以说是 SRE 的基石。过去几年个人工作也与可用性监控相爱相杀。最近工作遇到一些瓶颈,周末重温 Google SLO 文化《Google's Site Reliability Workbook》,期望激发一些新的灵感~

SLOs are key to making data-driven decisions about reliability
众所周知,一味的追求 100% 可用率不是一个明智的决定。只有制定研发、测试、SRE一致认同的可用性目标后,才有可能实时量化风险,基于数据驱动告警应急&影响变更,最终管理好风险。
一个反例为公司内部的智能告警,为什么一直用户口碑不佳?一方面因为纯算法黑盒的不可解释性以及业务特征缺失,但更致命的原因在于缺少用户输入(各个服务重要程度)。如果针对所有服务套用相同检测逻辑,必然极难保证异常检测召回率的前提下,不断提升准确率。
The easiest way to get started with setting SLIs is to abstract your system into a few common types of components
首先将线上系统抽象分类后,分别设置 SLIs:
we base the response success on the HTTP status code. 5XX responses count against SLO, while all other requests are considered successful.
文中简单以 http 接口的 5xx 判断请求是否成功。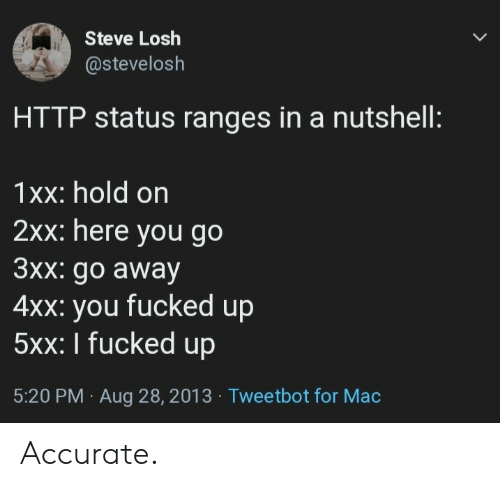
公司内部通常以业务错误码作为外部请求成功/失败判断标准,e.g. PROCESS_FAIL, UNKNOWN_EXCEPTION。
它们又被称为“灰色错误码”... 也就是说当返回给用户PROCESS_FAIL处理失败时,有可能是内部代码 npe 导致,也可能是用户余额不足,无法代表系统是否真实可用。同时受上游/下游外部影响,极大的影响告警准确率。
个人倾向第一种思路为上策:分布式系统中每个应用需决策并透出这笔请求是否会影响用户(SLO-impacting error),通过这一层风险抽象,最终统一复用一份告警规则
SLIs can use one or more of the following sources
- Application server logs
- Load balancer monitoring(文中主要指 HTTP 状态码,同时最接近用户感受)
- Black-box monitoring
- Client-side instrumentation
日常监控通常基于日志统计(白盒监控),数据来源是否过于单一?有没有可能发挥黑盒监控测试的重要性?
Once you have a healthy and mature SLO and error budget culture, you can continue to improve and refine how you measure and discuss the reliability of your services.
At Google, we test our monitoring and alerting using a domain-specific language that allows us to create synthetic time series. We then write assertions based upon the values in a derived time series, or the firing status and label presence of specific alerts.
关于监控的监控,思路比较类似:
首先理解评判告警事件好坏的四个指标:
假设 SLO 为 99.9%,以下为几种预警方式的优劣分析(最佳实践推演):
只要最近十分钟 slo 消耗破线就进行预警:ratio_rate10m{job="myjob"} >= 0.001
十分钟 -> 36小时,SLO 破线才告警:ratio_rate36h{job="myjob"} > 0.001
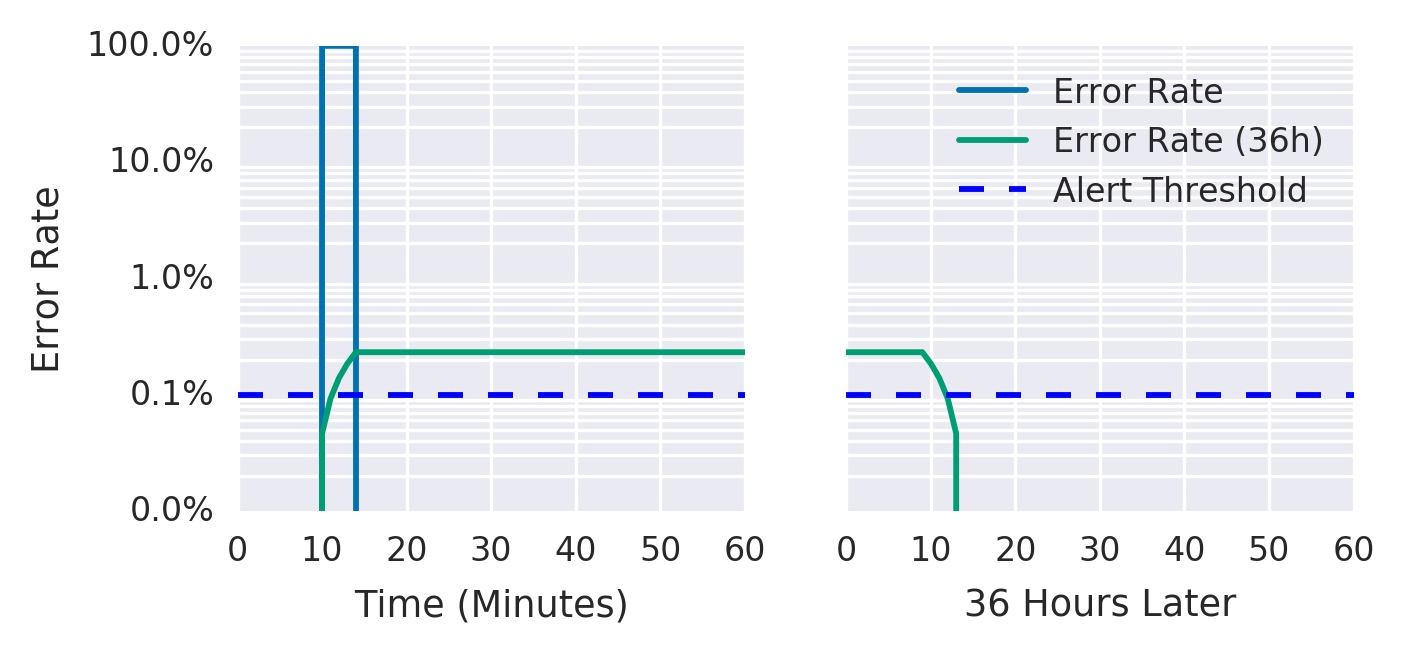
连续 N 分钟大于某个阈值(any -> all):ratio_rate1m{job="myjob"} > 0.001 for: 1h
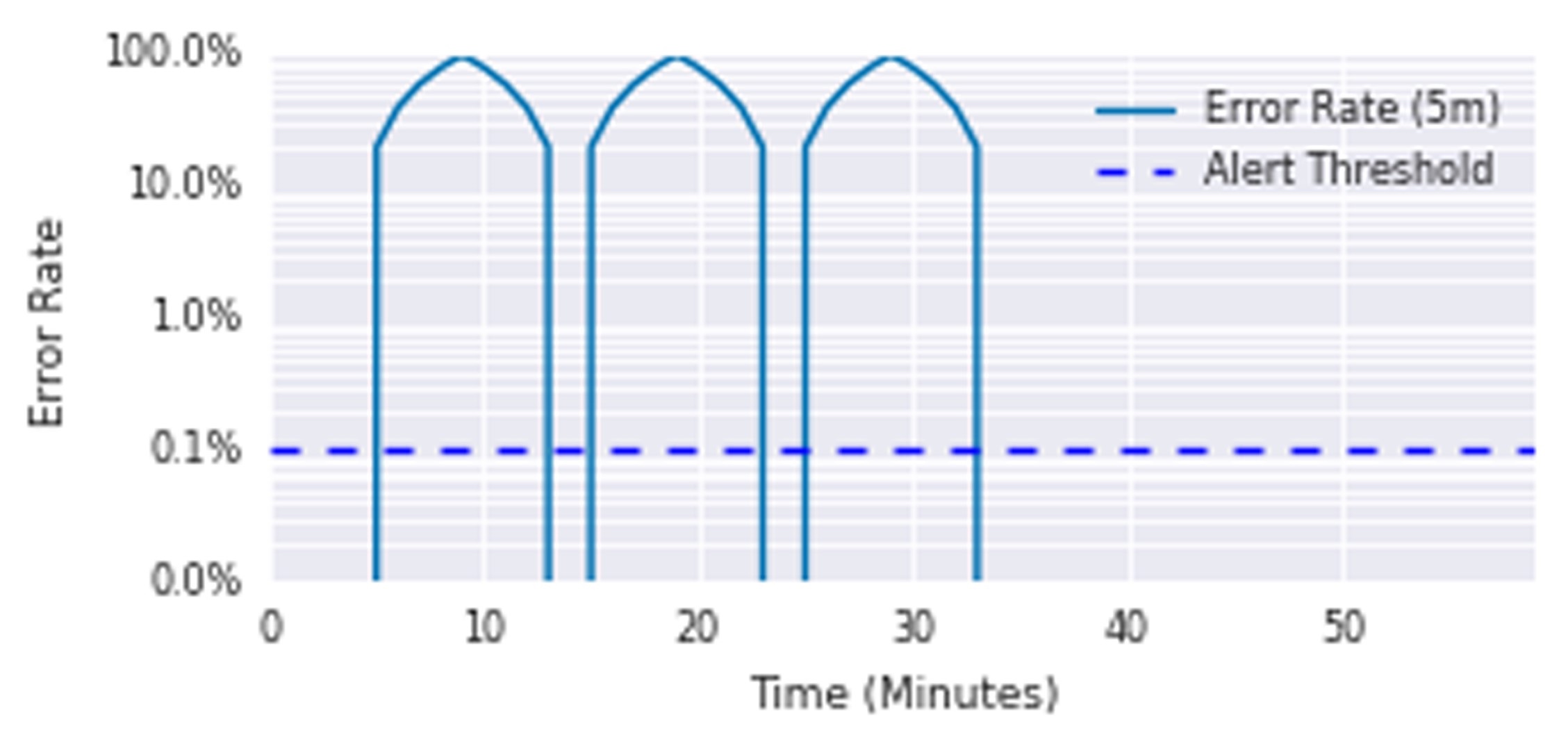
为了避免上几个方案,手动设置检测窗口的窘境,引入 burn rate 燃烧速率的概念。
例如下图,假设 SLO 为 99.9%(统计窗口为一个月 30 天):
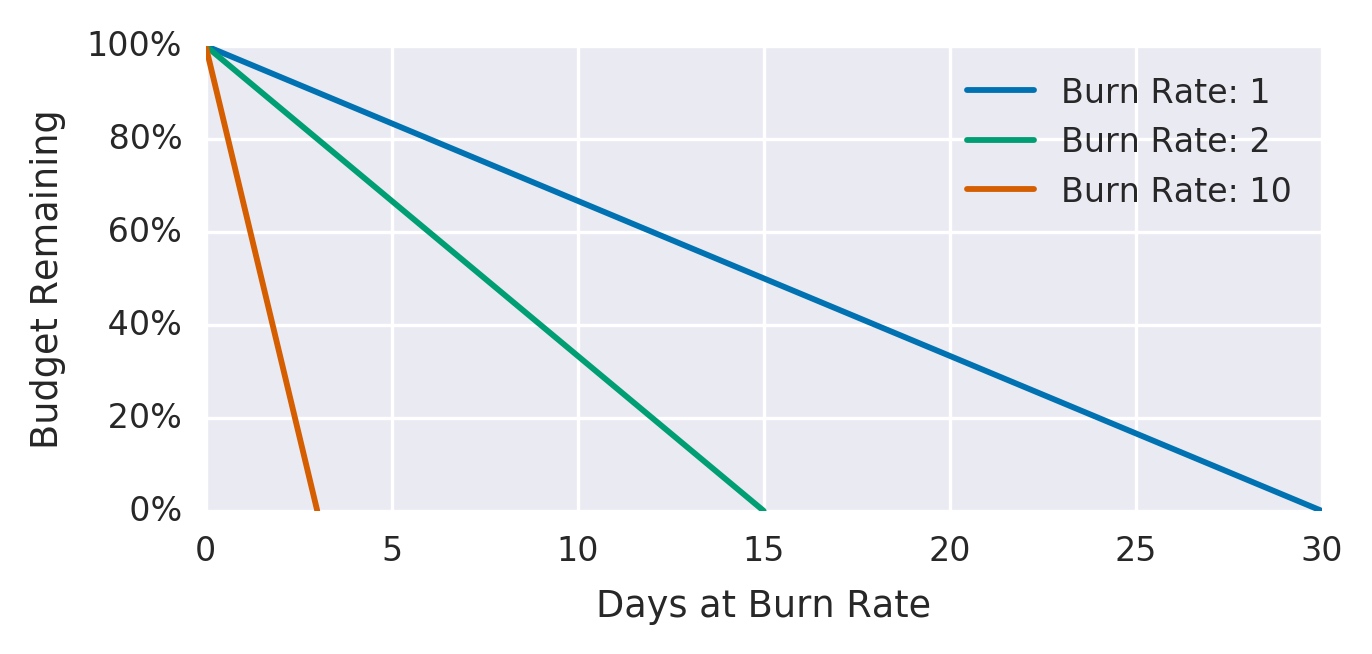
新的告警规则:一小时内花费30天错误预算的5%:job:slo_errors_per_request:ratio_rate1h{job="myjob"} > 36 * 0.001
规则中 36 系数是如何的得出的呢?
1 | // 当 Burning Rate 为 1 时 |
连续 N 分钟的阈值配置 大幅提升一小时内消耗2%的预算 or 六小时内消耗5%的预算:ratio_rate1h{job="myjob"} > (14.4*0.001) or ratio_rate6h{job="myjob"} > (6*0.001)
告警分级:
虽然解决上一个方案 recall 召回率的漏洞的同时,新引入告警分级,但还存在两个问题:
We can enhance the multi-burn-rate alerts in iteration 5 to notify us only when we’re still actively burning through the budget
5min & 60m 的窗口同时破线,才触发预警:“多个消耗速率警报”的升级版,「短窗口」通过 burning rate 保证 precision&recall,「长窗口」进一步保证 recall 的同时,帮助判断故障是否恢复,完美解决 reset time 的问题。
1 | ratio_rate1h{job="myjob"} > (14.4*0.001) |
例如下图仅红色区域触发预警事件: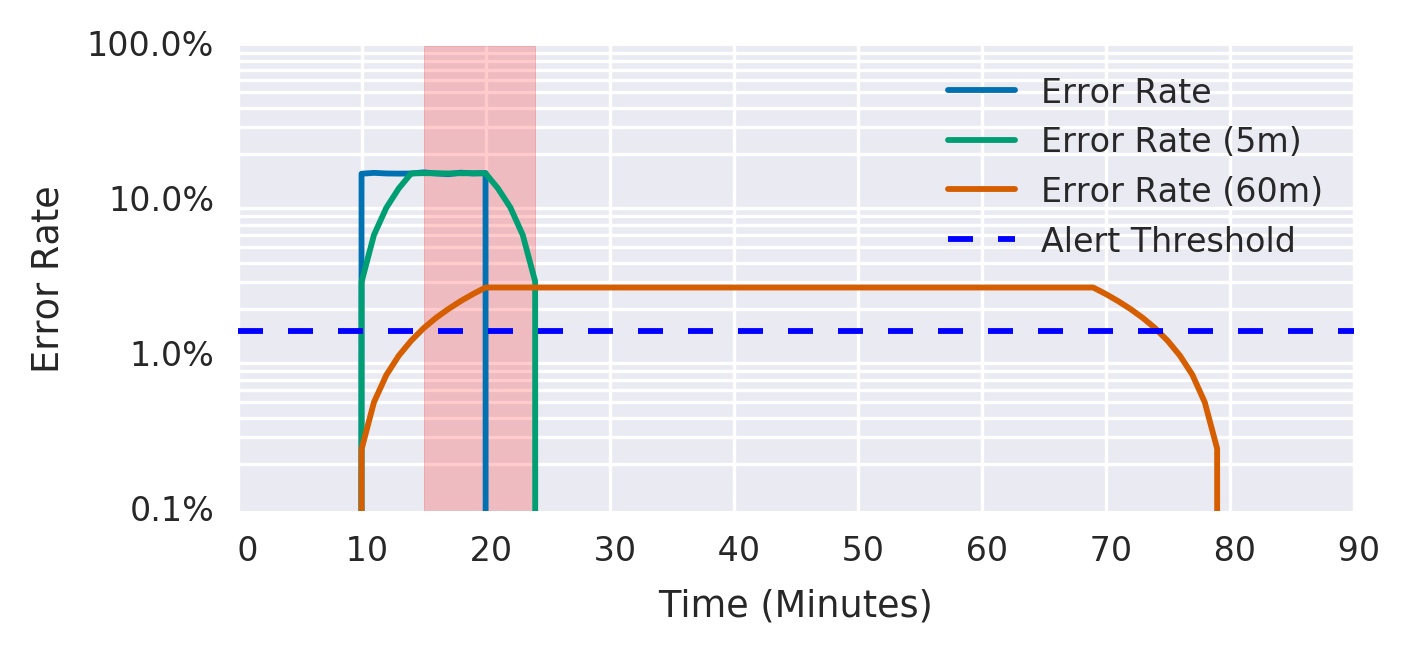
P.S. 困惑与成功率的区别???e.g. 最近五分钟平均成功率<90% && 最近1h平均成功率 < 99%
理论上等同,但 burn rate 优势在于仅用一个阈值:36,而成功率还要重新换算,个人理解。
P.S. 关于小流量的问题,文中提到几种解决思路:
回到现实,由于公司金融业务的特殊性(最高五个九可用率指标,要求一分钟发现,五分钟定位,十分钟恢复),SLO 文化是否无法适用?
但仔细一想,两者并不矛盾,所谓“一分钟发现”完全可使用「多窗口,多消耗率警报」替换:线上环境将「短窗口」从 5min 缩短为 1min;灰度环境通过「长窗口」的错误预算消耗检测,甚至增强问题发现能力。
问题在于:监控系统未按业务重要程度(e.g. SLO目标)科学自动设置预警。甚至针对非核心业务,用户手动配置一笔失败即告警的案例也屡见不鲜。
而 SLO 文化指引的缺失,更根本的原因在于:当前系统无法精确回答用户的一笔请求是否可用(SLO-impacting error),文中并没有做过多解答。希望有一天,针对可用性监控,所有业务系统的下单支付服务,也能像 http 接口一样,通过 5xx 即判断是否影响用户。。

起初听到「单开双控」、「双开单控」等名词的时候,也是一脸懵逼,所以先明确几个概念:
| 名词 | 含义 |
|---|---|
| 墙壁开关 | 墙壁开关=面板+开关+暗盒底座。家用开关暗盒基本都是国家标准86型,所以升级智能开关一般无需更换底座。 |
| 单开 vs 双开 | 顾名思义双开指一个开关面板上有2个开关,同理存在3个开关即三开 |
| 单控 vs 双控 | 双控指两个开关面板可以同步控制一个灯,即在开关A关闭灯1,然后在开关B打开灯1 |
p.s. 单控与双控背后的实现非常巧妙!忍不住再简单补充一下:
例如下图中左边👈为关灯状态,此时博主无论单击开关1还是开关2,灯都会从关闭 -> 开启:

精装交付后所有灯具如下图:
首先简单罗列个人日常需求:
简单分析上面的个人需求后,我们可以发现背后隐含的技术需求:在一个生态中(HomeKit),通过改造传统灯与开关,实现自动控制家内的每个灯。
补充一下:为什么选择 HomeKit?
一方面当然是相信苹果封闭生态把控的良好体验;另一方面因为家人用的苹果手机,并且暂时没有更换智能锁的计划,所以只有 HomeKit 可以实现如下前置条件:当最后一个人离家的时候 -> 触发 xxx 自动化场景。
这时聪明的你可能发现 “改造传统灯与开关” 并没有那么简单,两者会衍生出多种组合:传统灯+智能开关、智能灯+传统开关、智能灯+智能开关。甚至会出现有多对多的情况:智能灯+传统灯 vs 传统+智能开关???
同时也是最容易踩坑的地方,下面将结合实际的场景,详细介绍博主的心路历程~
先从最简单的卧室说起(单开单控),这时摆在我面前的有两个选择:1)仅更换传统开关 or 2)升级传统灯为智能灯🤔。前者成本更低,但缺点为丢失了智能灯的功能性,例如缓慢开启,色温调节,夜灯模式等。后者体验更佳,但墙壁开关沦为了摆设,甚至不小心关闭后,智能灯就完全“离线失联”了。。
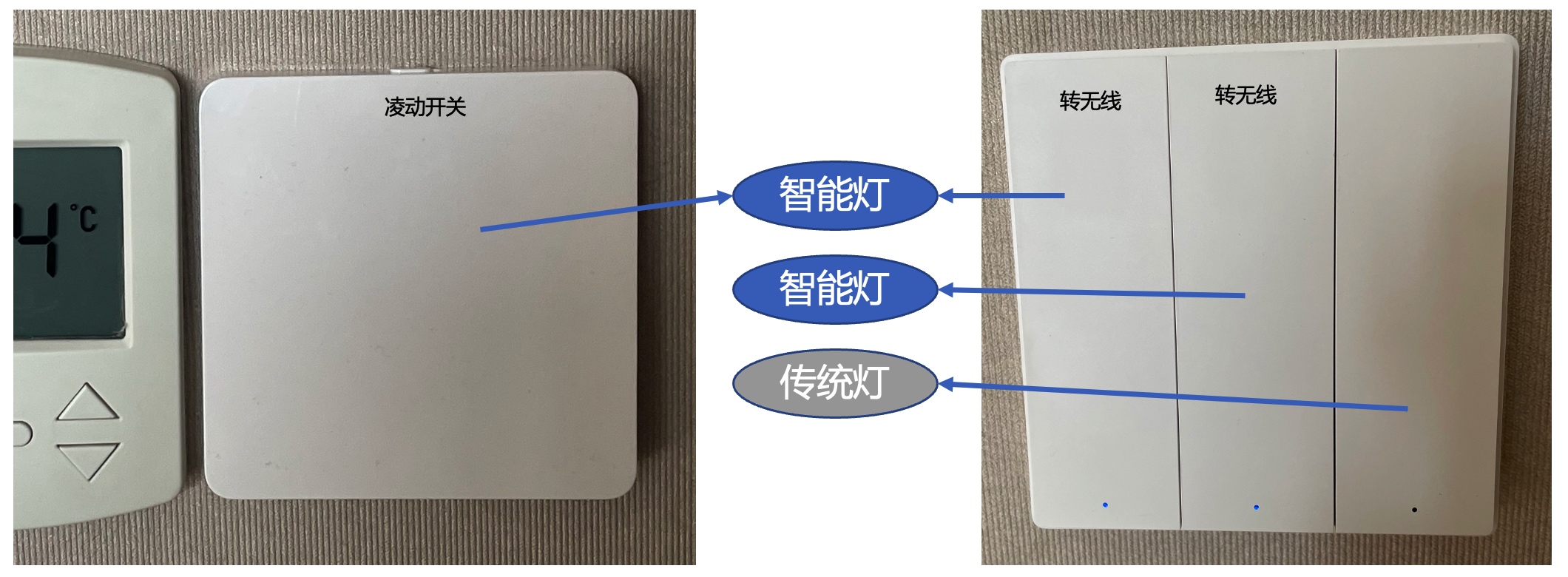
正当纠结时,yeelight 的凌动开关映入我的眼帘,「凌动开关」本质上并非无线智能开关,而是通过触碰时物理的电流脉冲,i.e. 瞬间的断电,从而控制智能灯的状态(默认一直通电,所以原生支持双控)。
最终卧室采购了 yeelight 光璨吸顶灯 + 凌动开关,不仅颜值在线,功能也很齐备(HomeKit认证,凌动支持,夜光模式都不在话下)。使用一个月后,配合床边 aqara 无线按钮(单按开/关,双击切换至夜灯模式,摇一摇切换为日光模式),体验非常丝滑。
唯一不太让我满意的是凌动开关的手感,有点神似青轴键盘,键程长噪音大,个人更加偏爱鼠标点触。
书房由于用的四年前珍藏的一代 yeelight 彩光灯泡,不支持凌动模式(当前 1s 支持凌动),所以选择了新出的米家屏显开关(顺便省去一个温湿度计传感器)。按键手感非常喜欢,但美中不足的是,切换为无线开关控制灯泡后.. 延迟略高,粗略估计接近一秒,着实让人有些不爽..
p.s. 0106 补充:手动升级固件版本后,延迟减少到半秒以内,勉强可以接受。
细心的同学可能注意到,书房明明只有一个开关,为什么选择了双开的开关?
这是因为预留控制其他智能设备的开关,例如窗帘、加湿器等,希望不是过度设计 :)
卧室&书房单控开关改造就到此为止啦,整体变动见下图:
厨房不大但自带了一堆筒灯射灯与一个三开开关,由于这时博主对于智能家居的热情已经从 200% 降低至 50%,所以选择的方案为:仅替换传统开关为 Aqara D1 智能墙壁开关,从而达到手机端控制灯的目的。
个人认为,智能灯终极的体验:让用户忘记开关的存在。所以在厨房中配合使用人体传感器:1)光线暗+有人进入厨房,自动开灯 2)当传感器持续15分钟检测到无人,自动关灯。
真的很香,谁用谁知道😋
上面罗列了两种最常见的改造方式(智能灯+凌动开关 / 传统灯+智能开关),但现实状况往往更加复杂..
比如我们的厕所,上个月师傅在安装浴霸时,无法找到电源,最终只能将浴霸与厕所的筒灯串联。也就是说如果关闭筒灯的开关,浴霸就断电进入离线状态无法再用遥控器控制 0.0
这时显然无法像厨房一样,简单采用“传统灯+智能开关”的解决方案,但 aqara 墙壁开关支持转无线,这样就可以保持物理开关通电保持浴霸在线的同时,按键手动无线控制智能灯。
⚠️⚠️⚠️但是注意!!转成无线开关后,在 HomeKit 里面无法生效!!(点击开关后还是作为有线开关直接断电!!),只能是在米家或者 Aqara home app 中绑定后置动作。也就是说假如灯是米家生态,只能放弃 zigbee 协议!!将开关通过米家蓝牙网关接入!

UPDATE: 2/14/22: 今晚哼着歌,打开浴霸,准备美美洗个热水澡时,突然断电了。。意料之外,情理之中,开关标识只能承载 200w,小米开关终于不堪重负罢工了。短暂出神后,选择将浴霸与小米灯串联火线(通过人体传感+无线开关控制)
终于到了最复杂的双控环节,但还不是最难的... 还记得开头博主的 biantai 需求吗:开门后四个筒灯依次延迟打开(回家的仪式感),所以重金购入四个 yeelight 蓝牙 Mesh 智能筒灯,但很遗憾客厅的灯已经替换为宜家的吸顶灯(非智能带遥控):
面对 智能灯+传统灯+双控开关 的现实,逐步融化..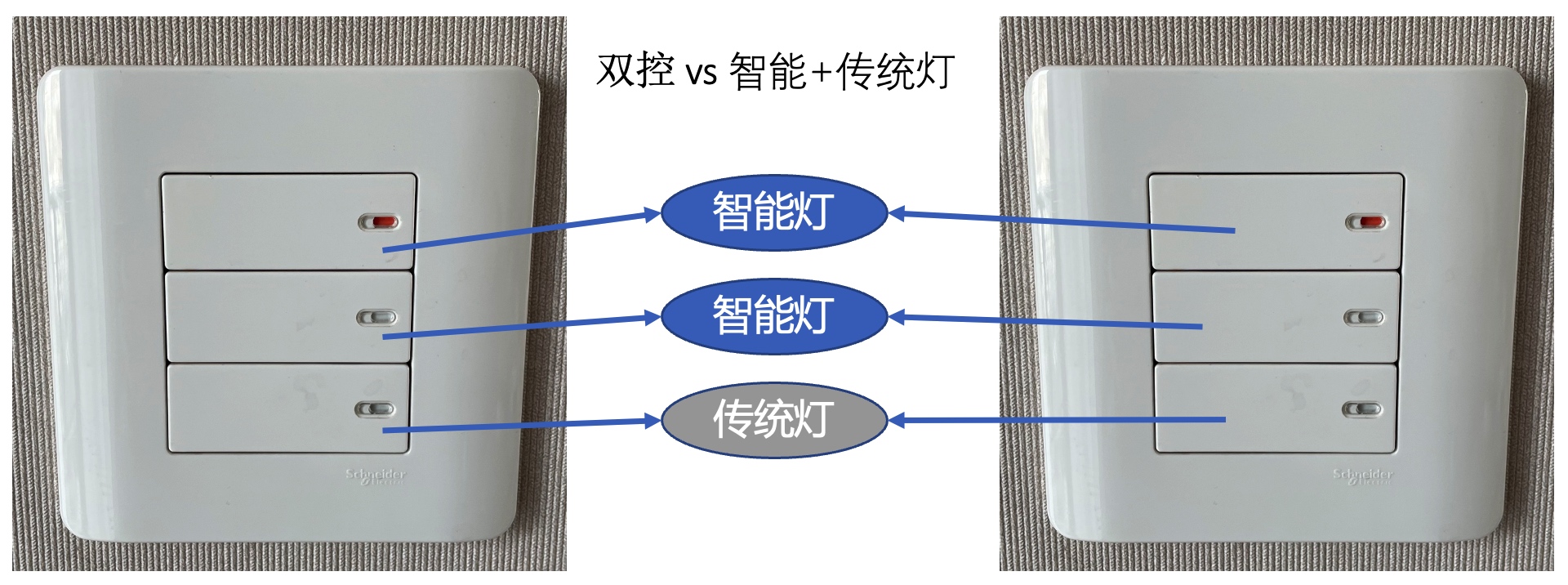
先来罗列双控的常见解决方案:
最终做了一个妥协方案(牺牲部分双控功能):
所以客餐厅改造后整体布局如下:
上面简单介绍了折腾智能灯的心路历程,全屋整体改动如下图:
以下为个人主观视角的最佳组合排名:
最后分享一点个人感悟:
git clone <url> 之后,不管是因为网速还是仓库过大,等你带薪拉屎结束,命令行还是龟速前行。这篇博客简单分享几个提速小技巧⚡️⚡️⚡️
如果在大陆境内,可以暴力为终端配置代理端口:
1 | export all_proxy=socks5://127.0.0.1:13659 |
强烈推荐先阅读博主 18 年的一篇文章:《Git Internal (初探 git 的内部实现)》,了解 git 底层的数据结构: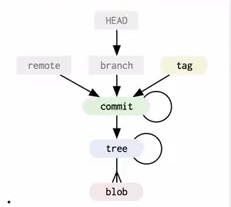
因此绝大部分情况时候没有必要获取仓库完整的历史(所有 commit 对应的无意义文件,i.e. blob)
下面三个参数可以按需使用: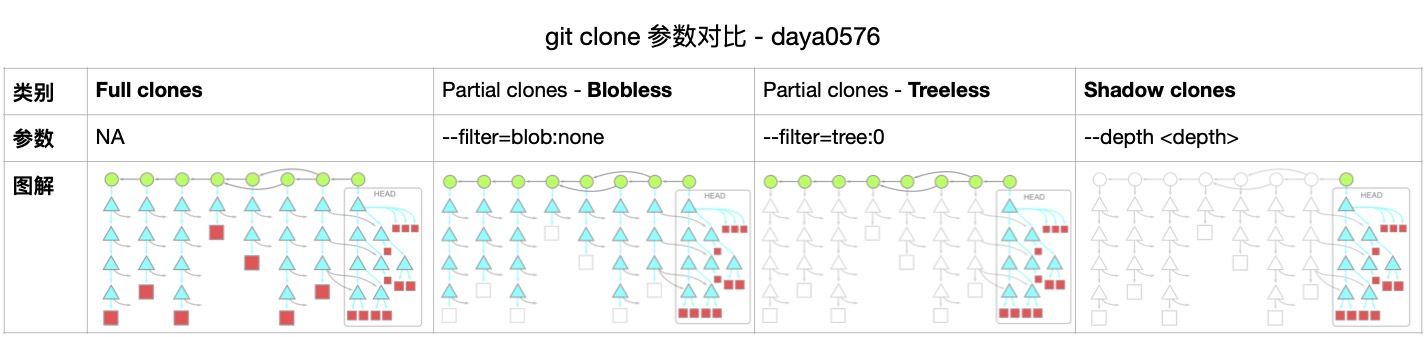
以 git@github.com:JetBrains/jdk8u_hotspot.git 为例,进行性能测试对比(未取平均值,仅供参考)
1 | # 1)Full clones: `gcl <url>` |
日常开发推荐 2)Blobless clones,兼顾性能与信息完整性。
3)Treeless clones 仅适用于例如即用即拋的自动化单元测试,或者本地的编译打包。
⚠️ 不推荐 4)Shallow clones,存在描述信息丢失或错乱的可能,弊大于利。
这篇文章简单记录今早 java BlockingQueue 学习小记~
java.util.concurrent.BlockingQueue
A Queue that additionally supports operations that wait for the queue to become non-empty when retrieving an element, and wait for space to become available in the queue when storing an element.
参考官方注释,BlockingQueue 是 java.util.concurrent 中的一个接口。顾名思义:Queue 表示先进先出的队列,多个线程同时放入对象而其他线程获取对象(解耦输入与输出),Blocking 代表当队列满了或者为空时,尝试放入或获取元素的线程会进入阻塞状态。
有点抽象,举个例子:当队列为空时,获取元素
1 | ArrayBlockingQueue#take |
native 方法可以理解为另一个层面的接口,供非 java 代码实现底层逻辑。
首先根据 sun.misc.Unsafe#park 搜索源代码:
我们发现 Unsafe#park 实际调用当前线程 Parker 对象的 park 方法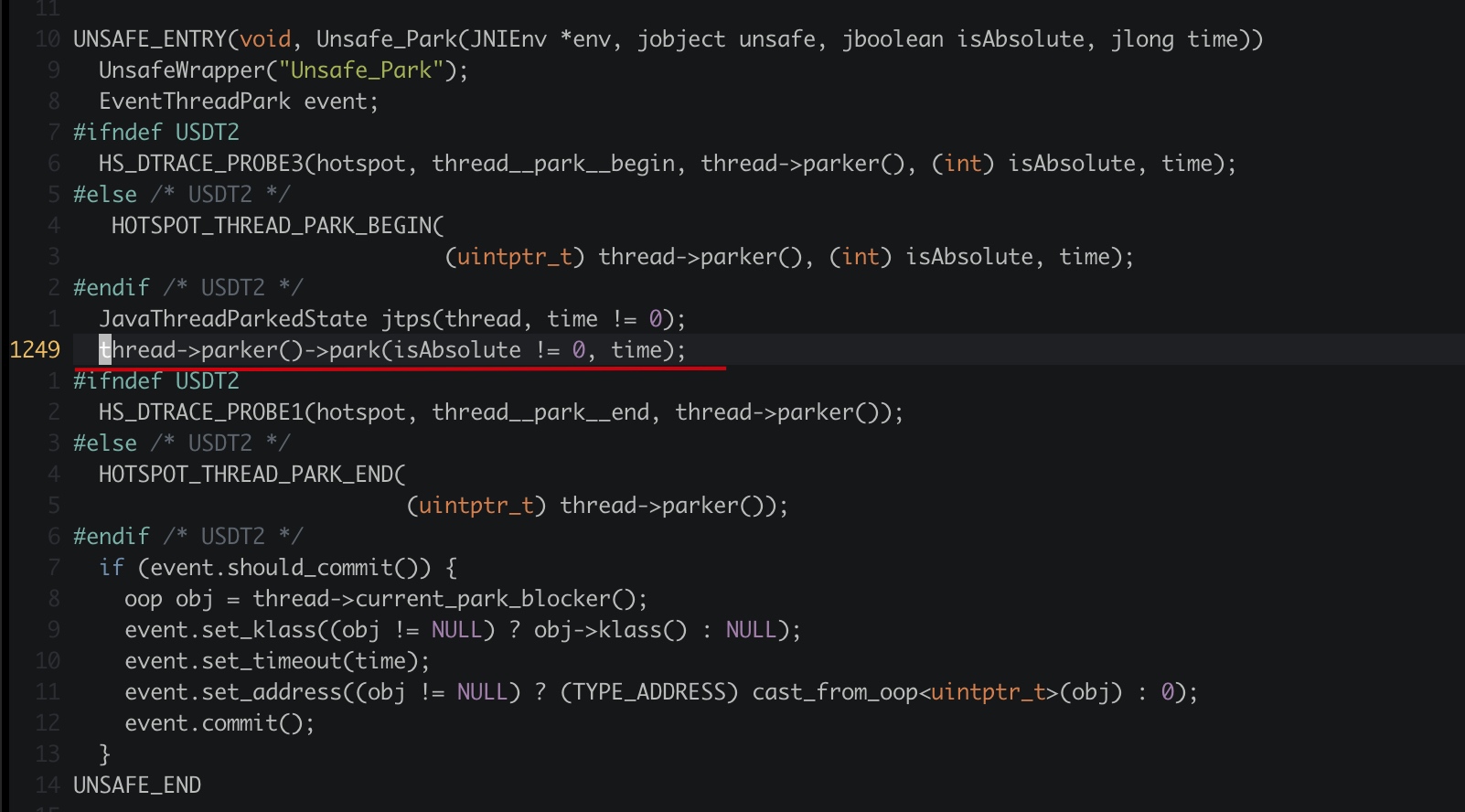
继续寻找 Parker::park 方法..
以 linux 实现为例,当超时时间为 0 时,Parker::park 方法最终调用标准库 pthread_cond_wait(# include <pthread.h>),挂起线程,等待被唤醒。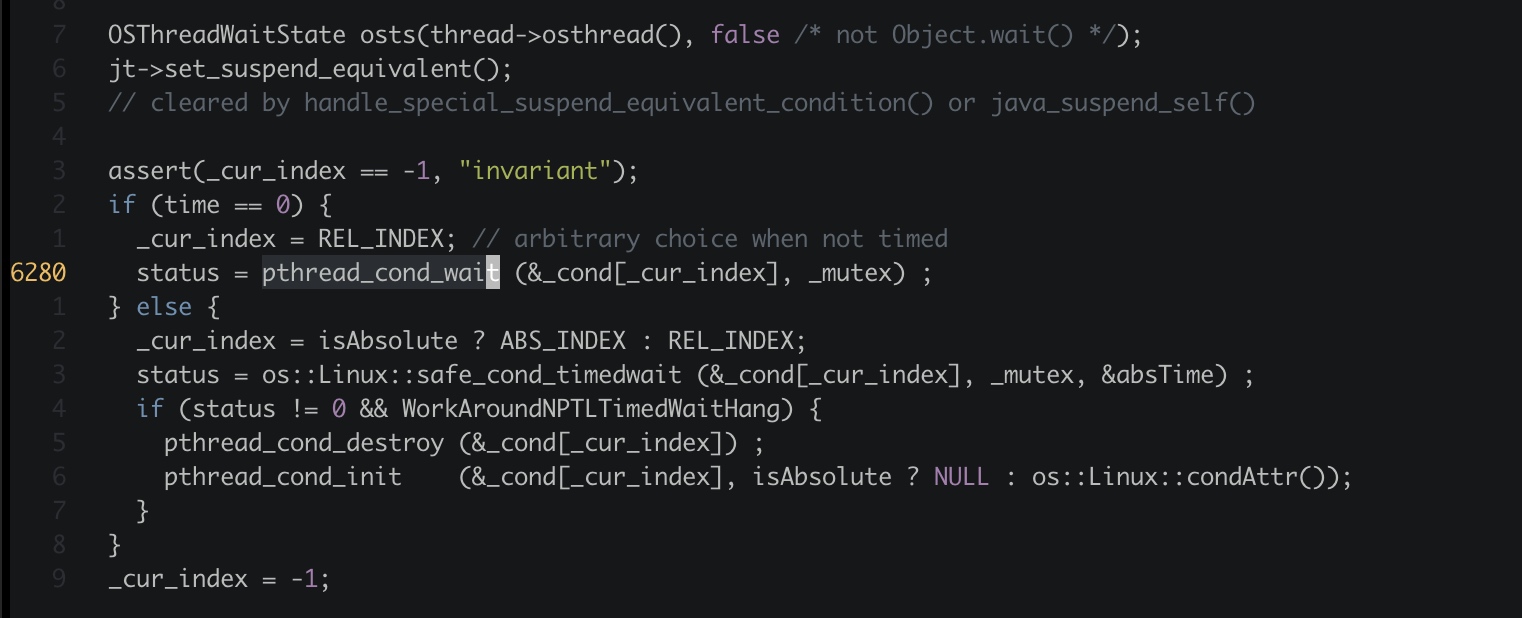
官方文档解释的很清楚,以获取队列第一个元素为例(如果队列为空):
remove(): 立即抛出异常 java.util.NoSuchElementExceptionpoll(): 立即返回 nulltake(): waiting if necessarypull(timeout, unit): waiting + timeout
p.s. Special value 特殊值指的 false/null 等..
-
为了更好理解,参考博主绘制的 uml 图,BlockingQueue 接口在 Queue 的基础之上,扩展了 take&put 两个阻塞方法:
一图胜千言,简单绘制常见几种官方队列数据结构(下面将根据源码一一说明):

顾名思义底层是由链表实现,特性为先入先出,同时没有长度限制
三个部分组成:链表 + 锁 + 迭代器
1 | // 一、链表 |
put 操作触发链表 enqueue:
1 | // java.util.concurrent.LinkedBlockingQueue#put |
1 | // java.util.concurrent.LinkedBlockingQueue#dequeue |
一句话:有界阻塞数组(队列满后,继续放入阻塞),容量不变化。
底层数据结构,仅简单一个数组(参数1控制大小)
1 | public ArrayBlockingQueue(int capacity, boolean fair) { |
新增与获取操作比较类似,以 take 获取元素为例:
1 | // java.util.concurrent.ArrayBlockingQueue#take |
一句话:放入数据队列的行为是阻塞的,只有等消费后才会同步返回结果。
如果有困惑可以运行下面的 demo 代码试试:
1 | import java.text.SimpleDateFormat; |
一句话:延迟执行
1 | import java.util.concurrent.Delayed; |
1 | import java.text.SimpleDateFormat; |
以上 BlockingQueue 针对不同场景的复杂实现,背后都是灵活使用继承与组合后,基于非常简单的数据结构。希望自己有一天也能写出优雅的面向对象代码。
这篇文章将帮助自己回顾 2021 年的目标,同时制定新一年的方向。
首先来回顾年初设置的目标吧~
互联网公司通常早上 10am 点上班,但由于没有打卡的约束,再加上各种原因,个人习惯10点15分之后到工位,甚至偶尔突破30分 0.0
先分享一个小故事:
近日感觉自己漫无目浏览手机的时间过长,所以期望买一个电子书阅读器在地铁上看书,以防止时间被偷走。
但万万没想到花了更多时间在手机上挑选阅读器:调研 Kindle,文石,小米等各个品牌的优劣特点。。经过这件事情我突然明白了一个道理:脱离手机沉迷的关键并不在于阅读器(工具),而是是否能找到一件更让自己愉悦的事情。
出于上面的经历和思考,我发现每日永远无法准时到公司的根本原因,在于自己对工作的强烈抵触。所以年初给自己设立了一个“挑战”:每周工作日五天中,至少有四天提前五分钟到公司。期望通过这种表面的方式,改变自己对工作的态度,甚至“迫不及待”去上班(怎么感觉自己在 pua 自己,形成了闭环)。
通过一年的努力,很高兴完成了这个目标,总结下来主要有两个途径:
期望新的一年在工作之内之外都能挖掘新的乐趣。

上半年尝试用业余时间做了一个小项目:telegram 的天气预报机器人。虽然不是特别复杂的技术,但看到点亮全球地图的用户,还是非常容易获得成就感。技术人的成长就来自于各种造轮子,期望明年持续 hack 用技术为这个世界带来微小而美好的改变~😊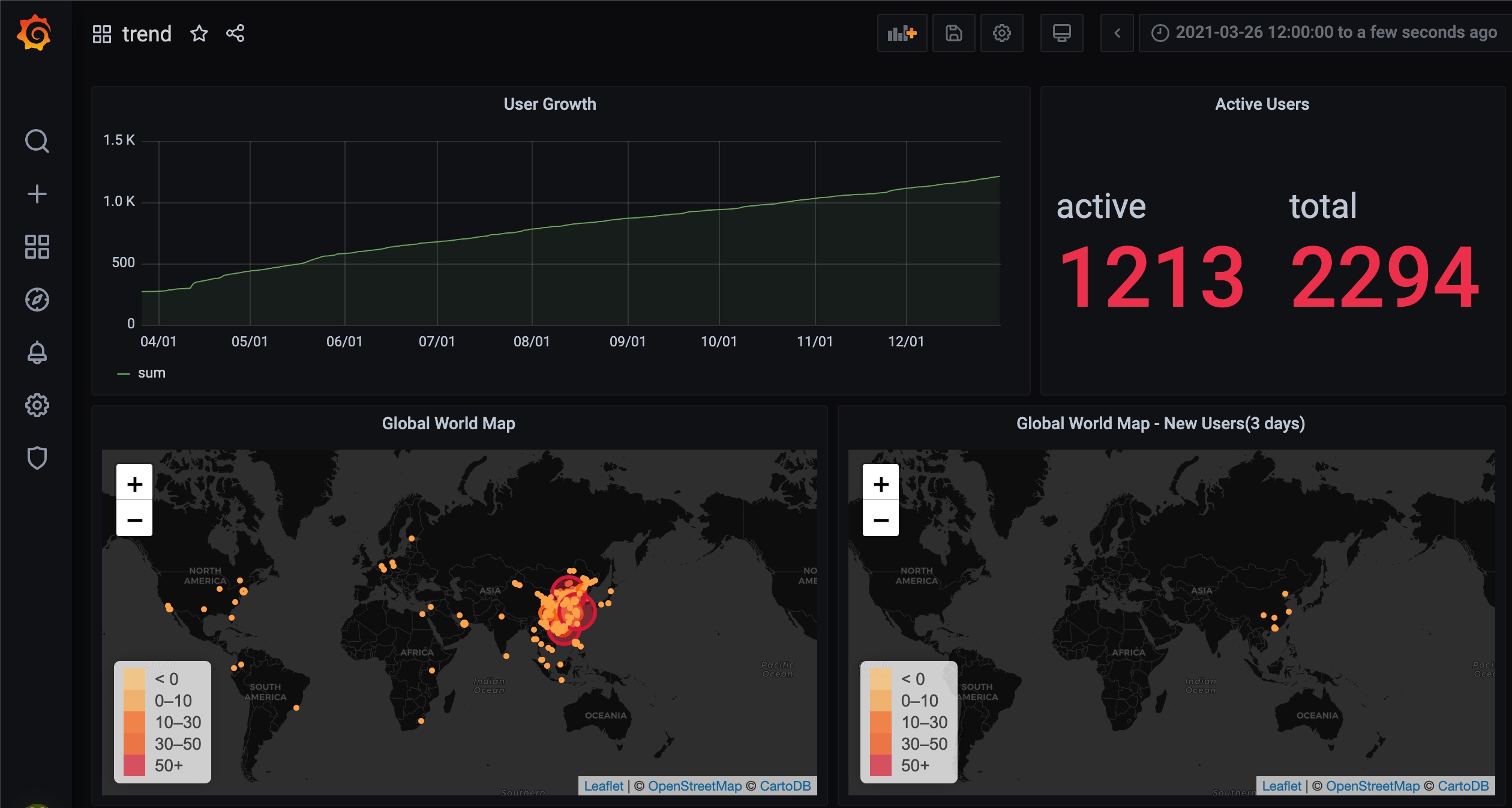
全部得益于地铁的碎片时间,勉强完成了 10 本书籍的阅读任务,但很遗憾更多大把的时间被浪费在刷短视频与购物上:
分享一段影响特别深刻的阅读笔记:
在产品发布前,Facebook通常会在用户库里选取1%~2%的人进行测试,来观察用户的反应。接着它可能会对5%的用户发布新产品,或者挑几个国家进行发布,最终才会面向全世界进行发布。扎克伯格认为,收集关于用户如何使用产品的数据是很重要的。Facebook通常会先发布尚未完成的产品,然后利用反馈实时进行调整。
Instagram团队打算反其道而行之——向所有5亿用户同时发布Stories,至少先发布一个简单版的。他们发布一个简单版的。他们称之为“YOLO发布”,YOLO是“You only live once”(你只能活一次)的首字母缩写。
作为一名 SRE,三板斧(可灰度、可监控、可应急)原则就像烙印一样刻在心中,但 Instagram 团队的“YOLO发布”给了我巨大的震撼,很多时候我们总说技术风险是一切业务的基石,但反过来如果没有业务的发展,技术风险也毫无意义?
由于性格的关系,这一项“又”完全失守了😭,考虑新的一年是否将这一目标移除(从源头解决问题)。
新的一年还是期望从兴趣驱动,通过兴趣例如乒乓球等,与这个世界的人建立交集
这一项格外纠结,首先关于“工作无法创造财富,超过 10% 除工资以外收入”的目标,大大的高估了自己,无论是公司内推、个人投稿等途径都毫无进展,还在互联网寒冬裁员浪潮之中,给自己徒增了一丝焦虑。
但相比于工作以外收入的颗粒无收,受《富爸爸,穷爸爸》的影响,以及逆天的运气,上半年成功购入新房一枚。从认为买房的都是傻X,变为 30 年的房奴 T^T

年底搬家后,每天的生活轨迹也发生了天翻覆地的变化,最明显的一点是每天早上多出了一个小时的个人时间:从过去临近九点起床仓促赶路上班,到现在七点半起床,去门口的麦当劳安静的坐一个多小时,希望最近一周早睡早起的好习惯可以持续延续 🥰

由于工作的关系,好几次起床的时候老婆已经早早出门,深夜下班回家对方太困已入睡,一不小心真的变成了“室友”。Working is just a partial of your life. 还是期望多花一些时间陪伴家人,做更多有意义的事情。
大体与去年保持一致,仅仅针对连续两年失败的目标,更加科学的调整了 KR 的衡量标准:
I decide who I am. I'm going to be what I was born to be
2022 年的关键词是「人生的意义」,有人说人生的意义分为两部分:1)对自己来说,在于每一个选择都出于自己的自由意志;2)而另一部分意义在于是向外的,对他人和对这个世界,一些帮助和善意,留下一丝微小的痕迹。
而我对于人生意义理解为“热爱”,但很多时刻对自己多了一些怀疑和动摇,比如热爱编程,是否仅仅是动手能力比他人强一点点而产生的虚荣感,或者根本不喜欢编程只是喜欢靠编程赚的钱?XD
在 2022 年第一天的凌晨,写下这篇文章,或许不会有太多人看到。但仅仅是因为没有任何目的的「热爱」:喜欢来用文字记录的感觉,沉下心来,静静感受这个世界和时间的流逝(类似写代码中的 zone mode)。
期望在新的一年能找到更多这样纯粹的瞬间 ✨
历年年终总结:
]]>今天面试让一个工作7年的候选人写 str to int,写不出来。
昨天在 tg 上看到这么一段聊天吐槽🤔,虽然字符串转化逻辑看上去简单,但可以快速考察候选人编码风格与实战能力。尝试自己实现的过程中,刚好发现 java 自带原生实现。这篇文章将简单的分享,阅读对应源码的一些感受 :)
需求:输入一个字符串,转换并输出一个整数,e.g. "101" -> 101
java 源码参考:java.lang.Long#parseLong(java.lang.String)

整体逻辑整理如上,虽然并不复杂,但值得注意的是:
方法 parseLong 中包含了非常小心的防御校验,例如入参非空判断、字符阿拉伯数字判断、数值越界判断等等,短短约 50 行代码中竟共出现 10 次异常分支!
为什么需要防御式编程?
因为你永远也无法预测用户的行为,例如这个视频🤣🤣:
话说刚接触 java 时,对 NPE 十分“恐惧”,如果负责编写的代码发生 NullPointException,虽然无人指责,却也感觉奇耻大辱(这也可能是静态类型过于安全的“副作用”:在以前编写 python 代码时,我们总是以 100% 的但愿测试覆盖率为荣,但用 java 编写一些工具代码时,能通过编译的代码一般不会出错,单元测试的投入产出比不高,反而导致了代码质量的下滑)
言归正传,所以如何适度进行防御性编程?
总不能在每个函数,对参数进行校验吧!?这个问题困扰了我很久...
在《代码大全》第八章中,给出了“标准答案”:
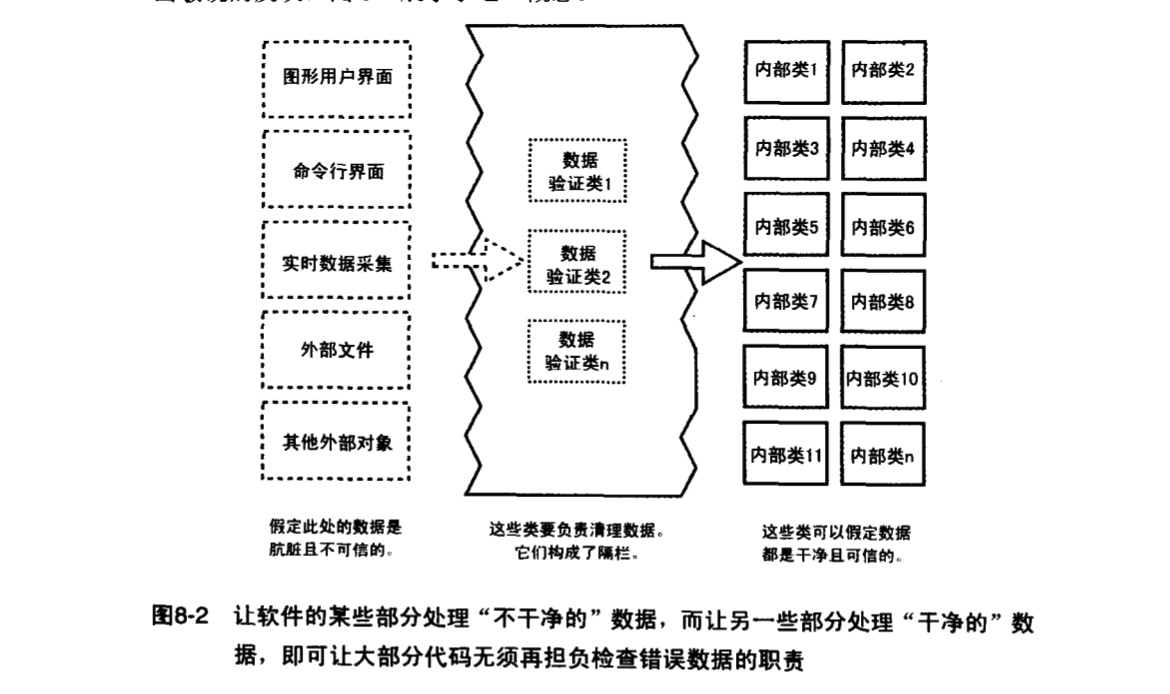
Accumulating negatively avoids surprises near MAX_VALUE
阅读源码中,最让我困惑的一个点:为什么累加数字时,result 是按负数计算的 ???
1 | // java.lang.Long#parseLong(java.lang.String, int) |
为了搞清楚这个问题,我们先来看包装类 Long 中的最大值和最小值:
1 | public final class Long extends Number implements Comparable<Long> { |
不难发现,因为 0 的存在,最大值和最小值不是对称的,abs(最小值) + 1 = 最大值,所以如果用正整数计算,则无法转化 -2^63
记得读书期间,数学考试总是因为粗心导致不理想的分数,后来看到知乎上的一句话才恍然大悟:“粗心,并不是态度问题,而是能力的缺失”。
写代码也是一样,常常因为粗心导致 npe,逻辑不严谨的漏洞等等,但粗心既然是能力的缺失,只要通过努力,就有办法提升。
例如像做数学题一样,永远不要在细枝末节上偷懒(不跳步),反复检查编写用例。
btw,阅读代码的时候,意外😯发现原来 java 中也能一行定义两个变量 0.0
1 | // java |
这篇文章将简单介绍 Java 中异常的分类,使用 checked exceptions 的最佳时机,以及为什么无脑抛 RuntimeException 不是一个好习惯。最后分享如何在 lambda 表达式中,更加优雅的处理 checked exceptions。
Java 中所有异常都继承自Throwable,一般简单将异常分为:
RuntimeException,例如臭名昭著的 NPEError: JVM 抛出异常,例如 OutOfMemoryError 等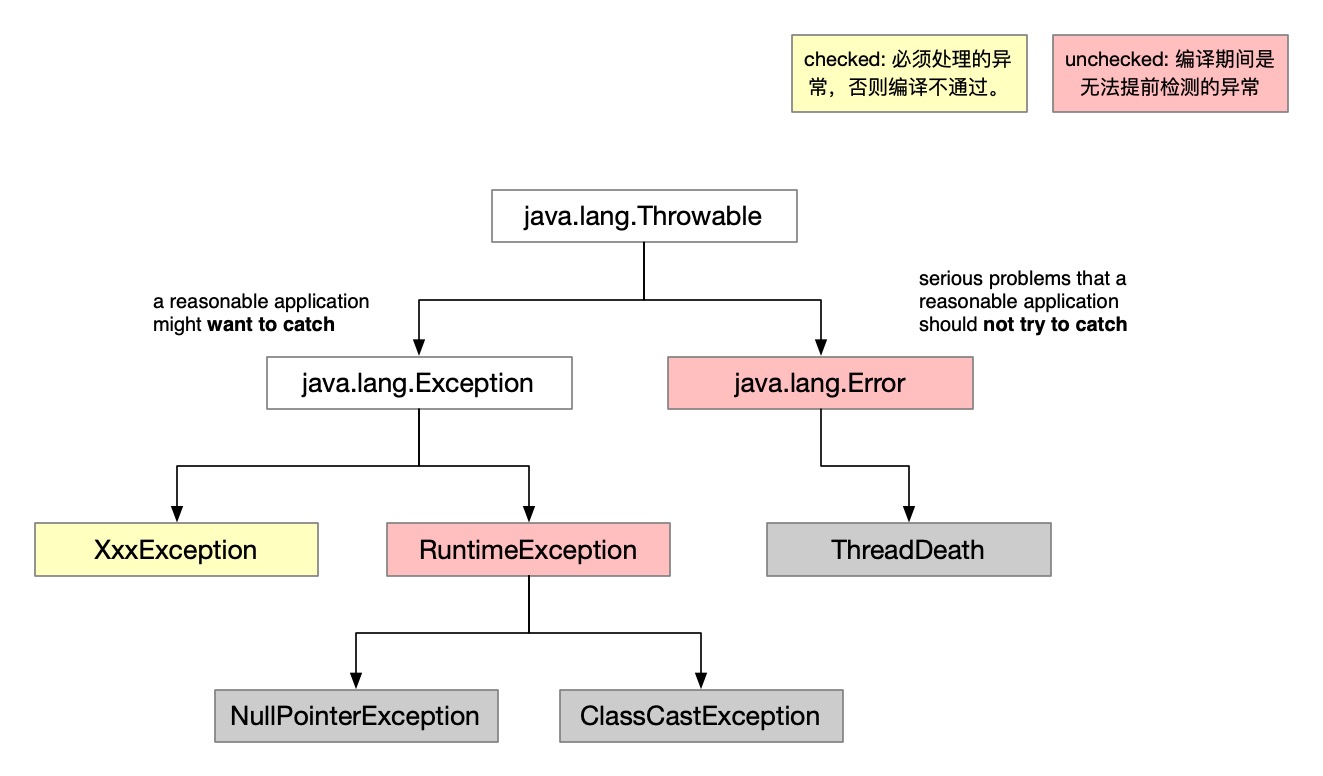
参考《Effective Java》中 Item 70:
Use checked exceptions for recoverable conditions and runtime exceptions for programming errors. By throwing a checked exception, you force the caller to handle the exception in a catch clause or to propagate it outward.
Each checked exception that a method is declared to throw is therefore a potent indication to the API user that the associated condition is a possible outcome of invoking the method.
使用 checked exception 简单的指导原则:异常是否可恢复,简而言之即调用方是否有能力处理异常,并做出积极的响应,最终从异常中恢复。例如尝试打开一个不存在的文件,异常被调用方捕捉后,提示用户重新输入文件路径,也是一种所谓的 recoverable conditions。
否则如果因为编程错误等,无法恢复的情况,则使用 runtime exceptions 尽早让程序结束掉更为合适。
哈哈,偶遇这个提问,如果不是翻译自 StackExchange 真的怀疑是不是我同事的困惑。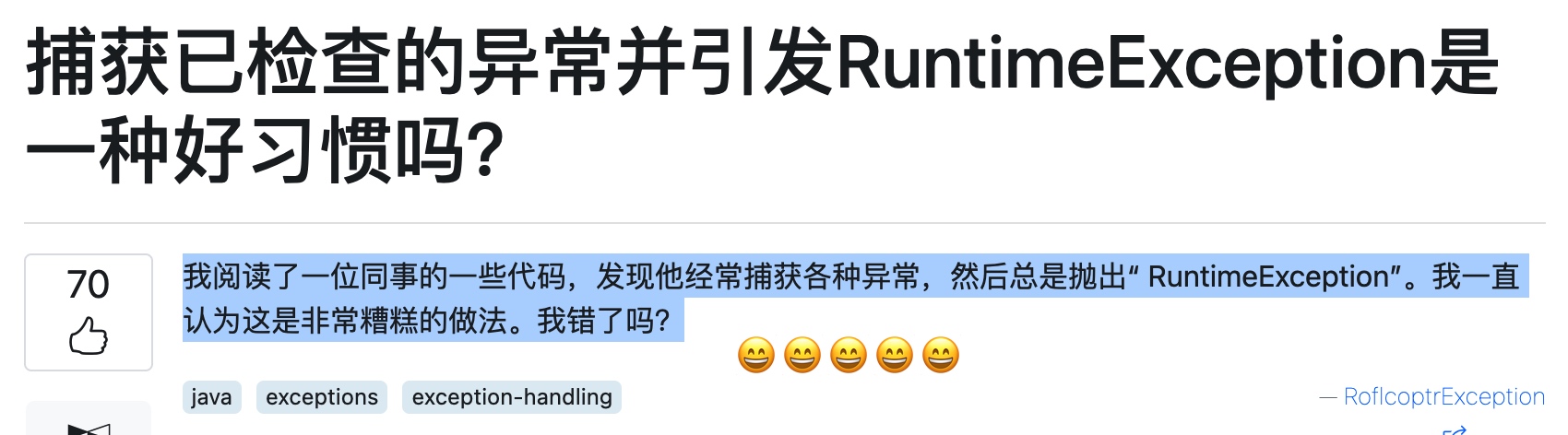
举个栗子:假如有一段线上告警后置处理的逻辑,其中一段子步骤为日志的抽样检查,但是因为网络等原因,存在小概率日志拉取失败的异常。这时套用「指导原则」需要抛出一个 checked exception,最终由调用方决定执行重试,或直接跳过该“弱依赖”,对异常进行恢复。
这时如果直接包装为 RuntimeException 无脑抛上去,则可能会中断整个告警后置处理的逻辑,甚至导致故障告警发不出来,显然是不合适的。
上文说到,针对 checked exceptions,调用方必须显性的捕捉并处理,但这也是为什么很多程序员对它深恶痛绝。
更加可恨的是,在 Java8 的 stream 中,不支持直接抛出 checked exceptions.. 所以很容易写出丑陋的代码:
1 | import java.util.Arrays; |
一种解决办法是使用 vavr 包:
1 | import io.vavr.CheckedFunction1; |
查看资料的过程中,发现大家对 Java 中的 checked exceptions 是天使还是恶魔的争论十分激烈。
但个人觉得 checked exceptions 还是利大于弊的,合理使用会有效提升接口和程序整体的健壮性。
2020 又是买买买的一年。这篇文章分享一下过去一年,永不过时提升生活幸福感的十大好物。
推荐分类:
根据过往的经验,Apple 家的产品每次购入后,唯一的后悔是买的太晚了,所以这次一次性索性 all in!

我对鼠标的唯一要求就是滚轮的左右翻页(无论是游览网站还是查看代码都很便捷)。
双十一的时候,低价入了 MX Master 3,功能上能满足需求,唯一的缺点在于体型过大。。无奈退货入了 MX Anywhere 2S,完美~
年末的时候,不小心中了商场的 300 无门槛券。。入了 NITORI 家的一系列生活用品,无论是质量和体验都毫无挑剔 😊
分享一个很小的细节:晾衣架的组件组装说明中,关于「6」和「9」两个序号,贴心的通过下划线进行了区分~
相见恨晚,一图胜千言:

床边以及办公桌下,购入宜家地毯两张。型号分别为:
优点:性价比高,租房神器。每次光脚踩在地毯上吹头发,忽然间有一种家的温馨感~
缺点:使用将近一年后,背面防滑垫不再防滑了 :(
购入二手 PS4 一只(49 年入国军)。游戏因人而异,比如我最喜欢的游戏:无主之地3..

优点:
缺点:
二手人体工程椅市场,1K 出头的价格入手(官方介绍)
【优点】这把椅子个人最喜欢的一个功能:支持 5-10 度的前倾,可以让你非常自然的保持挺腰。
但说实话坐久了还是会酸,升降桌已在我 2021 的 wishlist 之中~~
洗手池最近下水有点缓慢的趋势,怀疑一定的堵塞。使用这款“清道夫”后,原以为是智商税,结果出乎意料效果立竿见影!
设计十分巧妙:通过生成大量泡沫,在垂直的管道处长期停留,轻松溶解排水管👍👍👍
😂 很个性的一双鞋子。整体体验还是蛮不错的(不管是抓地力和舒适度),适合室内运动~

一千多山姆入手的(可惜目前已经下架),给生活带来了极大的便利。
一共有九种烹饪模式!除了支持一键“蒸”和“烤”,还可以烤吐司,简直就是厨房神器。

最后列举几个无力吐槽的踩坑产品。。
吐槽一下智能垃圾桶有两个“智能”的地方,真的是智商税:

写完才发现,整篇文章充斥着 “二手”、“性价比”、“白嫖”等词 🤣🤣🤣
可能是现实生活中,充满消费的陷阱,受过无数次的毒打。如果你也有强力推荐的好物,也可以直接留言~~
]]>这篇博客将记录个人学习 Java 的一些经历与思考,希望同在迷茫的你读到,可以有所收获 :)
简单分享一下个人 一波三折的编程经历:
但很可惜当前公司的技术栈中, Java 才是一等公民。在一次又一次“拥抱变化”之后,开始使用 Java 作为工作的主力语言。

在《Google SRE》的第 28 章中,谈论了如何让一个 SRE 新手(newbie)快速开始进入 on-call 的队伍:有人建议说教游泳的最好办法是直接把那个孩子扔到水里,但文中并不太赞同这个观点,成为一名合格的 sre 需要体系化的学习和实践。
学习一门编程语言也是一个道理,除了大胆的上手实践,系统化的学习更为关键。下面将按时间顺序,分享个人 Java 的入门路径,以及受益匪浅的学习资料。
基于以往的编程经历中,不难发现一门编程语言质量最高的入门教程,往往出自官网(因为是对这门语言最了解的人撰写的?)
这里推荐《The Java™ Tutorials》👍👍👍:
假如你和我一样在学生期间接触过 java(jdk1.6 与 eclipse 的时代),重拾后发现现在的 java8 和以前竟然不是一个东西???总是被 Stream API、Lambda、方法引用等新特性,绕的云里来雾里去。
那么恭喜你!有一本秘籍叫做《Java 8 实战》,帮忙你快速掌握 Java 8 的新特性。
有些瞬间觉得 Java 的 “表达能力” 远不如 Python(有力使不上的感觉)
例如下面的例子,简单将一个嵌套的二维数组打平的需求。
Python 实现的版本不管是在直观的“代码篇幅”,还是“可读性”上都明显占优:
1 | # Python |
但是。。Java 的“笨重”反而又是它最大的优势:在多人(很多人)协作开发的场景,通过各种条条框框,可以更好的保证代码质量的下限 👀
而《阿里编程规范》即“条条框框”的集大成者。。但说实话没有必要花太多时间细读,因为其中 90% 以上的规范或者最佳实践,已经沉淀在 IDEA 的插件中(链接🔗),强烈建议安装获取实时提醒。
收回上面不需要细读的话,放假前摸鱼认真阅读时,还是有很多收获。建议仔细阅读,成为一个莫得感情的代码生成机器。
例如 集合处理 章节中,阐述了编译阶段不会发现的报错:
subList 后得到的其实是 java.util.ArrayList.SubList。⚠️注意这时对父集合元素的增加或删除,会导致报错!!list.toArray(new String[0]);,动态创建与size相同的数组,性能最好。Arrays.asList() 后,同时⚠️注意不能对处理后的集合,进行增删改查的操作。虽然插件会给出实时的 WARNING 提示,但很可惜,目前还无法提示更加「优雅」的代码。
阅读《Effective Java》书后,唯一的一个感觉就是相见恨晚,因为其中每个章节都似曾相识(对应同事曾经给我的 CR 建议 😂)
举其中一个章节为例:Item 53: Use varargs judiciously(明智地使用可变参数)
1 | // 需求:子程序接收可变参数,但长度必须大于 1 |
尝试过阅读英文原版,但太啰嗦了。。推荐《中英文翻译》,高效的学习和记录要点。
掌握基本语法后,还是很容易写出 面条代码 (Spaghetti Code)
这时你需要尝试开始用「面向对象」来思考和组织你的代码,最终管理好整个项目代码的复杂度(谨防为了OO而OO)。
Item 19: Design and document for inheritance or else prohibit it
《Effective Java》中有个很有意思的一个建议:如果要使用接口和抽象类,请先写好设计文档。我理解即画好 UML 类图和时序图。
参考之前的一篇博客感受一下:《解决关于 UML 类图在心中深藏多年的若干疑惑》
软件最重要的一个使命:管理复杂度。而 Java 遇到设计模式就像咖啡遇到牛奶,变成一杯香醇的拿铁~ 深有体会在真实项目中,如果合理的使用构造器、观察者等实用模式,将会有效提升代码的复用性,降低耦合度。
尝试阅读过 《First Head 设计模式》,《Refactoring Guru》,《设计模式:可复用面向对象软件的基础》后,个人的一点点感悟:掌握一个设计模式很简单,但如何在真实的场景中,恰到好处的使用才是关键和难点。 所以建议不要纸上谈兵,抓住每一次写代码的机会,不断的实践练习和提高对代码的要求。
参考:*《Head First 设计模式》学习笔记、《Python 不需要设计模式?》*
虽然 java 天天被黑,但 JVM 还是很优秀的。更难得有一本深入浅出的书供大众学习,不像难产多年的《Python源码剖析》每年圣诞节的梗 😊
虽然书中绝大部份知识,看似在日常中派不上用场(确实例如 class 文件格式每个字段的内容),但很多知识会产生潜移默化提升个人能力,例如:
参考近日的一篇博客:《Java 内存管理 - SRE 的必修课》
侥幸入门后还有很长很长很长的路要走,以下为待读的书单:
上周地铁上看了一本书,名叫《为什么你总是半途而废》。虽然有一丝丝鸡汤... 但借着其中关于如何坚持到底的几个观点分享一下:
听我讲座的人中有一个舞蹈老师,他曾跟我说:“能够学好舞蹈的人往往都是那些本身就喜欢舞蹈的人,喜欢练习跳舞的人。”相反,学不好的人往往想的是学会舞蹈以后既能扩大自己的交际圈,又能锻炼身体、丰富人生等,他们更多想的是学会舞蹈之后的好处。比起练习的过程,他们更希望感受结果的喜悦,显然很难坚持下去。减肥也是同样的道理,只重视结果的人即便能瘦下来,最终还是会反弹
享受过程:下半年给自己的一个目标:尝试用 Java 技术栈做一个小项目(code for fun),利用解决现实中的问题,帮助他人的成就感,不断自我驱动。
容易半途而废的人总是想独自完成事情,而坚持到底的人却善于借助外力
所以如果你也在学习 Java,可以直接留言联系我,相互监督打卡,持之以恒提一起升编码能力 :)
先从整件事的1%着手
入门一门语言,警惕花一周时间甚至更久,整理出一个完美细致的学习计划。因为通常只是三分钟热度(个人观点)。
还不如把这份热情用于简单找一本经典书籍或教程直接开学,如果能沉下心来啃完,基本上已经超过绝大部分人了。
一直有一个困惑:Java 这门语言是否适合我?(甚至自己是否适合做技术?)
给自己的答复是:因为目前还没有及格的掌握这门语言,所以有这个困惑。希望有一天可以对这门语言运用自如,并找到相关的热情点~
TODO:招聘帖
]]>Metaspace out of memory 报错,影响了部分 XX 商户的代扣业务,最终落了一个 P4 故障 T…T但是之后很长一段时间内,都不太明白 Metaspace 是什么,为什么会耗尽?和 perm 区的关系是?不同线程本地变量和全局对象的关系?
正好趁这次机会,系统性的整理和分享一下 :)
首先预热一下,简单解释几个常见名词:JVM -> JRE -> JDK
JVM(Java Virtual Machine):Java虚拟机,它实现了一次编译到处运行,例如 HotSpot 等JRE(Java Runtime Environment),JRE是支持Java程序运行的标准环境。包含 Java SE API 子集 / 虚拟机JDK(Java Development Kit):Java程序开发的最小环境。包含 程序语言 / 虚拟机 / 基础类库等,例如 OpenJDK 等书中有一段总结挺有意思的,分享一下:“Oracle收购Sun是Java发展历史上一道明显的分界线。在Sun掌舵的前十几年里,Java获得巨大成功,同时也渐渐显露出来语言演进的缓慢与社区决策的老朽;而在Oracle主导Java后,引起竞争的同时也带来新的活力,Java发展的速度要显著高于Sun时代。Java的未来是继续向前、再攀高峰,还是由盛转衰、锋芒挫缩,你我拭目以待”
进入正文!🎉🎉🎉
网上很多文章因为 java 版本的问题,存在不同程度的过时。
所以花了一点时间,尝试通过「栈」和「堆」两个视角,将 java8 的内存分布重新绘制一遍加深理解: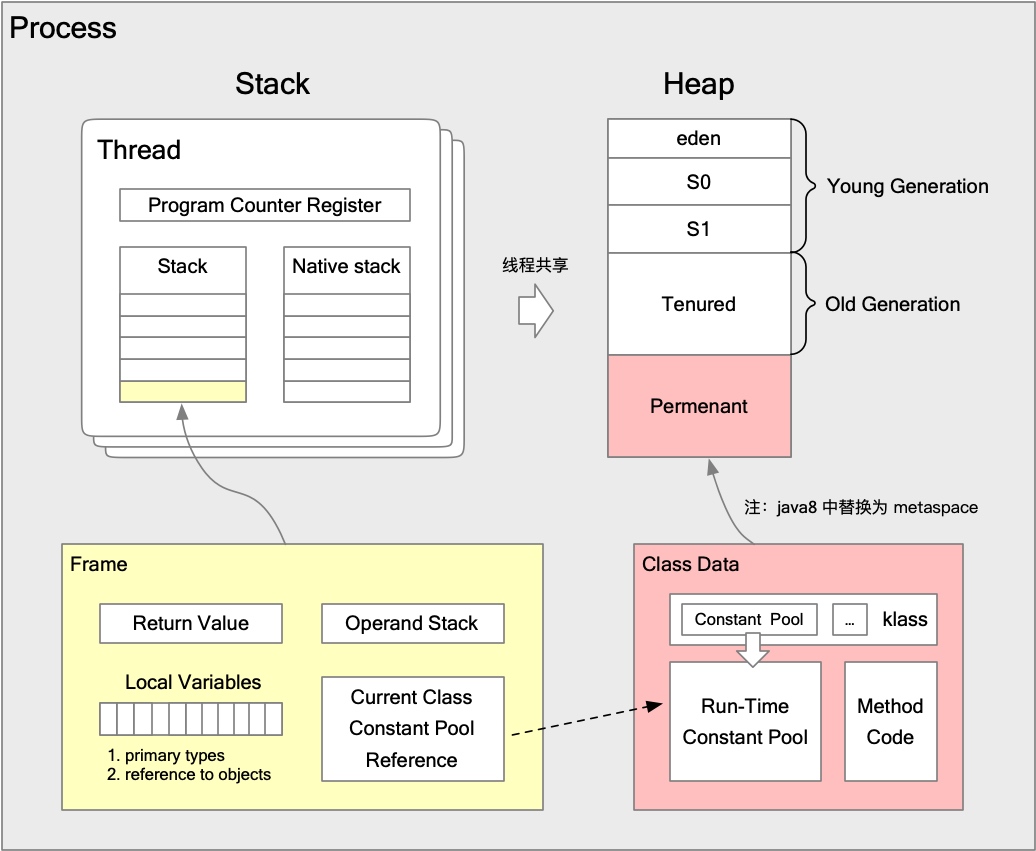
(p.s. 如果有不对的地方辛苦帮忙指正)
为了解决 持久代内存溢出 & 不同虚拟机融合等目的,持久代(PermGen)在 1.8 以后被 Metaspace 取代。
我个人理解最大不同在于:1.8 之前,持久代与 Heap & Stack 都归属虚拟机内存,而 Metaspace 侧使用的本地内存(native memory),默认不做限制。
既然没有限制,文章开头故障为什么还会发生呢??
因为通常还是习惯设置 -XX:MaxMetaspaceSize 参数。。所以如果代码编写不当,类占据的空间还是很可能超过指定的空间大小,造成java.lang.OutOfMemoryError: Metaspace 异常 :(
程序运行本质上是方法的套娃调用,也就是不断入栈与出栈的过程。
而每个栈帧(Stack Frame)中,本地变量(Local Variables)与 Heap 的关系如下: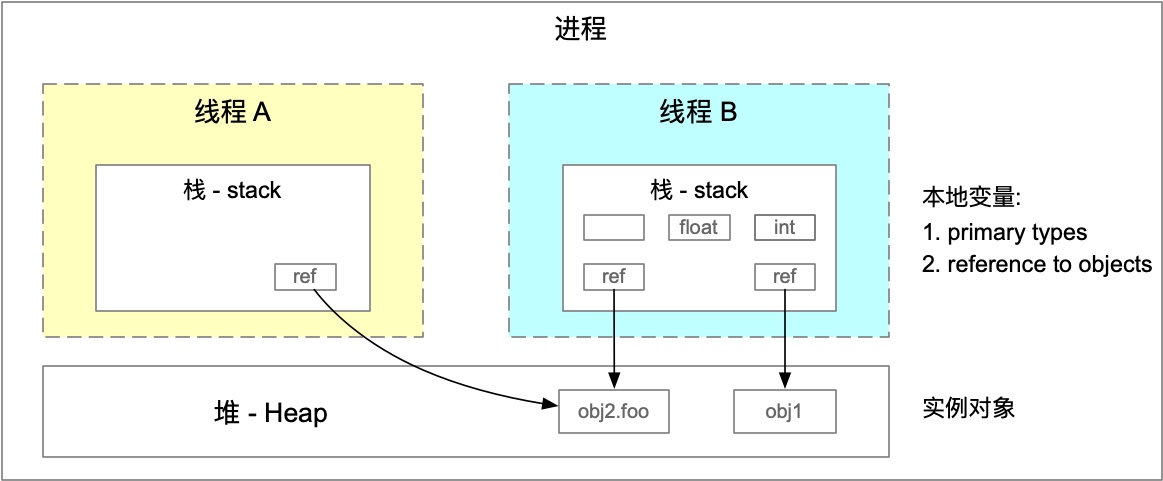
参考下面的例子,通过 javac + javap查看编译后的 .class 文件:
1 | public class Scratch { |
可以看到 class 文件包含一段 Constant pool 区域,用于存放编译期生成的各种字面量( Literal )和 符号引用(Symbolic References)。不难理解,在编译阶段,并不知道所引用类/方法的地址(实际地址),所以将符号引用保存至变量池(Constant pool)
#1,#2 等等代表符号引用(symbolic references)9: invokevirtual #36 // Method methodA:()V先来回顾 jvm 加载一个类时,会经历 加载 -> 连接(验证|准备|解析) -> 初始化 三个阶段。
首先在第一步 加载阶段:虚拟机加载 Class 文件后,会在内存方法区中生成这个类的 java.lang.Class 对象,供外部访问。同时将上文常量池中的符号引用(字段/方法/类的引用)转移至 Run-Time Constant Pool 中。
然后将对应的「符号引用」转化为「直接引用」(实际运行时内存布局中的入口地址),这个过程叫做“方法调用”,而它又分为以下两种:
运行时常量池(Run-Time Constant Pool)保存的是 class 文件常量池构建的符号引用,同时包含翻译后真实内存地址的直接引用。
p.s. 我们常说的 动态连接(Dynamic Linking):指的是在开头内存分布大图中,栈帧 (Stack Frame) 存在一个指向 Run-Time Constant Pool 的连接
Eden -> S0 Eden -> S1,S0->S1(交互触发年龄+1)Eden -> S0,S1->S0(同上年龄+1)S0&S1 -> (老年代)关于垃圾回收相关的知识网上遍布都是,就简单 copy 了一下自己的读书笔记,暂时不展开班门弄斧了。
java 小白历险记,文中如有错误请多包涵,欢迎指正交流。
这篇文章简单回顾一下 2020 年初设置的目标,以及对 2021 年的展望。
历年年终总结
2020 年期望的关键词是 「酷」,但被现实一次次的打回原形 😅
如上 mission failed😭 虽然今年一直在不断思考,但还是没有找到工作的意义,或者说在这个世界中比较理想的活法。在这种处境下,公司或整个社会希望你成为的人 VS 你想要成为的人很容易产生矛盾,然后造成不同程度的「痛苦」。而人在痛苦的处境里,第一选择就是逃避,期望改变环境后「痛苦」就会像魔法一样被解除。但是谨慎如果你没有想清楚自己想要成为的人,以及工作对于自己的意义,大概率会在新的环境重新陷入无尽的「痛苦」黑洞。
既然还在一份工作中,还是尽力做到 professional:将每一件小事做好,抓住一切提升自己的机会,毕竟现实很残酷,只有变得更优秀才会有更多的选择。但努力的同时要谨记:1)long-term value 2)选择比努力更重要。
身为一名 SRE,分享他人对自己更加接地气的三个建议供参考:
去年一年共读了以下几本书,从数字上看也算是超标完成了目标,但很奇怪豆瓣上记录完成的时间集中在某几个月。更希望明年读书的习惯是兴趣驱动的,而不仅仅是为了完成目标。
推荐非技术相关的一本书《我们为什么会分手?》,采访了15对昔日恋人,多年后在双方的角度说出当时的分手理由。当两个人在一堆关系中发生争执和矛盾的时候,我们总是期望对方不断成长变得理性和“成熟”,但家是讲爱的地方,不是讲理的地方,更多的时候需要的是包容和沟通,以及“自省”。
去年有个周末误入阿里云自动化运维的一个线下沙龙,作为一名 sre 却第一次听说了 terraform & Infrastructure as Code (IaC)等概念,给自己带来了很多冲击。
身为一名程序员,代码写多了很容易“自闭”,但闭门造车是大忌。记得读大学的时候有一位助教,教过我们 .Net 等课程,他当时很喜欢钻研技术,但总是一副付出了很多,却郁郁寡欢不得志的样子。在去年的工作中,我也渐渐明白了一个道理,为什么大学的时候,我们要学习软件工程,项目管理等看上去和编程无关的课程:一是程序员的软技能(团队协作,沟通能力等),可能和硬技能一样重要;二是一个大型的项目更多的需要由一群人或一个团队,朝着一个目标一起完成的。
所以新的一年,可以找机会多去参加一些线上线下 meetup,提升自己的软技能与视野,期望也可以找到一些新的乐趣~
一如既往的弱项,但读完《富爸爸,穷爸爸》后,至少对「资产」这个词有了更深的理解,明白富人是靠钱生钱变得富裕。而像我一样不断工作,靠出卖自己的时间获取回报,是一辈子也无法积攒财富的。
饮食&体重的控制,是 2020 年唯一一项比较拿的出手的成绩了。。希望未来我的财富可以和下图的曲线成相反趋势上升 😂
每天早上都会花时间做早餐~
在公司里每个人都需要在财年初录入每个人的 KPI,隔一段时间进行对焦。有的人很反感这种形式,但我倒是挺喜欢有目标感的工作和生活:
seize the time,珍惜在这个世界的每分每秒~
]]>本篇文章为该机器人实现的不完全教程~
源码: https://github.com/daya0576/he-weather-bot
👉戳链接调戏我:https://t.me/he_weather_bot

Python3.9fastapiaiogramherokuHeroku PostgresHeroku RedisHeroku Schedulersentry尝鲜使用了 python3.9,以及异步的 fastapi web 框架,所以 telegram 的 sdk 也需要使用异步:aiogram。
线上部署白嫖了 Heroku 全家桶:推送 master 即可触发部署(gitops)。同时支持数据库/缓存/定时任务的一键申请(最重要的都是免费的),以及 环境变量配置,域名https卸载,日志在线查看,等傻瓜操作... 唯一的缺点:Heroku 只在在美国与欧洲提供服务,访问国内 api 会存在一定延迟。
分为以下四个步骤:
第一步先找到 @BotFather,创建你的机器人,并获取对应 token 唯一标识。
telegram python SDK 中提供两种消费机器人动态的方式:
所以不管是 fastapi/flask/django,都需要开启一个 /hook 的接口,参考项目中的这档逻辑: telegram_bot.routers.webhook.webhook_handler
p.s. 本地调试推荐 ngrok 这个小工具,一键针对内网 IP 创建一个对外可访问的 https 地址。
用户与机器人的每次交互,甚至在群组中的每次对话及交互,都会以 http 请求的形式,分发至机器人对应的 webhook,所以需要提前将 webhook 与 token 进行绑定。两种方式:
https://api.telegram.org/bot{token}/setWebhook?url={webhook}aiogram.bot.bot.Bot.set_webhook。一个小技巧:在 fastapi app 每次启动的时候,检查如果与当前机器人绑定的 webhook 不同,则进行更新。需要注意调用的频率,参考 telegram_bot.routers.webhook.set_webhookheroku 一键部署:参考《Getting Started on Heroku with Python》
p.s. heroku 原生不支持 poetry,只认识 requrements.txt,可以通过第三方 buildpack 解决:https://github.com/moneymeets/python-poetry-buildpack
利用 proxy 解决本地连接服务端报错的问题:
1 | # ClientConnectorError: Cannot connect to host api.telegram.org:443 ssl:default [Connection reset by peer] |
用户与 telegram 机器人的交互,大致可以分为三个场景:
telegram_bot.telegram.finite_state_machine.update_location/weather 命令,请求外部 API,返回实时天气三个场景对应的时序交互如下:
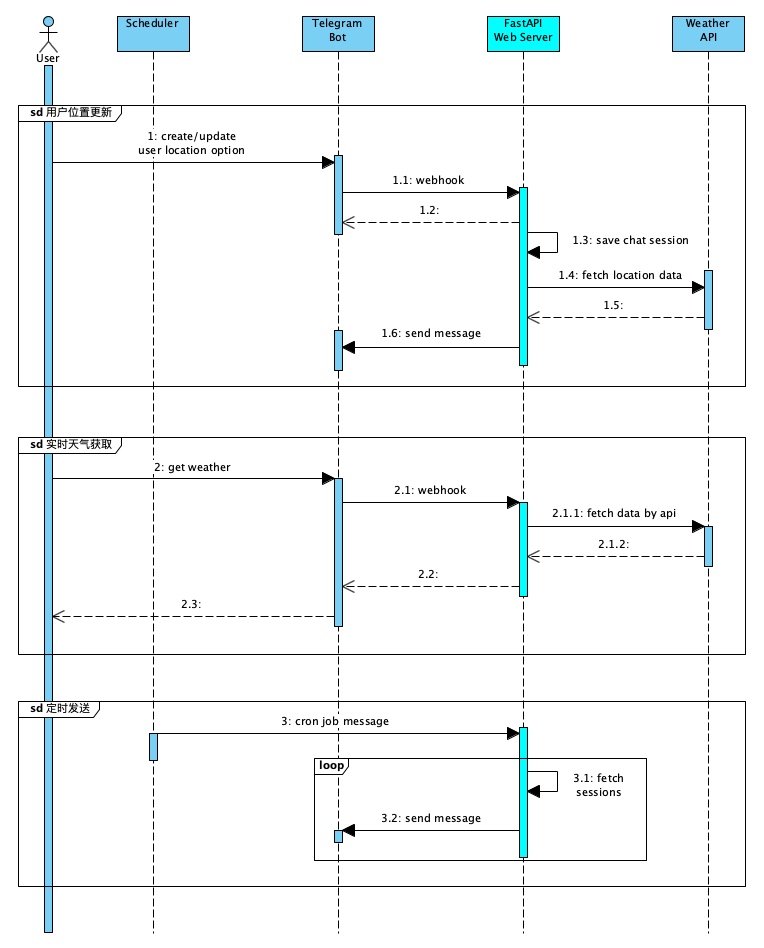
虽然是个小玩具,但也需要一定的分层与抽象,减少整体代码的「复杂度」:
weather_client 是一个天气预报获取的接口,定义标准的行为后,底层可以由任意获取外部数据逻辑构成,实现解耦与未来快速替换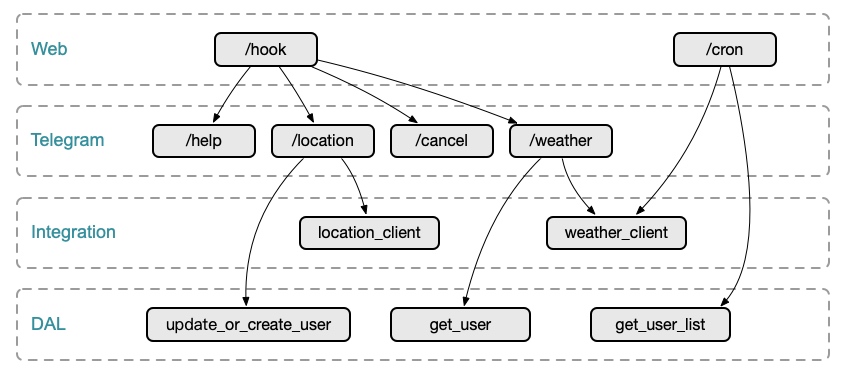
问题:cron 触发定时任务后,web 层会直接与 integration 与 dal 层交互,当然可以考虑新加一层 Service(同时统一做异常处理,日志打印等等)
感兴趣可以阅读这两段代码,在遇到 IO 操作时,如何提升性能:
telegram_bot.routers.cron.cron_handlertelegram_bot.intergration.http.HttpClient.get_responses本文介绍的天气预报小玩具,仅供个人练手使用。如果你有一些好的想法,欢迎欢迎私信我(@daya0576)一起结对编程~~ 2021 希望去认识一些新朋友 XD
]]>而其中的可视化功能,每次都令人印象深刻。这篇文章简单分享,个人解决问题的思考路径 & 简易实现~
1 | >> ... |
一开始看到这个问题,可能有些没有头绪,但有没有可能对该问题进行分解🤔
.
.
.
.
.
.
.
.
.
一棵树的可视化 ,分解为:
│ )├── or └── )行(Row)与节点一一对应,其中包含两个元素:
node 代表树的节点 continues 中每个元素表示:根节点至当前节点路径中的每个节点,是不是对应层级中的最后一位。
用来生成每行的前缀1 | from dataclasses import dataclass |
一般会使用 stack 先入后出的特性,这里简单利用生成器,即 yield 关键字实现一版:
1 | from typing import Tuple |
1 | from anytree import Node, RenderTree |
具体的实现在对问题拆解后,设计好对应的数据结构和算法,就能比较容易清晰的实现:
当然你也可以直接查看 anytree 的源码:anytree.render.RenderTree,其中有更多可扩展性的设计,例如样式主题,打印的模式等。
🍻cheers! have a gooood day~~
]]>reduce members’ pain by shedding requests that are not expected to affect the user’s streaming experience.
通过优先对用户视频观看影响较小的请求进行限流,保护后端系统负载的同时,尽可能避免用户体验受损。
下图中 Zuul 即网关,将客户端的所有 http 请求转发给下游 api: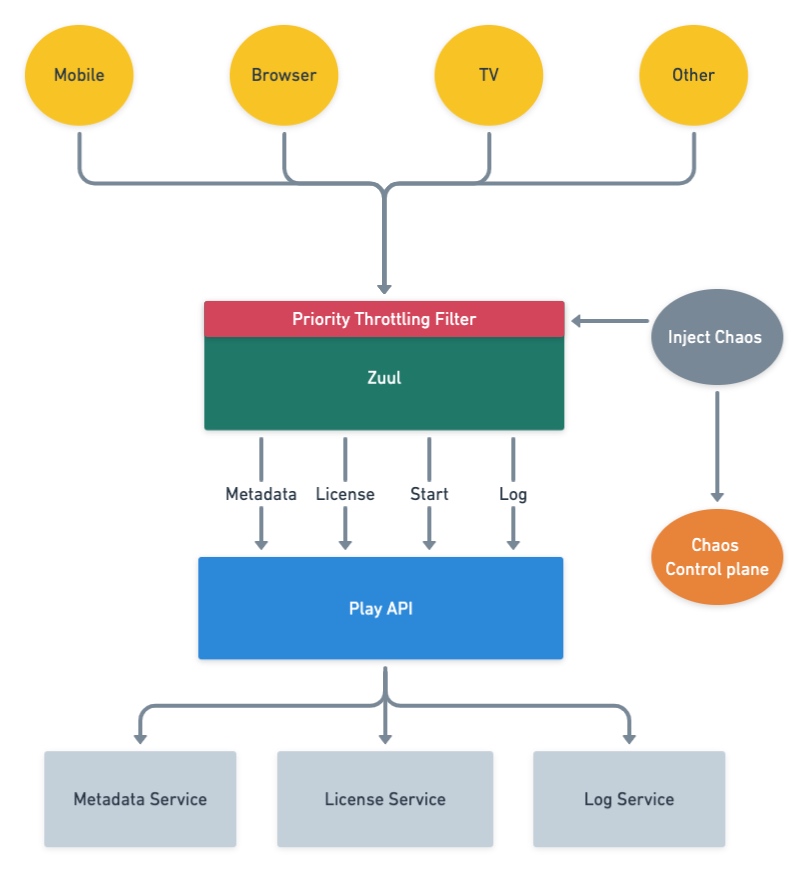
1 | 网关(Zuul)收到请求后,通过三个维度: |
Q. 如何保鲜以上的打分策略,i.e. 对 NON_CRITICAL 限流后,不会对用户体验造成严重影响?
A. 解法:Chaos Automation Platform
抽样极小人群做 A/B 测试:A 组在网关注入限流(参考上文架构图),观察对应的 *playback experience.*(最核心的指标还是视频是否可以流畅播放),与 B 组是否存在偏移。
如果出现播放问题则需要人工介入修复,并且定期做 regression 以达到保鲜的目的。
p.s. 文本默认你对 Django 的 ORM 已有一定的概念了解与实践~
《浅谈 Python Metaclass(上):type 与 object 原理介绍》
在 Django ORM 中,编写三行代码构建 model 类 -> 就可以通过 migrate 让框架帮你创建对应的数据库表(甚至包含索引等所有属性)。同时还可以根据它快速做一系列的增删改查操作:
1 | from django.db import models |
翻下 Django 的源码不难看出,上面定义的 Student 类继承了 models.Model,而它又继承于 ModelBase(**是一个由 type 继承而来 metaclass!**)
参考:django/blob/master/django/db/models/base.py#L72
1 | class ModelBase(type): |
如果阅读了上篇,不难理解普通类在定义时,默认使用 type 作为生成类的 metaclass。而 ORM 类继承于 ModelBase,并利用它进行类的初始化:
1 | # 1. 普通类(继承于 object) |
ModelBase.__prepare__: 此方法只在 metaclas 中有效,用于初始化命名空间(namespace),供后续保存类中所有属性,e.g. 类中的方法。并支持“注入”额外的属性,最后供下一步的 __new__ 方法使用(但 django 中并未重写,默认返回一个空字典)ModelBase.__new__: 以 ModelBase(cls) 和 待创建的类名称作为参数,创建并返回一个类(class)ModelBase.__init__: 对创建的类,做一些初始化操作ModelBase.__call__: 当上一步返回的类被调用时**()**触发(类似方法调用),这时也会触发 Student 与 Model的 init 方法。Student.__init__Model.__init__Django 主要对 django.db.models.base.ModelBase.__new__ 方法做了大量定制化操作
分为两个部分:
models.Model)被实例化{'name': <django.db.models.fields.CharField>}abstract,verbose_name 等如下图所示,熟悉的 objects(<class 'django.db.models.manager.Manager'>),也会在第二步被动态生成: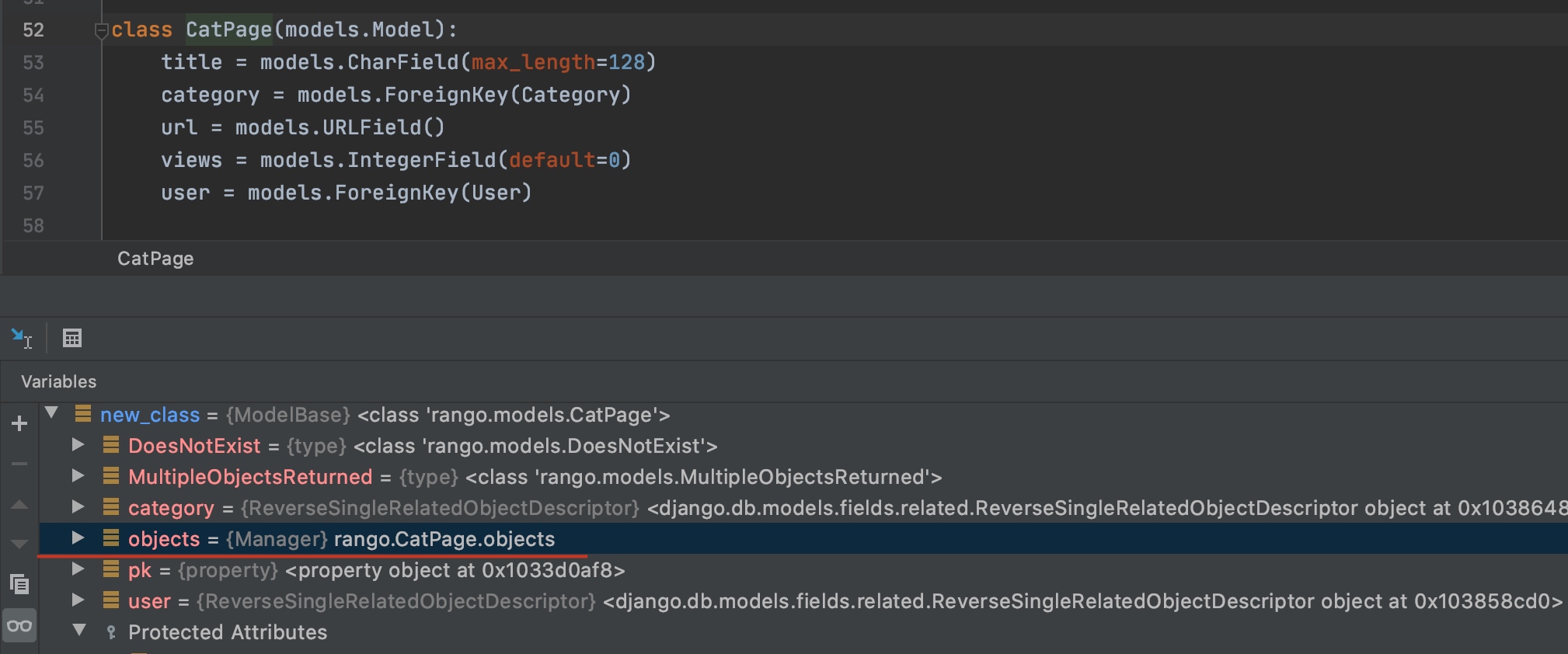
而所有定义的表字段(fields)被存储在 new_class._meta.fields 之中,在写入的过程中也会动态生成 get_{field}_display 方法😃: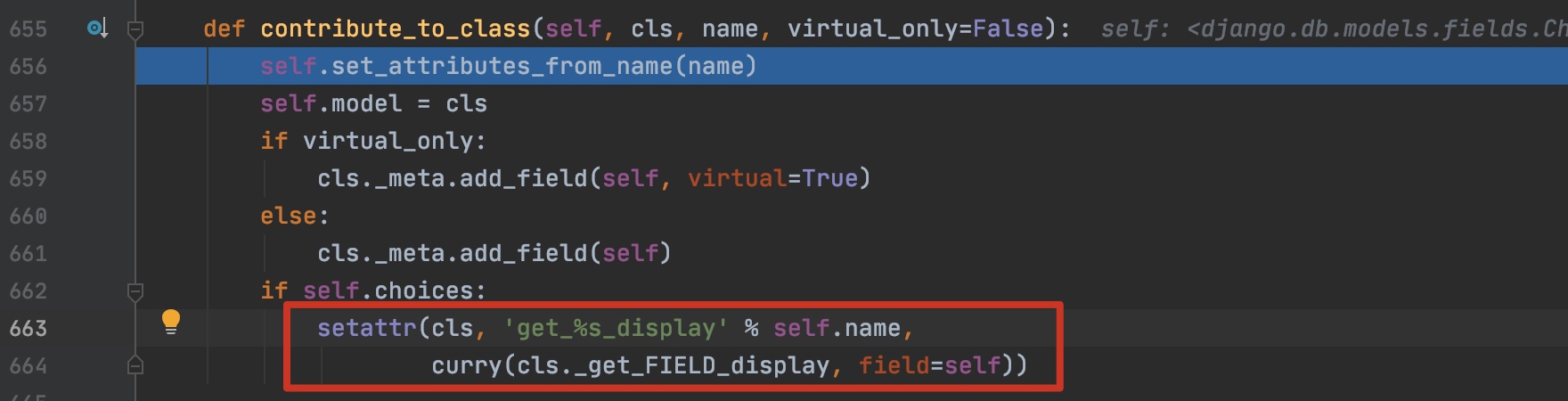
Django ORM 利用 Python metaclass 的强大特性动态的去创建类,改变了类初始化时的行为。将复杂留给了自己,大大降低了用户的学习和使用成本。
《浅谈 Python Metaclass(下):Django ORM 应用与实践》
__base__ 属性查看父类__class__ 查看某个 instance 的类型这两种关系,分别对应 UML 中两种画法:
新式类保持 class 与 type 的统一,i.e. Creating a new class creates a new type of object
python3 中默认都是新式类,文本中的例子也都是基于 python3.7
python 中万物皆对象,可以看到 object 与 type 为两个内置对象(primary object):
1 | object |
object 并没有父类(所以它是所有父类的顶端),但它是由 type 实例化未来的:
1 | object.__base__ |
不出意外,type 的父类是 object,同时 type 是由它自己实例化而来的(why?为什么一个对象的实现使它自己??)。
1 | type.__base__ |
emmm,有点绕,这时候就需要画个图: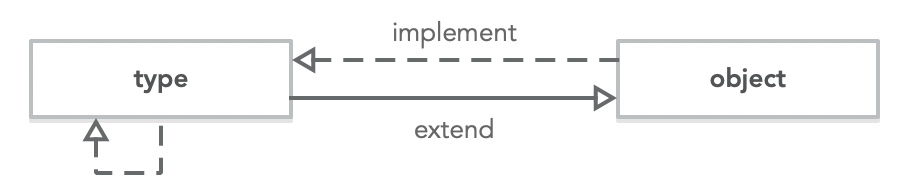
再看下其他内置对象,与 type 还有 object 的关系?
1 | >>> list.__class__ |
list 与 dict 继承于 object,由 type 实例化而来: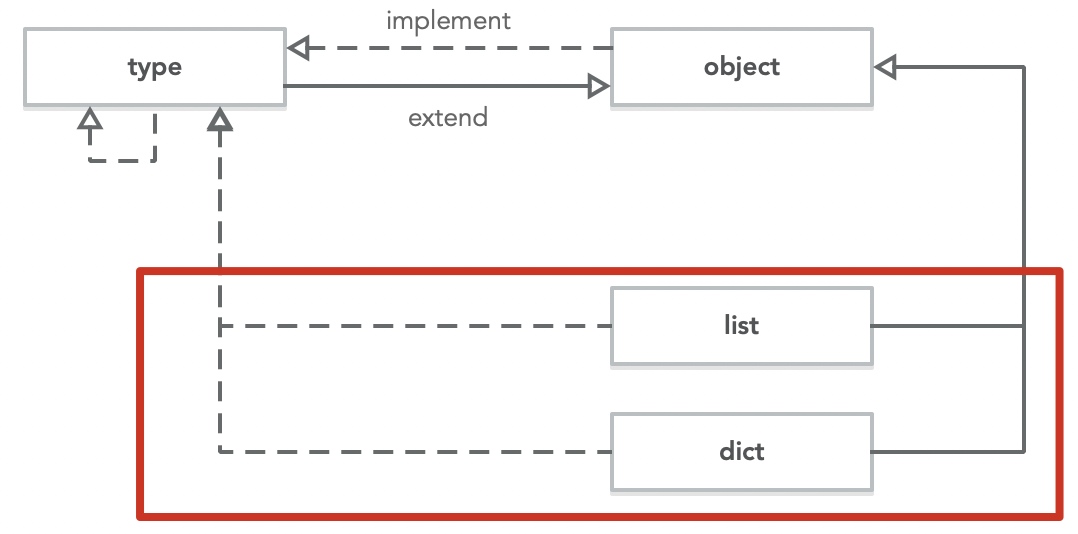
再实例化一个 list 和一个自定义类(MyClass)看看。
注意这时候 my_class 与 自定义列表 都是没有父类的:
1 | l.__class__ |
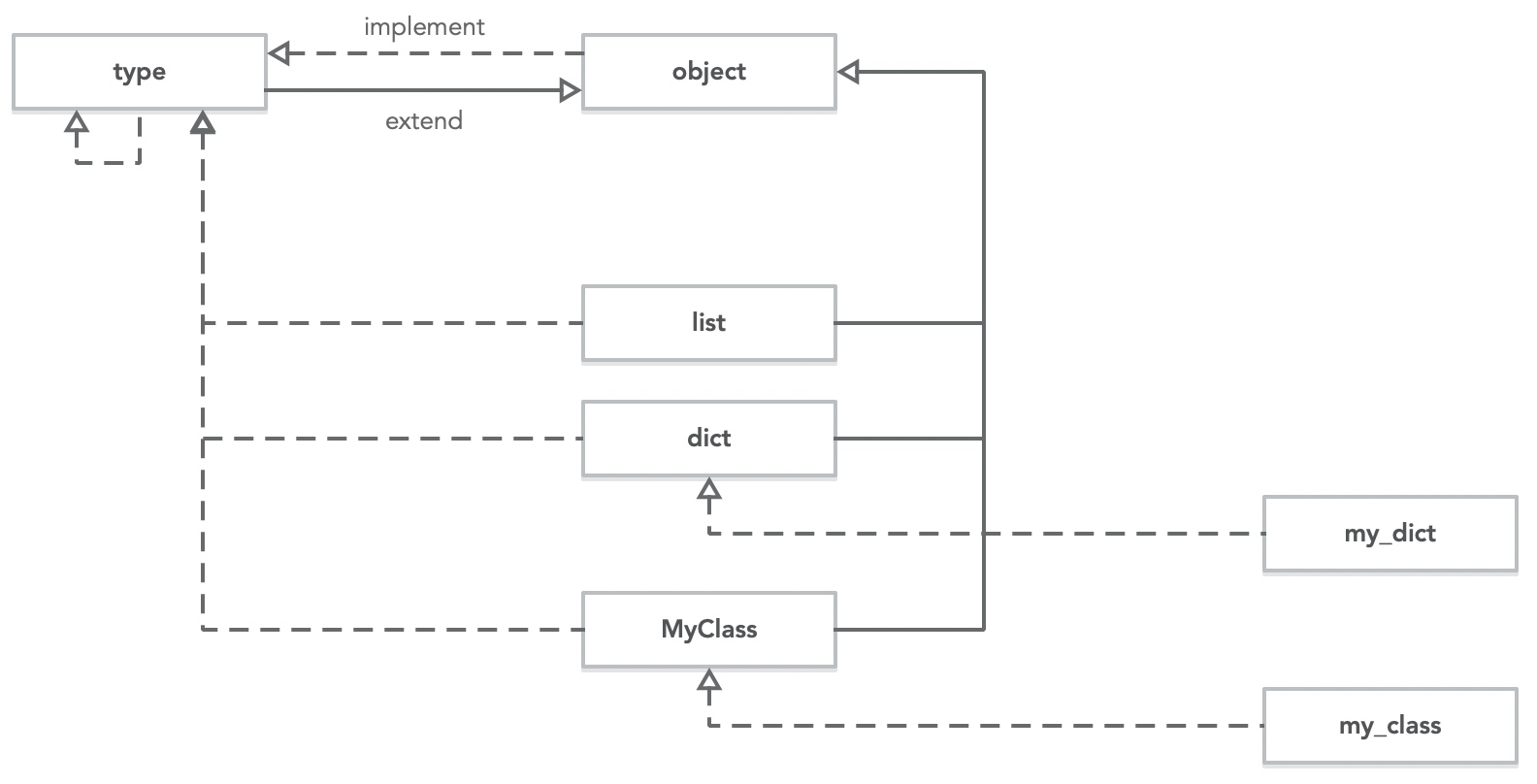
这个地方有两个小问题自问自答一下:
__new__ & __init__ 方法)。 基于上面的介绍,我们发现其实可以给所有的对象分为三大类(metaclass / class / instance):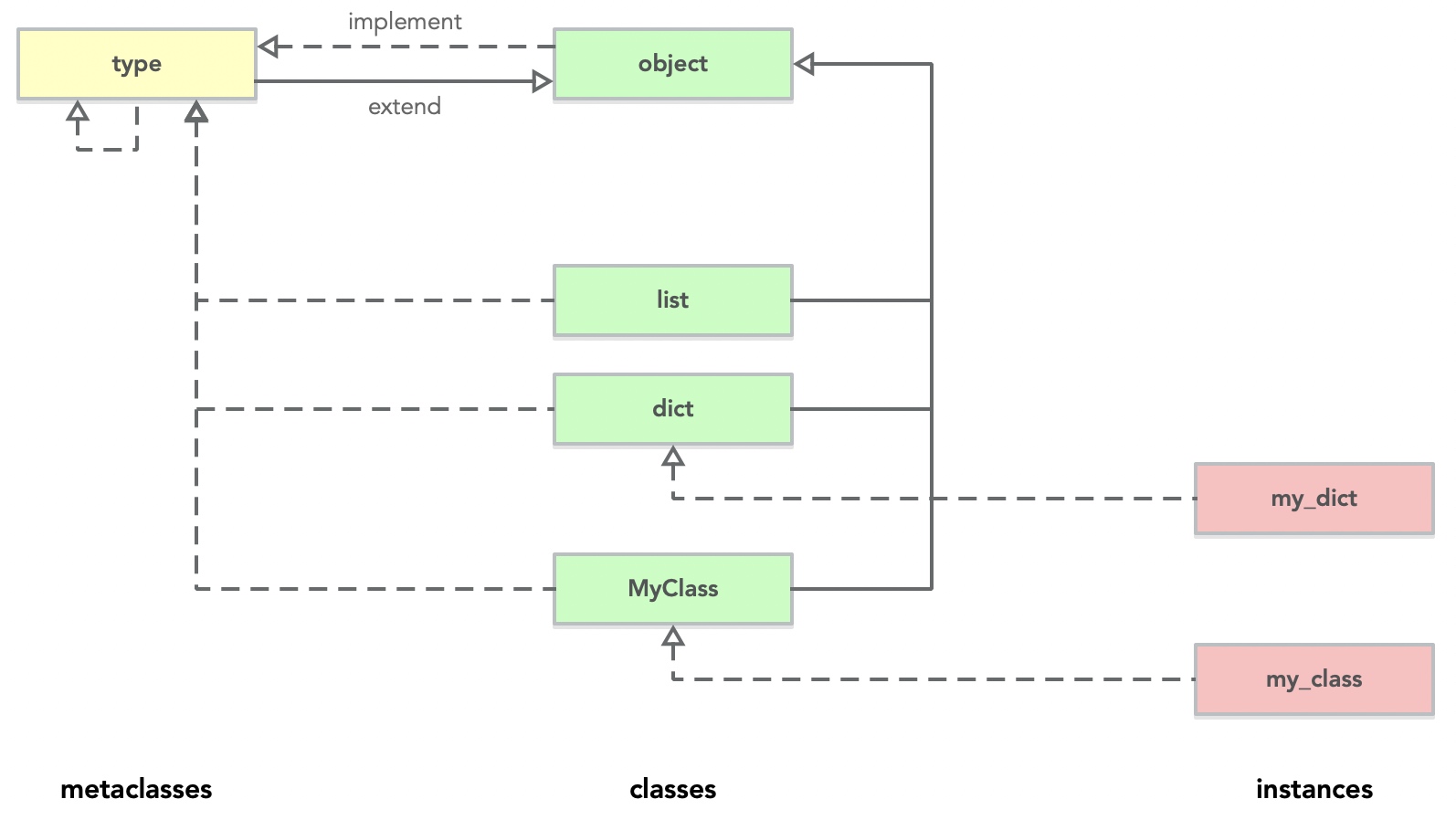
而 type 其实就是一个内置的 metaclass。这时引出这篇文章的下篇:《浅谈 Python Metaclass(下):Django ORM 应用与实践》
突如其来的幽默感🤣:
Q:When should I use a metaclass?
A:Never (as long as you're asking this question anyway :)
稍微有点绕,还是需要一些时间消化。但个人总觉得需要将继承与实例化区分开后(例如 type 是实例化维度,而 object 是继承时间的产物),再去看待他们之间的关系。
嘿嘿,读原文时,刚好也存在类似的解释:
There are two kinds of objects in Python:
- Type objects: can create instances, can be subclassed.
- Non-type objects: cannot create instances, cannot be subclassed.
更进一步,「实例化」与「继承」其实都是创建一个新对象的“两种手段”:
class 语法(指定父类或默认 object),来创建一个 type 对象。所以 class A: pass 与 A = type("A", (), {}) 是等同的。() 语法,基于某个 type 对象进行对象的新建。返回一个 type 对象或 非 type 对象(metaclass 与 class 的区别)。l = [1, 2, 3]观看一个 Pycon2017 的分享视频之后:《Why you don't need design patterns in Python?》,对上面的疑惑,逐步有了一些自己的理解。首先还是先分享几个经典设计模式在 python 的具体实践。
使用 Python 直接套用 Java 中的经典写法:
1 | class Logger(object): |
更优雅的实践(__new__):
1 | class Logger(object): |
当然也可以@classmethod,但视频中提到一个更好的做法(类似 spring 中的 IOC..),即 python 中原生的 import 就是一个 singleton 的天然实现(并且更加直观):
1 | class Logger(object): |
一个分布式的微服务系统中,每个模块或应用之间,通常只会提供特定的服务与接口(interface)供上游调用,以保持应用间的耦合度,同时屏蔽各自内部复杂的实现。
而上文提到 python 中提供了 __init__.py 文件,天然的支持这个模式。
后来才慢慢明白,为什么以前一些同事,喜欢将模块中对外暴露的接口或实例,统一放置在 __init__ 文件中管理,而不是「模块一」可以 任意的引用「模块二」中的任意类,这样会大大增加系统的复杂度与维护成本(但 python 如何在系统层面,防止引入这种坏代码的味道呢?)。
《Head First 设计模式》 中 java 的实现: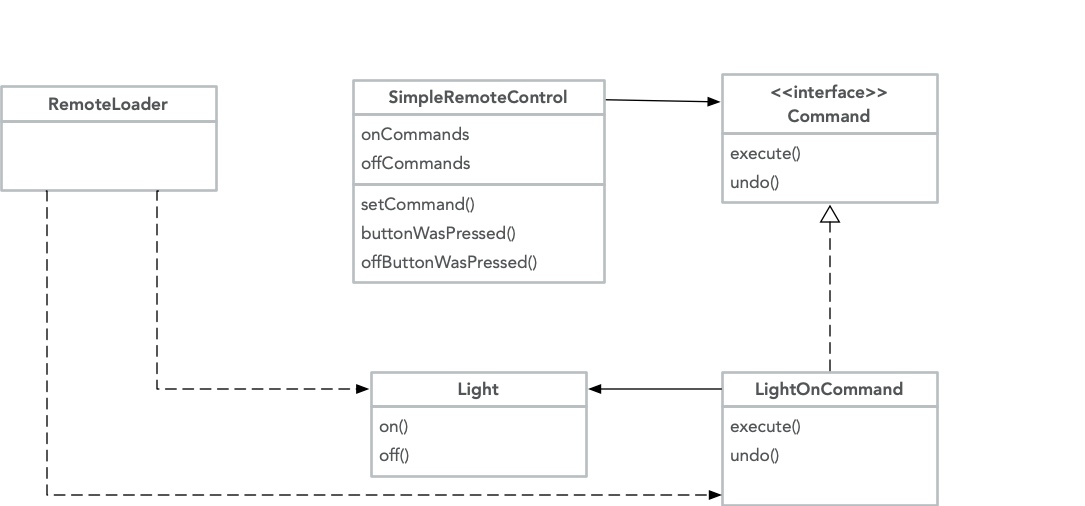
完整代码参考 github
效果:
1 | remoteControl.setCommand(0, livingRoomLightOn, livingRoomLightOff); |
命令模式的好处在于,允许将动作封装为命令对象,这样一来可以随心所欲并且独立的存储、传递和调用它们。
python 中万物皆对象,所以可以直接将方法(而不是类)作为参数进行传递与赋值。当然标准类也原生提供了附带参数的语法糖(但此处如何约束不同接口的统一行为呢?比如所有的动作只接受 on/off 两个输入):
1 | import functools |
个人理解这个模式的核心思想在于 java 中 重载(function overloading),即一个类中支持同时共存多个同名的函数,如果入参数量或者类型不同,对应的行为也不一样。
而在 python 中,可以使用参数类型的字符,来获取对应不同的方法。p.s. 但个人非常不喜欢这种做法,感觉很这样的代码太“脆弱”了。。
1 | class ASTVisitor: |
标准库提供@singledispath这个注解,来实现这个模式(但有唯一一个缺陷在于目前不能用于类内的方法):
1 | # 1. func |
python 中的方法可以返回任何类型的实例,所以也自然没有工厂模式??😂
That's all, 上一小节笔者举了几个「设计模式」在 python 中的具体应用,给大家一个体感。如果你想了解更多,可以收藏这个 页面,以查看更多信息。
我看过也写过太多糟糕的 python 代码,例如超过几百行密密麻麻的方法。当接触 java 与设计模式后,发现有很多特定的套路,可以将代码逻辑持续解耦。虽然牺牲了一定语法上的简洁性,但可读性与可维护性确实大大增加。
从文中举的几个例子可以看出,设计模式只是提高代码复用性,可读性的一个手段,应该结合语言特性去最简洁的实现这个「目的」。反而言之,如果设计模式只是为用而用,反而只会画蛇添足。
Python 里没有接口,如何写设计模式?
Python 是一门动态语言,它的方法接受任何参数,当不符合预期时,去处理对应的 exception 即可🤔
Patterns are signs of weakness in programming languages.
这个观点我也不太认同,接触 java 后还是学到了很多,例如利于多人协同维护大型项目的最佳实践。每个语言都有自己的优势与劣势,还是可以相互借鉴的,例如蚂蚁 SOFA 工程的分层🆒: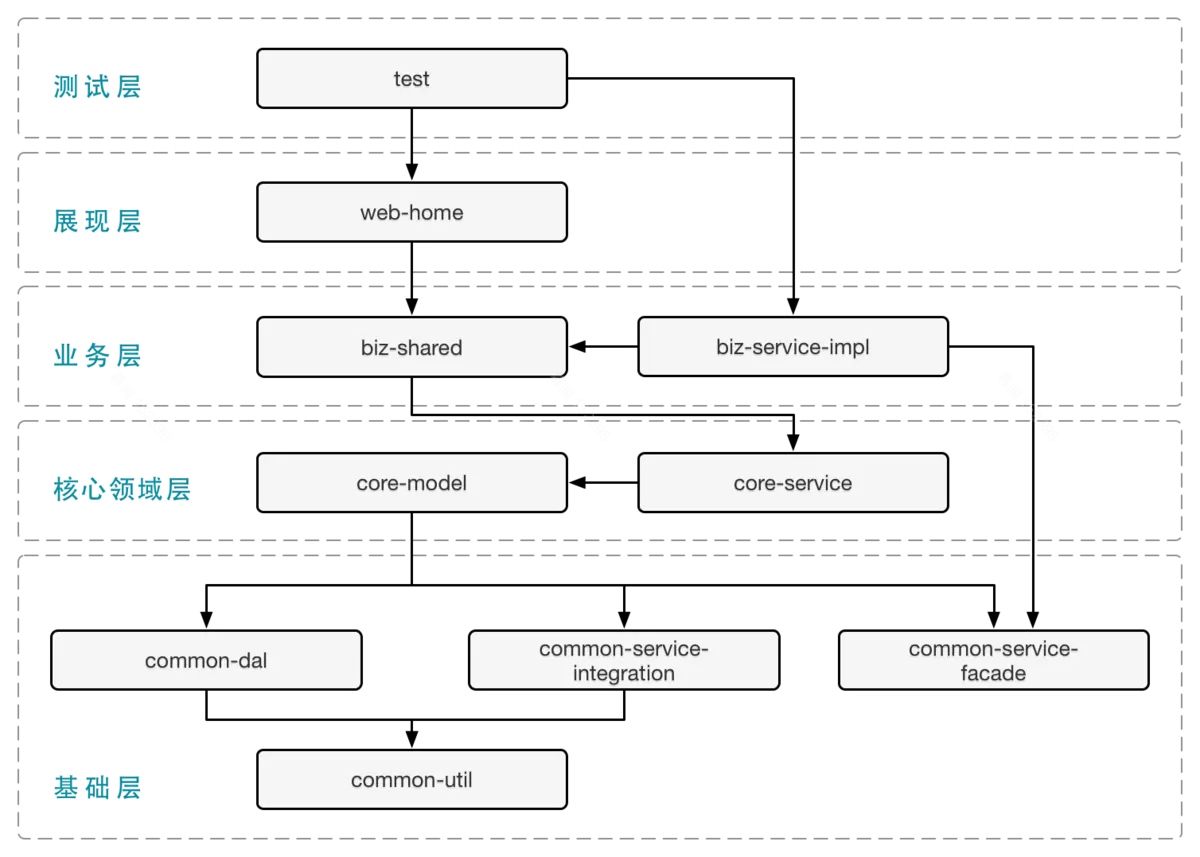
grep 去搜索内容,不仅等待时间长,甚至可能占用机器资源,影响线上业务请求 😓那有什么更好的办法吗?线上日志按照规约,会按「日」进行轮转切割,但故障发生的时候,我们期望的那条日志一般在"最近十分钟"之内,所以如果可以“反向 grep” 日志,是否可以大大提高查询的性能?🤔
虽然在好几个 GB 的文件面前,grep 命令有一丝疲软,但不可否认 grep 命令高效。主要由以下两个关键的原因:
简单记录一下自己的一点理解。当然可以直接跳过,推荐参考下面官方的解释。
在 B 文本中,搜索 A 关键字:
算法的精髓除了不用比较每个字符,还提前对待搜索的关键字做了计算,i.e. 生成一个字典,其中保存了关键字中每个字符,及所有 substring 对应的待平移距离。
官方可视化 demo:
https://www.cs.utexas.edu/~moore/best-ideas/string-searching/fstrpos-example.html
The key to making programs fast is to make them do practically nothing. ;-)
参考作者的精彩回复:https://lists.freebsd.org/pipermail/freebsd-current/2010-August/019310.html
扯远了,回到正题,如何***反向搜索***文件中的一条记录呢?
workload 为一个真实的线上日志:
1 | $ wc -l tracelog/rpc-server-digest.log.2020-11-02 |
当直接去 grep 的时候,花费约 30ms
1 | $ time (grep 21885857160436159747673092289 tracelog/rpc-server-digest.log.2020-11-02) |
一个直觉的优化为先 tail 最后 10000 行日志,再进行 grep
虽然大大提升了速度,但比较挫,有没有更好的做法呢?
1 | $ time (tail -n10000 tracelog/rpc-server-digest.log.2020-11-02 | grep 21885857160436159747673092289) |
搜索资料后,有一个 tac 命令可以反向对文件做输出,但为什么耗时一夜回到解放前呢?
1 | $ time (tac tracelog/rpc-server-digest.log.2020-11-02 | grep 21885857160436159747673092289) |
定睛一想,原理很简单,虽然反向搜索了,但还是对全文进行了遍历,效率自然很低(这里有个细节:反向比正向搜索多出了一倍多的时间)
所以假如我们只需要最后一条匹配的记录🤔 添加 -m1 参数后,终于达到了预期的效果:
1 | $ time (tac tracelog/rpc-server-digest.log.2020-11-02 | grep -m1 21885857160436159747673092289) |
Q: tac 的全称是什么 XD
A: cat <-> tac
p.s. 本文更多的是个人的笔记,完整代码请参考这个 repo: https://github.com/daya0576/java8_practice
了解过「策略设计模式」的同学,都知道将「行为」作为参数,可以增加代码的灵活性与可读性,但代码看上去还是有一丝累赘🤔
...
参考《在 java & python 中,如何优雅的筛选一堆苹果》
1 | (Apple a1, Apple a2) -> a1.getWeight().compareTo(a2.getWeight()); |
主要分为三部分:
return "Hello" + i)函数式接口?
原名叫做 functional interface,为只有一个抽象方法的接口。
java8 还专门给抽象方法 @FunctionalInterface 注解,在编译阶段做检查。
举个例子:
1 | // 官方的 Runnable 接口 |
java.util.function 中几个函数式的接口:
()->void) T->boolean) -> 输入一个参数,返回 boolean,用于例如列表中元素的筛选(U,T)->R) -> 输入两个参数,返回 boolean,用于排序T->void) -> 返回 void,用于例如打印一个列表中的所有元素()->T): 用于实例化多个对象T->R) -> 返回任意泛型的结果,例如用于获取一堆苹果对应的重量以下两种写法是等价的:
1 | // lambda |
引用又分为三种:
可以将多个 lambda 通过 and/or/negative 关联起来,例如筛选出又红又大的苹果:
1 | Predicate<Apple> greenApplePredict = (Apple apple) -> "green".equals(apple.getColor()); |
利用 andThen 和 compose 两个默认方法,将函数组合成自定义的 pipeline
1 | // g(f(x)) |
以前以为 java 中的流只是为了让代码看起来更加简洁优雅,但另一个非常重要的优势在于自动的多核并行处理,提升性能,同时不用再担心如何处理线程与锁(在书的第七章中会重点介绍)。
⚠️注意:stream 与 python 中的 generator 类似,产生后只能被消费一次。
flatMap 的例子:
1 | List<String> words = Arrays.asList("hello", "world"); |
以及如何生成笛卡尔积(但有一句说一句,感觉不是很直观。。):
1 | // 给定列表[1, 2, 3]和表[3, 4],返回笛卡尔积: |
anyMatch/allMatch
findAny: 注意这个方法返回的是 Optional 容器类(代表一个值存在或不存在),目标为有效的避免 NPE 的情况。
findFirst: 故名思义,与 findAny 的区别在于是否有序的第一个
sorted
distinct
但如果你想找到多个交易中,金额最大的拿笔交易:
1 | // 找到最大金额的交易 |
用文中的一张图总结一下: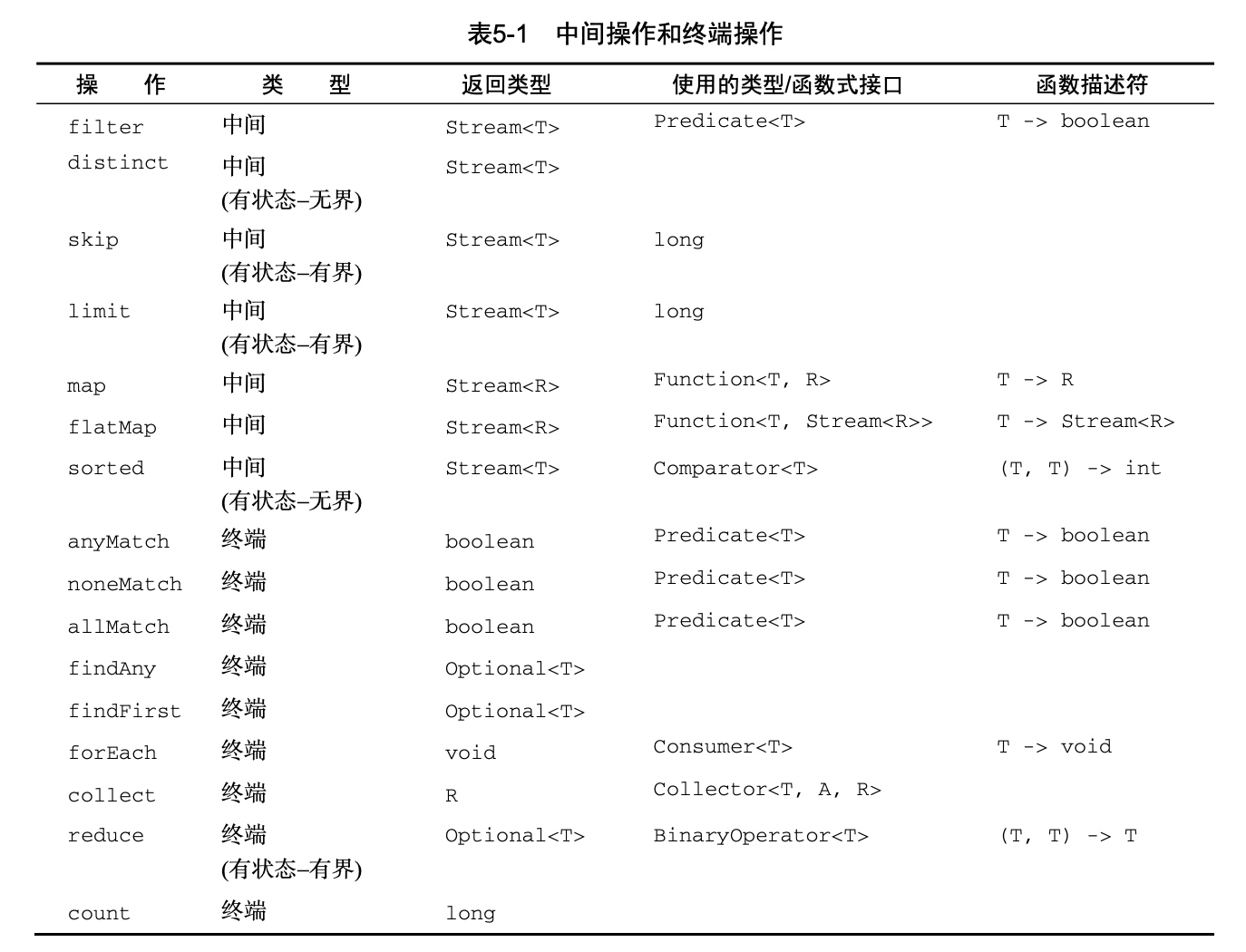
collector 的三大功能:
1 | Comparator<Dish> dishCaloriesComparator = |
1 | int totalCalories = menu.stream().collect(summingInt(Dish::getCalories)); |
1 | String shortMenu = menu.stream().map(Dish::getName).collect(joining()); |
其实就是 groupby
1 | Map<Dish.Type, List<Dish>> dishesByType = menu.stream().collect(groupingBy(Dish::getType)); |
也可以直接计算 count
1 | Map<Dish.Type, Long> typesCount = menu.stream().collect( groupingBy(Dish::getType, counting())); |
还可以多级的分组。。。不太喜欢,就不列例子了
以下的返回结果分别为 true/false 对应的 map
1 | Map<Boolean, List<Dish>> partitionedMenu = menu.stream().collect(partitioningBy(Dish::isVegetarian)); |
好复杂,跳过
罗列了一些设计模式,跳过。
Q: 这个挺有意思的,下面堆栈中的 $0 是什么意思呢?
A: 这些表示错误发生在Lambda表达式内部。由于Lambda表达式没有名字,所以编译器只能为 它们指定一个名字。
1 | Exception in thread "main" java.lang.NullPointerException |
利用 peek 插入打印日志的动作:
1 | List<Integer> result = numbers.stream() |
Q: 首先回答为什么需要默认方法呢?
A: nterface 新增一个方法的时候,不让已有的代码报错,从而有了默认方法。
举个例子:java 中 extend 只能继承一个父类,但可以 implement 多个接口。好处在于默认方法的复用
1 | public interface Rotatable { |
但假如 Rotatable 和 Moveable 接口,都存在一个相同名字的默认方法,造成的冲突要如何解决呢?
为避免 NPE 引入了 Optional 对象
空的 Optional
1 | Optional<Car> optCar = Optional.empty(); |
非空值创建 Optional, 注意如果 car 为 null,则立刻抛出一个 NPE
1 | Optional<Car> optCar = Optional.of(car); |
可接受 null 的 Optional
1 | Optional<Car> optCar = Optional.ofNullable(car); |
如何重构下面的代码呢?
1 | person.getCar().getInsurance().getName(); |
假设 person 是一个 Optional 的对象:
1 | person.flatMap(Person::getCar) |
上面 flatMap 与 map 的区别:
都是在不为 null 的情况下,根据约定 flatMap 返回的是 Optional 对象,而 map 则直接返回对应的值。
将 Insurance 定义为 Optional 类型的另一个好处在于,告诉未来的同事,它很明显可能是一个空值。
case1: 用Optional可能为null的结果
1 | // 优化前 |
case2: 巧用异常处理
1 | // 优化前 |
使用 异步线程 + future,避免一些 IO 操作的时候阻塞当前线程:
p.s. 完整可运行的代码:链接
1 | public class Main { |
如果需要对多个商品发起查询呢?
可以考虑使用 parallelStream 并行运行,提高性能(因为运行不要求是有序的)
等待所有 查询 执行完毕后,进行汇总。当然也可以使用 anyOf 方法,意味着任意一个查询结束即返回。
1 | CompletableFuture[] futures = findPricesStream("myPhone") |
p.s. 说实话有点过于复杂了,不太喜欢。。
(略)
(略)
]]>需求: 在一堆苹果中,筛选出重量大于 100g 的苹果🍎,同时也支持过滤所有绿色的苹果
了解过「策略模式」的同学,都知道可以将「行为」作为参数,增加代码的灵活性与可读性。
但看上去有一些累赘哦。。🤔
1 | public interface ApplePredict { |
同时使用内置的 Predicate 方法代替 ApplePredict,然后利用匿名函数代替 AppleHeavyPredict,
1 | import java.util.function.Predicate; |
java8 支持方法的引用,分为三种:
所以 lambda 又可以简化为方法引用(当然成本为在 Apple 中新增了一个isHeavyApple方法):
1 | import java.util.function.Predicate; |
那么 filterApples 是否也可以被省略呢?利用 java8 中的 Stream 一行代码过滤出你想要的苹果:
1 | List<Apple> heavyApples = apples.stream() |
虽然语法上略有不同,但大致思路与 java 的实现可以说基本一致!
1 | apples = [Apple("green", 150), Apple("red", 100)] |
同样支持直接将「方法引用」作为参数:
1 | def is_heavy(apple: Apple): |
但很久以前也不记得在哪本书上看到,不推荐 filter 而统一使用更为直观的 list comprehension:
1 | heavy_apples = [apple for apple in apples if apple.weight > 100] |
记得大学里学习 java 用的还是 1.6,还没有这么多骚操作。。
虽然现在双放都可以用一行代码实现需求,但个人觉得这轮比拼还是 python 的 list comprehension 更胜一筹🤔
因为这种特有的写法更符合人类直觉,你觉得呢?😄
]]>为了不甘一直处在一知半解的状态,所以这个周末准备全面学习一下对应语法与原理,并与 python 中的实践做一个对比,以便有一个更加深入的理解~
常用的语法大致有两种:不带参数 & 带参数
刚好拿一个最近在写的 telegram 机器人中,接口权限管控的例子:
1 | def admin(f): |
使用装饰器后,实现可插拔地控制 promote 接口只有「管理员」可以调用,达到代码解耦的目的:
1 |
|
python 中有一个包叫做 retry,就是一个很不错的例子:
https://github.com/invl/retry/blob/master/retry/api.py
1 | def retry(exceptions=Exception, tries=-1, delay=0, max_delay=None, backoff=1, jitter=0, logger=logging_logger): |
源代码使用了内置的 @decorator 方法简化了代码,稍微有一点不太好理解,其实等同于:
1 | def retry(exceptions=Exception, tries=-1, delay=0, max_delay=None, backoff=1, jitter=0, logger=logging_logger): |
当被装饰的接口(make_trouble)在执行过程中,如果抛出了预期内的 exception((ValueError, TypeError)),则按提前制定好的策略进行重试:
1 |
|
看上去有一点复杂,但只要牢记以下 两者语法的等价关系,即可理解 Python 装饰器的核心思想了😄:
1 |
|
1 |
|
注解的定义 与 接口的定义 非常相似(其实注解就是 interface 的一种):
1 | // 定义 |
使用方式与 python 非常类似,参考下面的例子:
1 | // 使用 |
但不同于 python 的是,在 java8 发布后,注解还可以在类/方法/变量的类型上配合使用(Type Annotations),例如:
1 | // 1. 类的实例化 |
java 还实现了一部分内置的注解
例如 @FunctionalInterface: 个人理解就是将一个方法的 reference 作为一个变量🤪
注解还可以直接用于其他注解的定义中😯,例如:
@Retention ⚠️划重点,注意 Retention 是保留的意思@Target 定义了使用对象的限制,例如:@Repeatable: 是否可以重复在一个类上使用。@Inherited: 是否允许子类继承该注解例如 @FunctionalInterface 的定义:
1 |
|
虽然个人觉得没有太多必要,但 java 还是提供了这个选项。看了一眼实现还是挺有意思的,简单描述一下:
1 | // 第一步:定义单个 Schedule 注解 |
说实话写到这里,虽然大致知道了注解的用法,似乎对其原理还是毫无头绪。参考了一些文章后的理解:
上文提到注解其实就是一个接口,而它的本质:继承了 Annotation 接口的接口:
对 class 文件反编译后:
1 | // Compiled from "Hello.java" |
利用了 java 的反射机制,获取一个注解类实例,并拿到对应的 value 属性。
1 | Class cls = Main.class; |
但还是不太明白,从定义 annotation 的接口,到获取对应的实例中间,到底发生了什么呢?
查阅了一些文章后,尝试开启 saveGeneratedFiles 为 "true" 后,目录里出现了 proxy.class,而其中 $Proxy1.class 就是我们苦苦寻求的真相。
1 | ➜ annotation tree |
当我们上文在调用 getAnnotation 获取注解实例的时候,**返回的其实是一个 jdk 通过动态代理机制生成的一个代理类 $Proxy1**,它实现了我们的注解接口,并将所有方法重写:
所以调用 value 方法的时候,本质上是调用 AnnotationInvocationHandler#invoke,通过方法的名称(value)作为 key,去注解的 map 中取出对应的 value: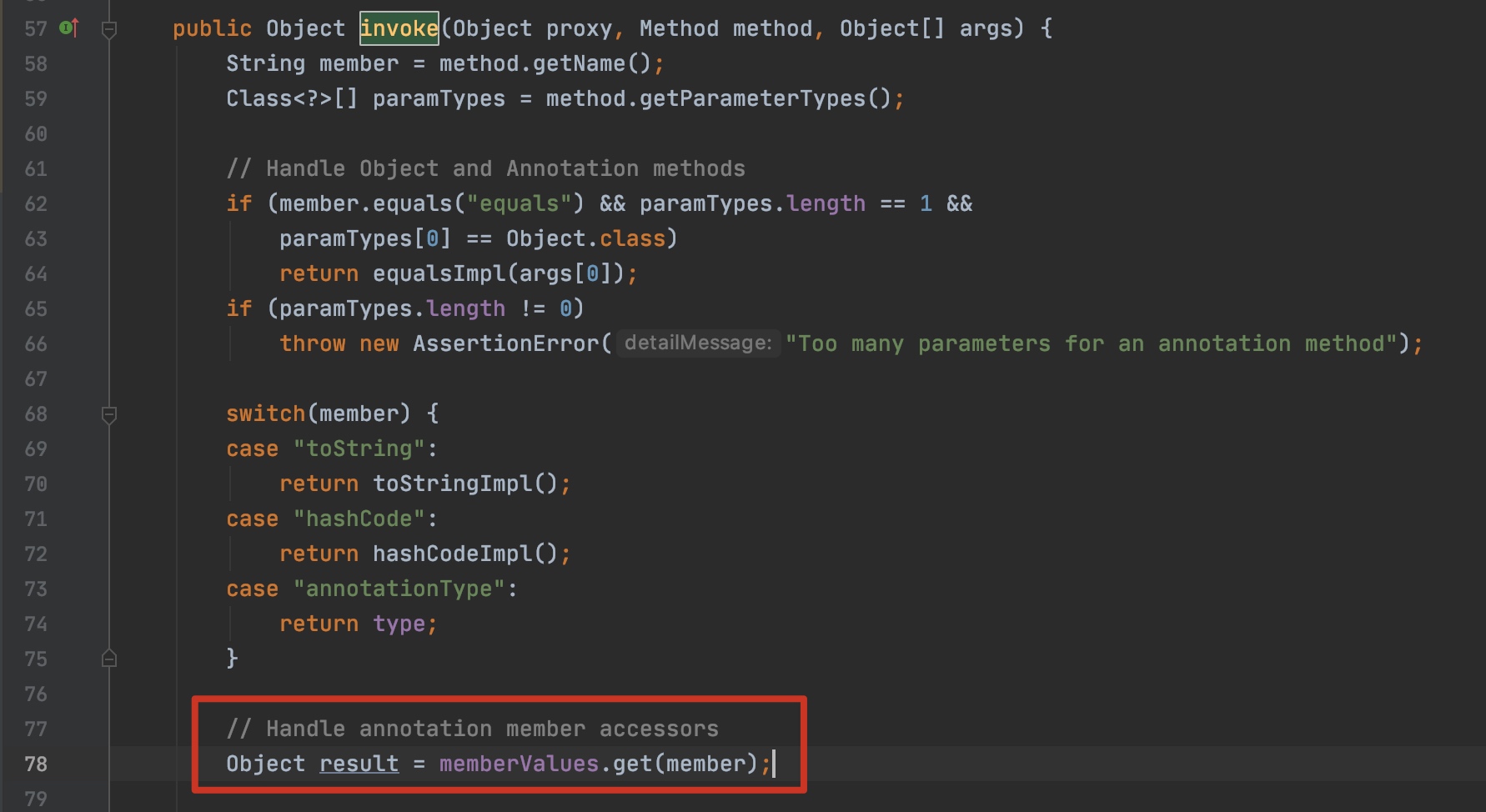
终于真相大白了,默默在心里说了一句:原来是这样~
p.s. 偶然翻到一个简化版的实现,感兴趣可以看看:https://gist.github.com/nathansgreen/11084652
python 装饰器与 java 的注解,虽然使用的语法相似,但同时貌似除了语法就没有其他类似的部分了。。。
从文章的篇幅不难看出,java 的 annotation 和 python 相比「复杂」的许多。但到底是功能强大的好,还是 Simple is better than complex 呢?你的心中有没有一个答案😊
OO 原则是我们的目标,而设计模式是我们的做法。
最近写 java 半年多,虽然这门语言看上去有一丝笨重和啰嗦,但和设计模式遇上,就好像咖啡与牛奶的融合,变成一杯香醇的拿铁🤔。本文做为个人的读书笔记(水一篇博客),同时如果能帮到你就更好啦!
大家应该还知道一本书,叫做 《设计模式:可复用面向对象软件的基础》,其中非常精辟的将设计模式分为三类(持续学习更新中):
将易变的属性,做为一个对象变量去初始化进行组合(行为也是一种对象!)
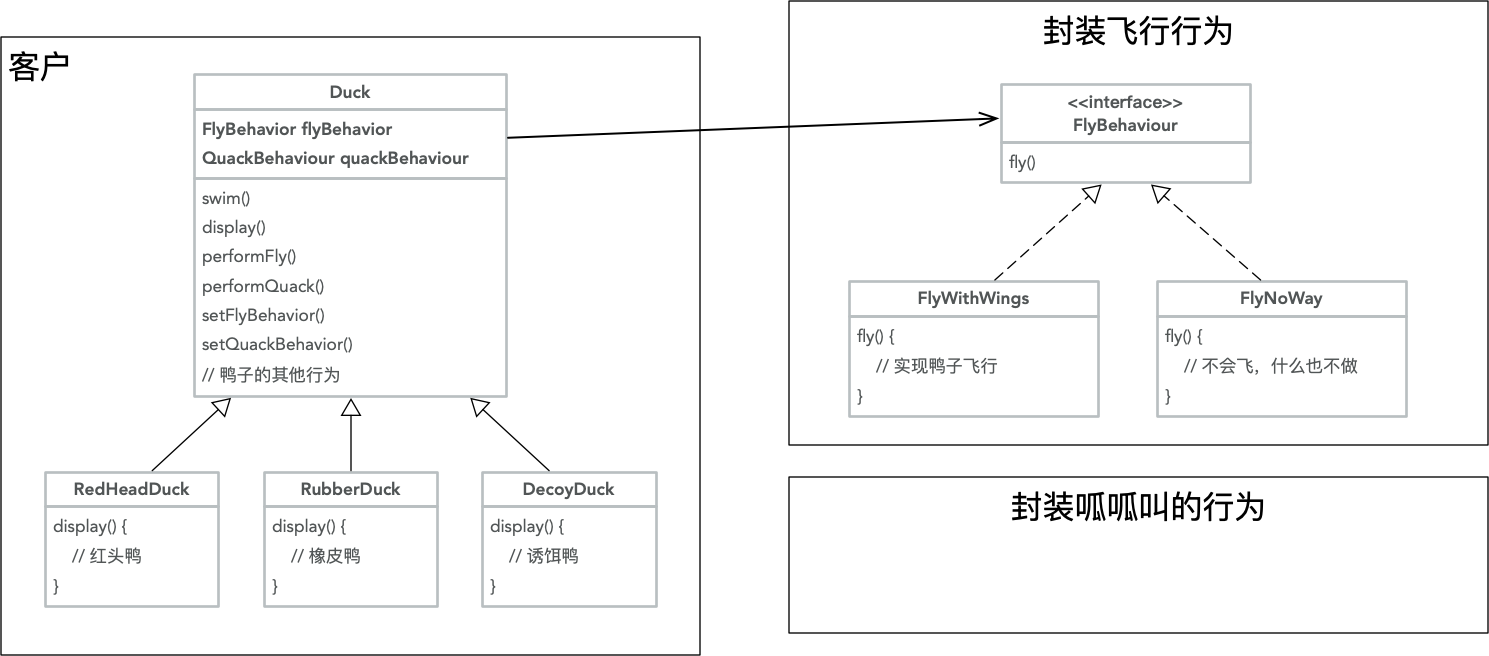
稍微解释一下:不同的 Display 在实例化时,会在 WeatherData 中被注册为「观察者」统一管理,当「被观察者」(气象数据)发生变化时统一触发通知。
目的:让观察者和被观察者,尽可能的解耦。
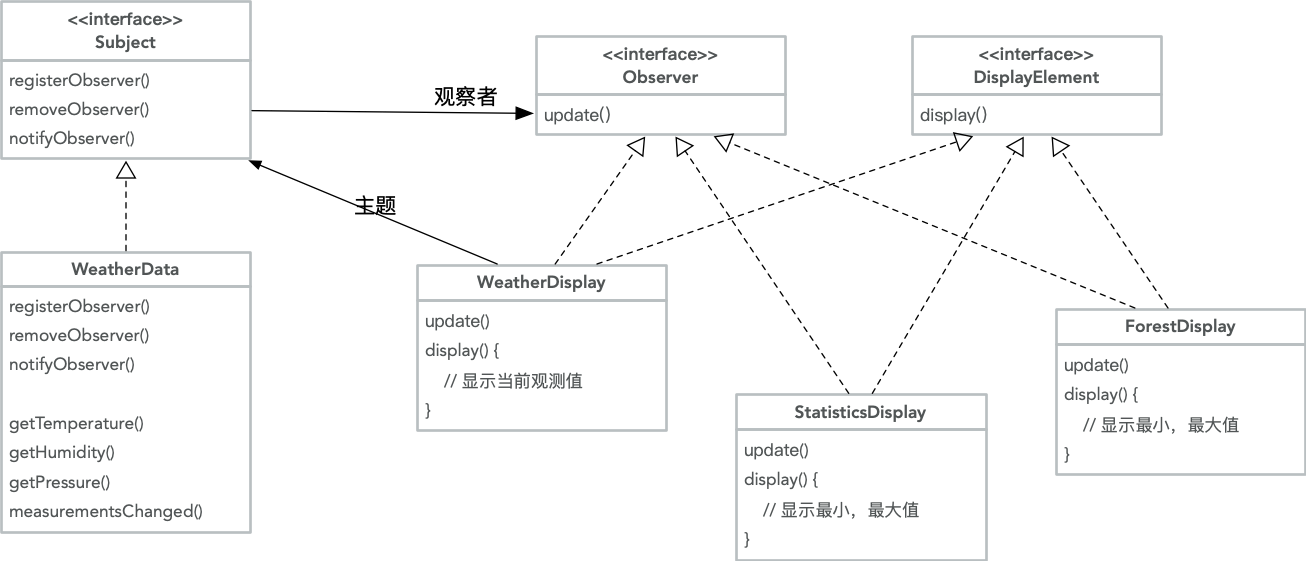
效果:
1 | WeatherData weatherData = new WeatherData(); |
当遇到继承无法解决的问题,可以尝试使用更为优雅的装饰者模式:
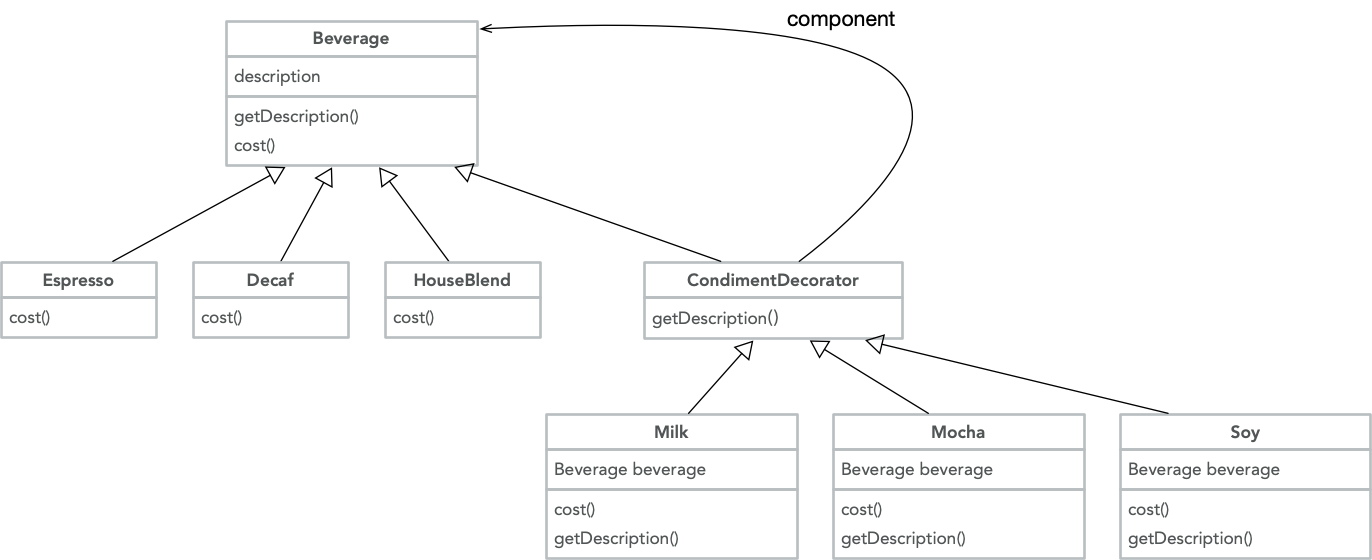
最终效果如下,但初始化的方式有点简陋。文中也提到后续 “工厂” & “生成器” 模式,将有更好的方式建立被装饰对象。
1 | // 来一杯 Espresso |
简单工厂其实不是一个设计模式,反而更像是一种编程习惯。
在父类中提供一个创建对象的方法, 允许子类决定实例化对象的类型。例如下面代码中
1 | SimplePizzaFactory factory = new SimplePizzaFactory(); |
章节中还提到了抽象工厂模式,本质上是两层的 factory,感觉有点太花了。。感兴趣可以阅读原文。
再熟悉不过的老朋友,就不多说了。简单回答两个问题:
Q: 为什么不直接使用全局变量呢?
A: 因为需要在一开始就创建好对象,但实际一直没有用到,造成资源的浪费。有种类似 lazyload 的意思。
Q. 什么需要单例呢?
A: 确保一个类只有一个实例,并提供一个全局访问点。

效果:
1 | // 注意有个小细节:Singleton 的构造器是私有的,意味着无法被直接 new 出来(实例只能通过工厂模式创造出来) |
RemoteLoader 可能有点困惑,其他可以简单将它理解为 main 函数,将 Light 和 LightOnCommand 绑定,并将 command 与 remoteControl 绑定:
效果:
1 | remoteControl.setCommand(0, livingRoomLightOn, livingRoomLightOff); |
命令模式的思考在于,允许将动作封装为命令对象,这样一来可以随心所欲的存储、传递和调用它们。
Target 理解为鸭子,拥有 fly 与 quack 的接口。
Adaptee 是火鸡,只有 fly 和 gobble 接口。
Adaptor 继承了 Target 接口,并根据火鸡的特效实现了对应的鸭子接口。
最终达到与 client 交互时,可以直接把它当作一只鸭子。
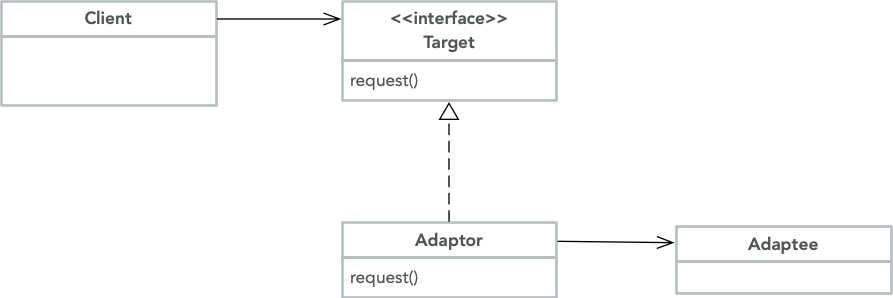
三个的区别:
最终目的:当设计一个系统时,尽可能的降低客户与系统之间的耦合
效果:
1 | Duck duck = new MallardDuck(); |
想起了公司业务代码中的 ServiceTemplate,一个道理。
⚠️注意抽象类中 brew 和 addCondiments 方法 是用斜体标示的,需要让子类实现对应细节。而抽象类统一管理统一的处理流程与子步骤,并暴露给客户代码(减少整个系统的依赖)。
迭代器模式,针对底层不同的 数组、列表、散列表等,统一为迭代器的对外接口。
状态机。最近在做一个 telegram 群组管理的机器人,对于用户状态的管理,刚好也可以用到这个设计模式:
效果:
1 | GumballMachine gumballMachine = new GumballMachine(5); |
没太懂,找了几个 proxy 模式的应用场景:
静态 proxy: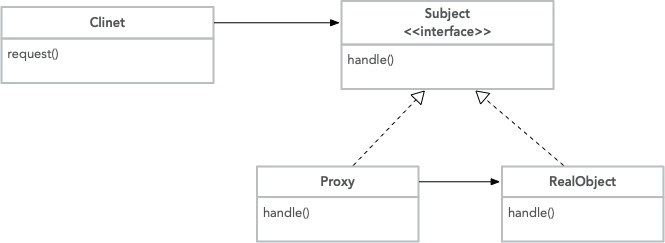
动态 proxy:
相当于将上面讲解过的设计模式复合使用,刚好跟着敲一遍代码,复习一下。
但像文中说的那样,有种牛刀杀鸡的感觉。。
]]>UML (Unified Modeling Language) is a graphical language for modeling the structure and behavior of object-oriented systems.
最近在学习经典的设计模式,竟然被类图(UML Class Diagram)深深的吸引了。总之个人一直以来,对各种「可视化」都是情有独钟(可能是老年人记忆力比较差,而图像可以在脑中快读投影与记忆)。当然正好也趁这个机会,对 uml 类图有个全面更深的理解,顺便消除之前的好几个困惑。
想起以前看过的一篇文章,说的是两种写代码的风格:有的人喜欢提前规划,将每个细节思考清晰后再动手,而另一类人则像我高中语文考试写作文,信手拈来,写到哪算哪。个人还是期望做第一类,因为代码说到底只是一种将想法落地的方式,特别是当代码复杂度远远超过我大脑内存时,一份完整详尽的系分设计文档就格外重要(包含类图/sequence/用例等),为后续理解和重构代码都有很大的好处,不然 code and fix 浪费的时间将是指数级翻倍的。当然网上也有很多反对的声音,例如 uml 无用论等🤔 你是怎么觉得的呢?或者可以等读完这篇文章后再发布你的想法。
分为三个部分,分别为 类的表示 / 继承 / 关联
不难理解三个方格分别代表:

P.S. 其中前缀分别代表:
网上针对以下两种的叫法五花八门,但如果直接叫 extend 与 implement 就比较好理解了: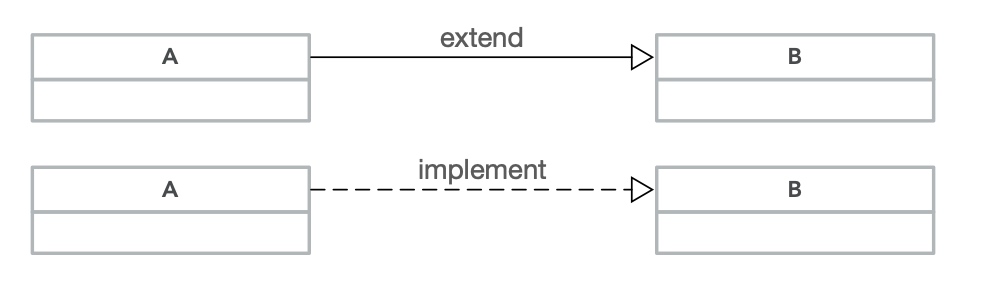
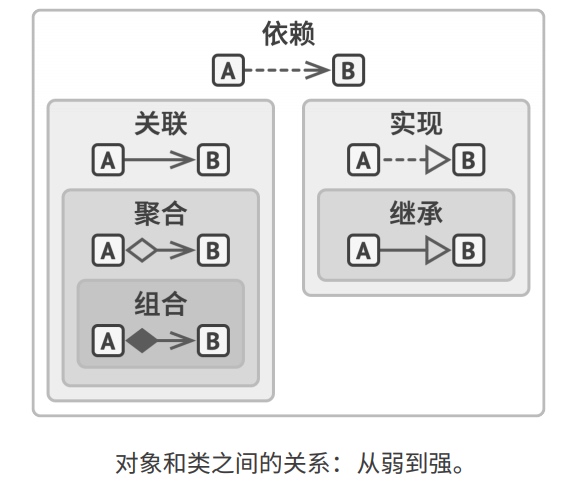
Q: composition & aggregation & association 的区别??
A: 本质上是一个包含的关系:Association > Aggregation > Composition
笑了,文中的一句话:
If you have difficulty distinguishing among association, aggregation and composition relationships, don't worry! So does everybody else!
不必过于纠结于细节和严格的标准,只要能方便理解即可,怎么舒服怎么来。不然反而与最早的愿景背道而驰了。